
Interactively Prune a Decision Tree
Prune a decision tree in seconds with a Sankey diagram.

A quick note…
2933+ people have read the three deep dives unlocked three days ago:
Model Compression: A Critical Step Towards Efficient Machine Learning → Learn how companies save 1000s of dollars in deployment costs.
You Cannot Build Large Data Projects Until You Learn Data Version Control! → Learn how ML projects are made 100% reproducible with code and data versioning.
Why Bagging is So Ridiculously Effective At Variance Reduction? → Learn the mathematical foundation of Bagging, using which, you can build your own Bagging-based models.
Must read if you want to build core ML skills in a beginner-friendly way. They will remain open for only the next 2 days.
Let’s get to today’s post now.
One thing I always appreciate about decision trees is their ease of visual interpretability.
No matter how many features our dataset has, we can ALWAYS visualize and interpret a decision tree.

This is not always possible with other intuitive and simple models like linear regression. But decision trees stand out in this respect.
Nonetheless, one thing I often find a bit time-consuming and somewhat hit-and-trial-driven is pruning a decision tree.
Why prune?
The problem is that under default conditions, decision trees ALWAYS 100% overfit the dataset, as depicted below:

Thus, pruning is ALWAYS necessary to reduce model variance.
Scikit-learn already provides a method to visualize them as shown below:
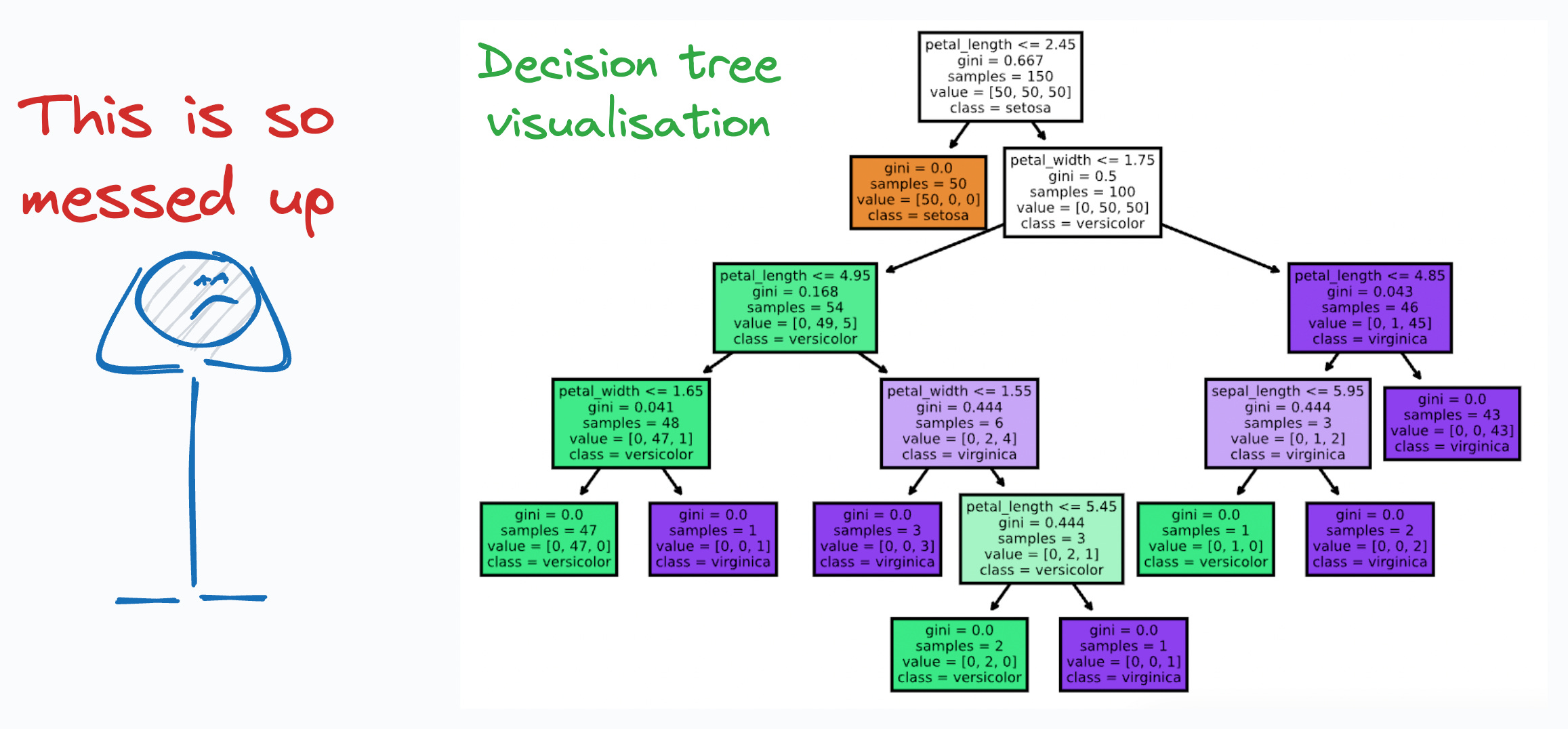
But the above visualisation is:
Pretty non-elegant, tedious, and messy.
