
Introduction to Deep RL and DQN
The full RL nanodegree, covered with implementation.

Google’s 5-day AI Agents intensive vibe coding course!
Google’s back with another free 5-day AI Agents course.
The last edition hit 1.5 million learners, and this time, they will dive into vibe coding with agents.
The daily progression actually mirrors how agent development works in practice:
Day 1: Agent fundamentals and vibe coding: You will go from basic chatbots to autonomous agents using natural language as the primary dev interface.
Day 2: Tool integration and multi-agent systems: You will learn how to wire agents to external APIs and get multiple agents coordinating with each other reliably.
Day 3: Context engineering: You will build agents that maintain reasoning across sessions using short-term recall, long-term memory, and persistent state.
Day 4: Evals and security: You will set up testing, guardrails, and observability to catch the failure modes that only show up when agents have real tool access.
Day 5: Prototype to production: You will deploy everything to production and build a capstone project where you ship your own agent end-to-end.
Everything runs on Kaggle notebooks with daily livestreams, taught by Google’s ML engineers.
1-2 hours a day and completely free to enroll.
Register before June 2nd here →
Thanks to Google Cloud for partnering with us today!
Introduction to Deep RL and DQN
Part 6 of the RL series is here.
The previous chapter showed that tables and even linear features hit a ceiling.
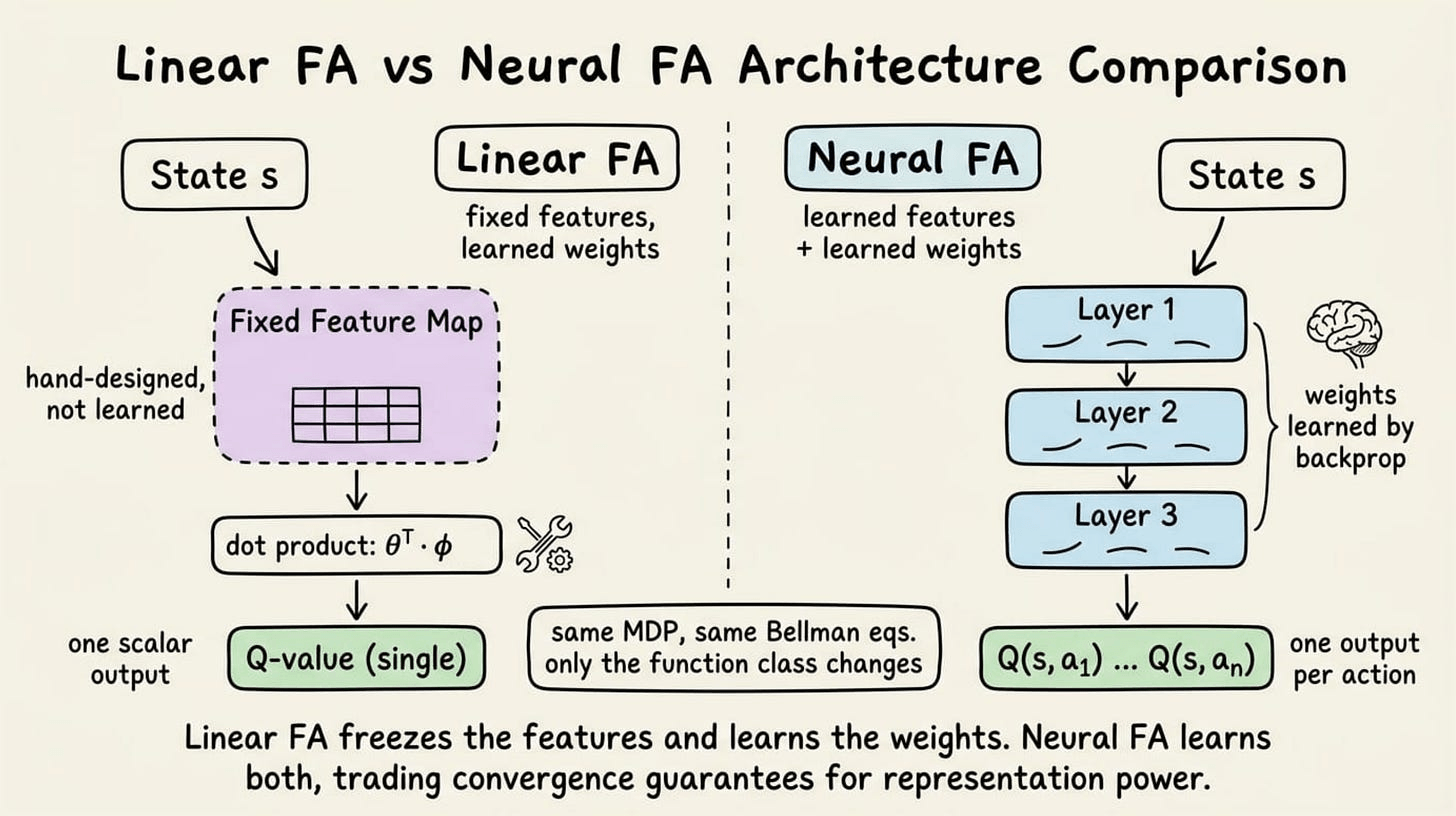
This one covers what happens when you replace them with neural networks, what breaks immediately, and the two engineering choices that made deep value-based RL actually work.