Static (or non-interactive).
I recommend using an interactive Sankey diagram to prune decision trees.
This is depicted below:
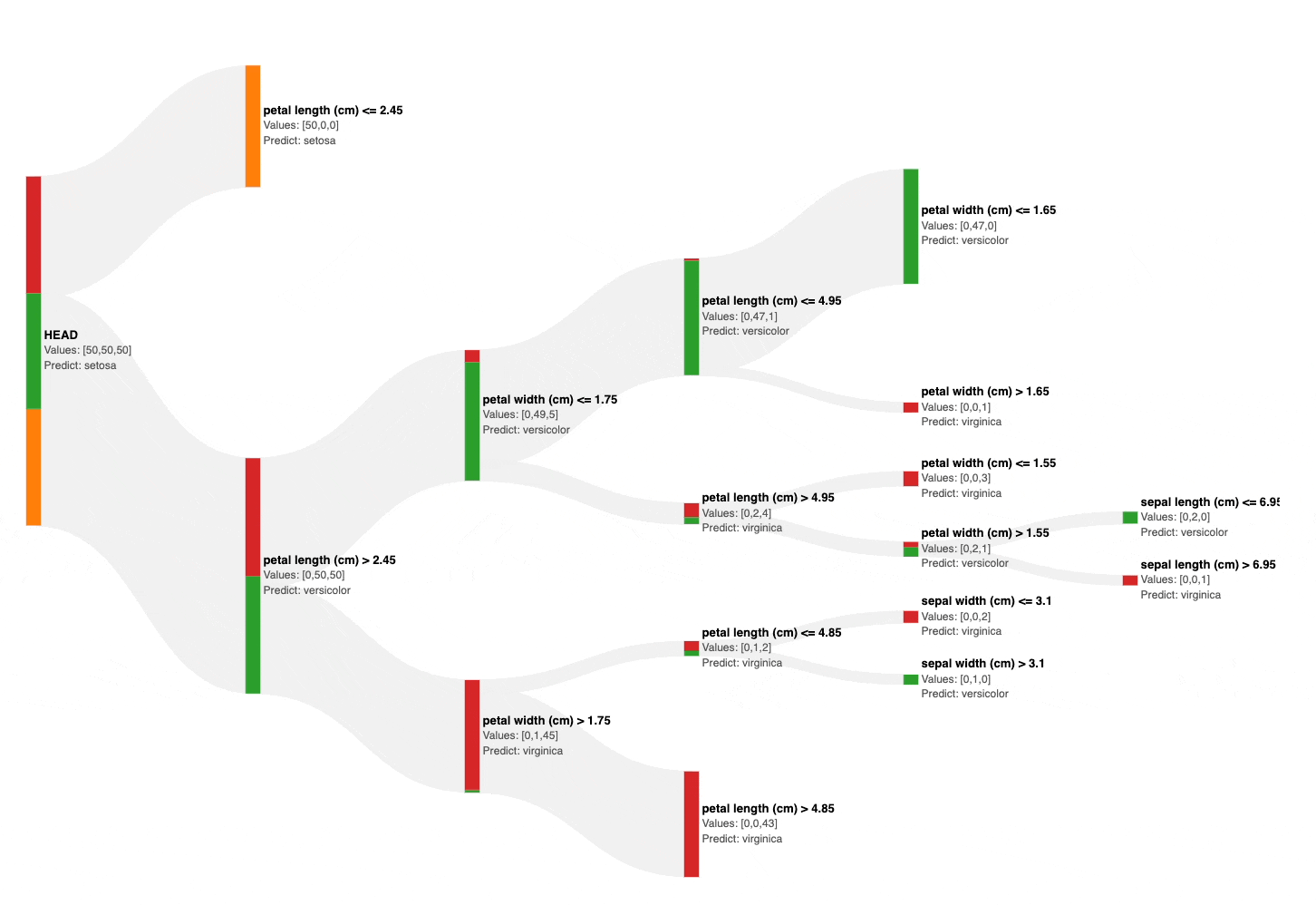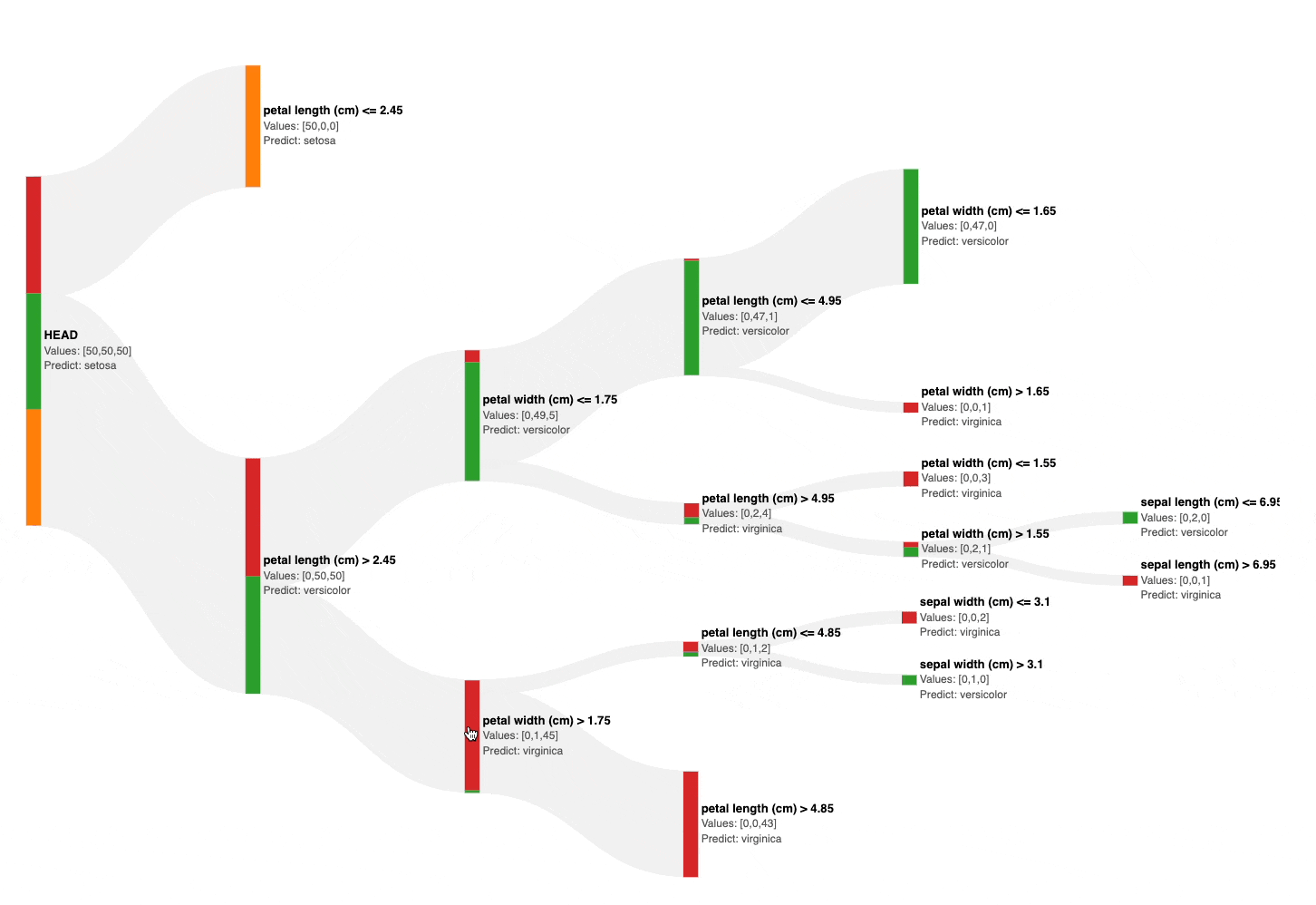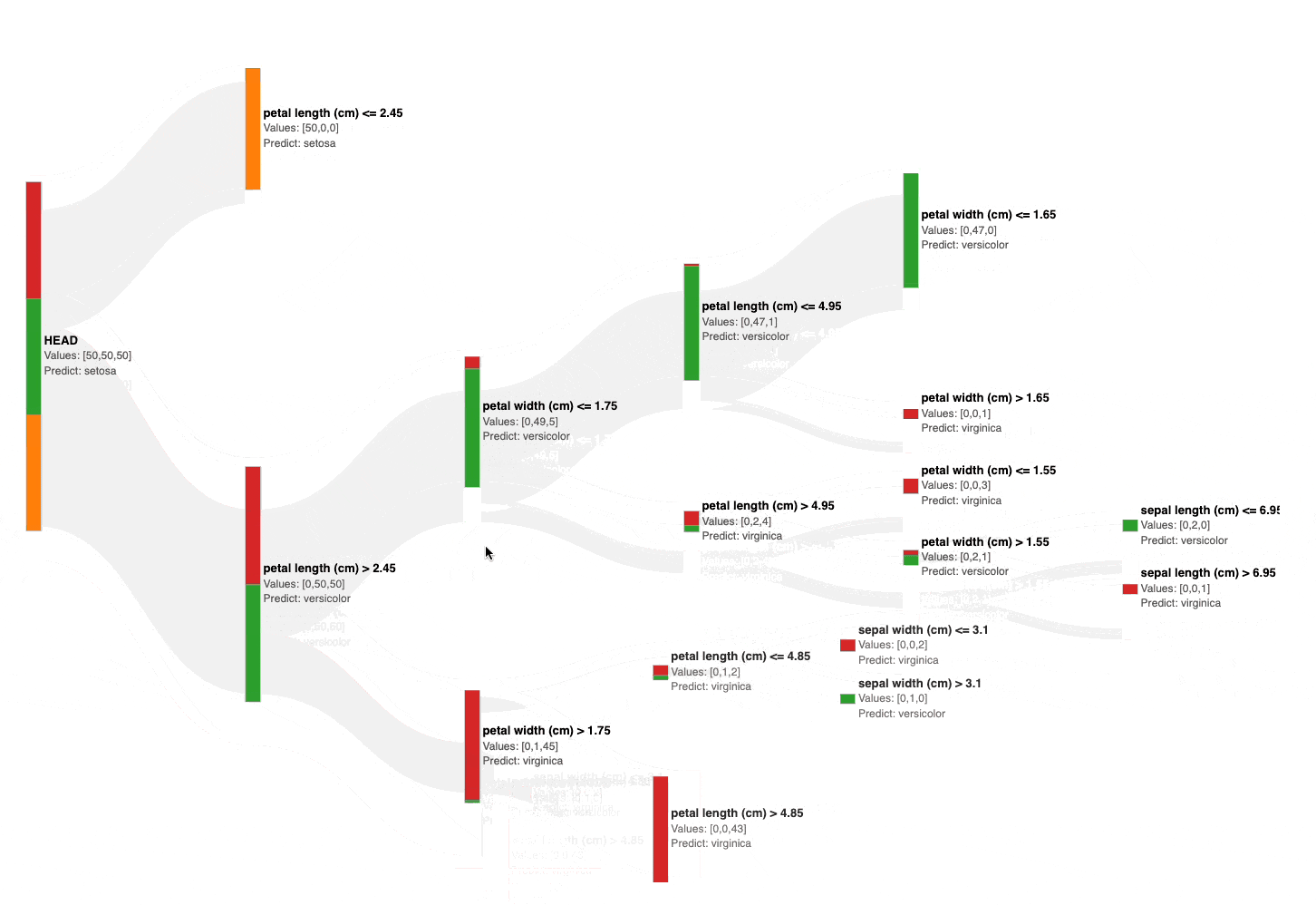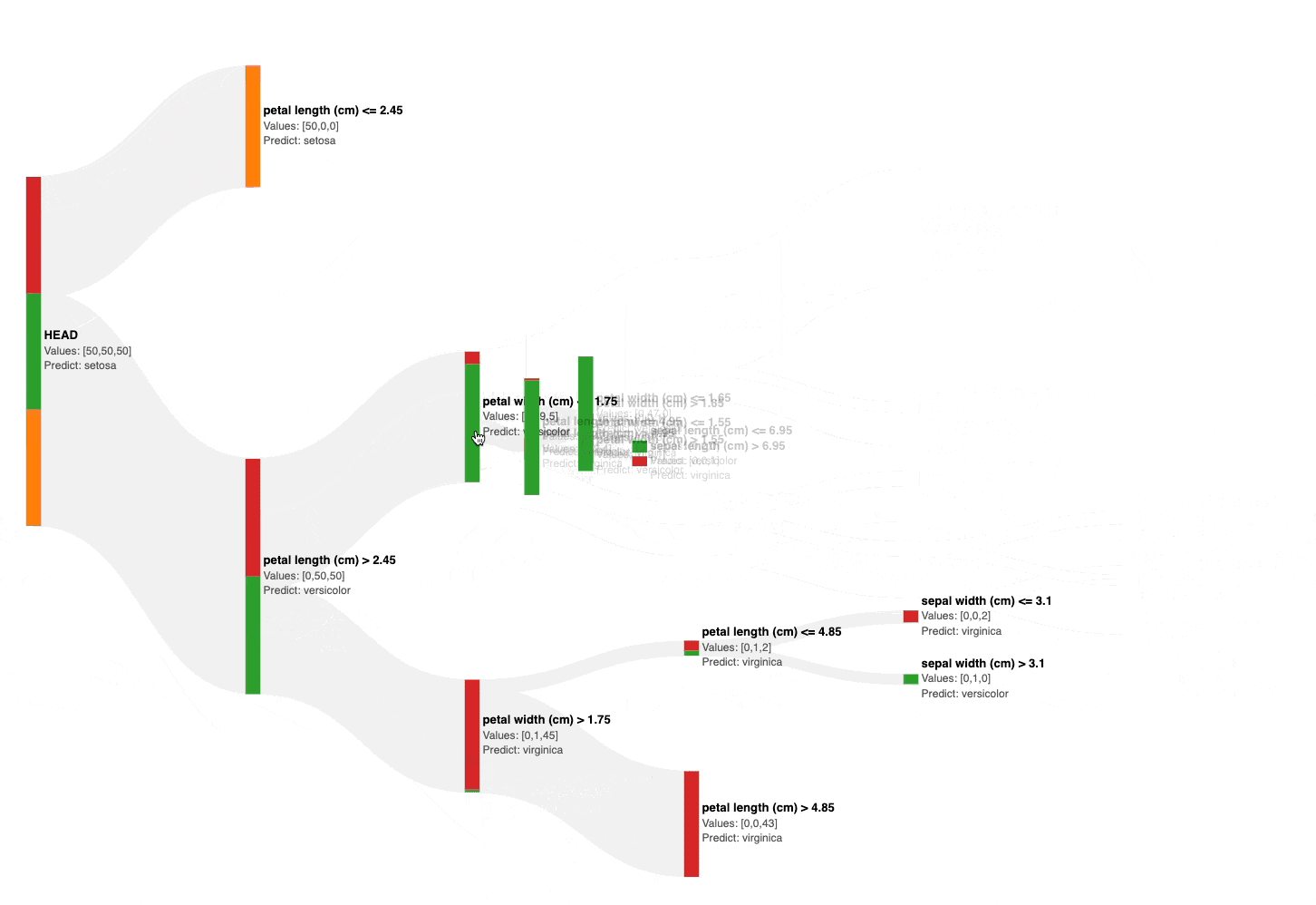
As shown above, the Sankey diagram allows us to interactively visualize and prune a decision tree by collapsing its nodes.
Also, the number of data points from each class is size and color-encoded in each node, as shown below.

This instantly gives an estimate of the node’s impurity, based on which, we can visually and interactively prune the tree in seconds.
For instance, in the full decision tree shown below, pruning the tree at a depth of two appears reasonable:
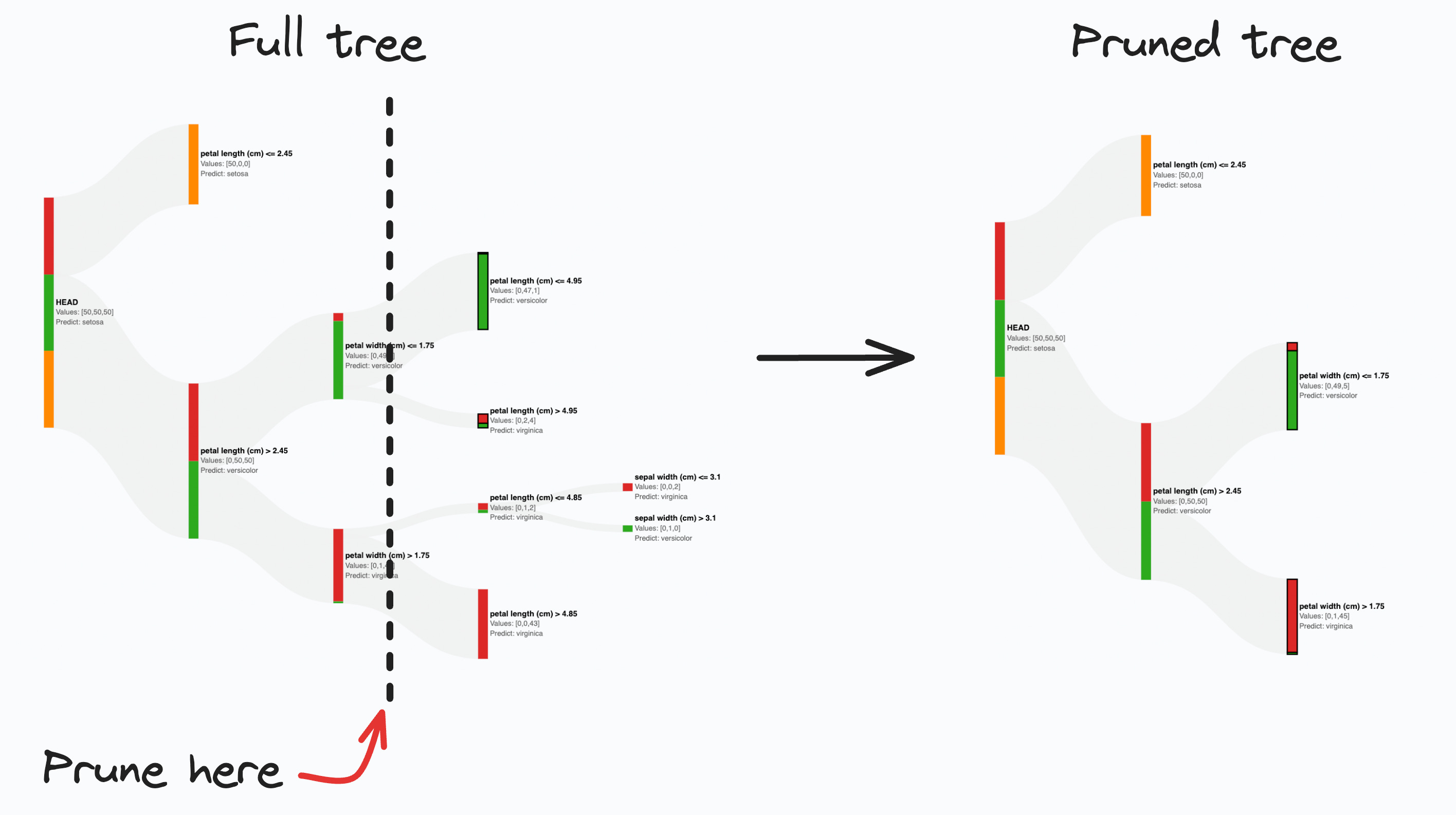
Next, we can train a new decision tree after obtaining an estimate for hyperparameter values.
This will help us reduce the variance of the decision tree.
Isn’t that cool?
You can download the code notebook for the interactive decision tree here: Interactive decision tree. Instructions are available in the notebook.
Read this next to understand a point of caution when using decision trees:
Why Decision Trees Must Be Thoroughly Inspected After Training

If we were to visualize the decision rules (the conditions evaluated at every node) of ANY decision tree, we would ALWAYS find them to be perpendicular to the feature axes, as depicted below: In other words, every decision tree progressively segregates feature space based on such perpendicular boundaries to split the data.
👉 Over to you: What are some other cool ways to prune a decision tree?
Thanks for reading!
Are you preparing for ML/DS interviews or want to upskill at your current job?
Every week, I publish in-depth ML deep dives. The topics align with the practical skills that typical ML/DS roles demand.
Join below to unlock all full articles:
Here are some of the top articles:
[FREE] A Beginner-friendly and Comprehensive Deep Dive on Vector Databases.
A Detailed and Beginner-Friendly Introduction to PyTorch Lightning: The Supercharged PyTorch
Don't Stop at Pandas and Sklearn! Get Started with Spark DataFrames and Big Data ML using PySpark.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Join below to unlock all full articles:
👉 If you love reading this newsletter, share it with friends!
👉 Tell the world what makes this newsletter special for you by leaving a review here :)