You can read Part 6 of the course here →
It covers:
The shift from linear to neural function approximation
Why naive deep Q-learning fails
How experience replay decorrelates training data
How target networks stabilize learning
The complete DQN algorithm that combines all of these
And a from-scratch PyTorch implementation trained on CartPole with training curves and analysis.
Everything is covered from scratch, so no RL background is required.
You can read Part 6 of the course here →
Why care?
Look at what has happened in the past two years.
DeepSeek-R1 used GRPO for reasoning.
ChatGPT was shaped by RLHF.
Claude uses constitutional AI with RL.
Every frontier LLM released recently has some form of reinforcement learning in its post-training pipeline.
RL is no longer a niche subfield for robotics and game-playing. It is a core component of how the most capable AI systems are built today.
Google Trends reflects this.
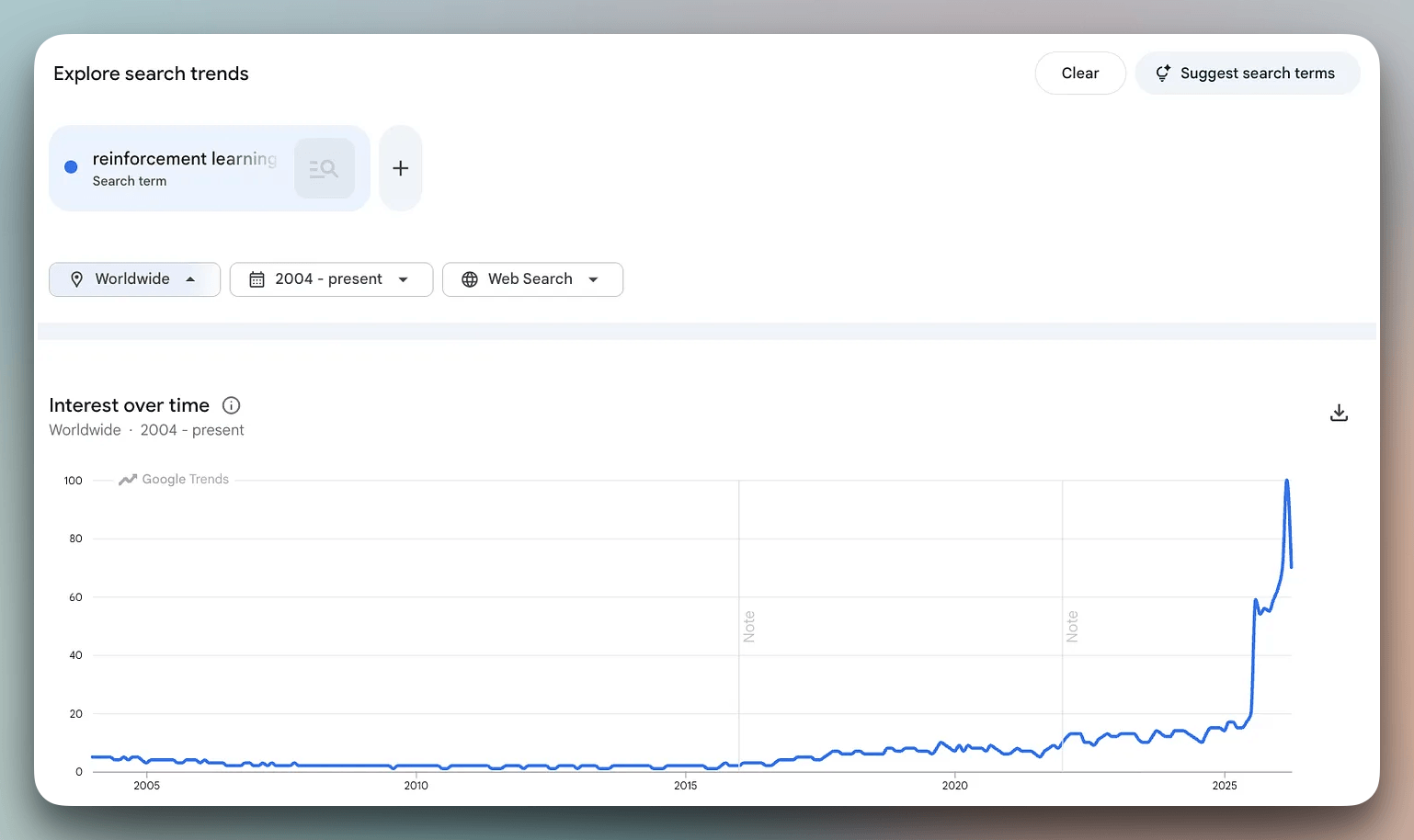
Search interest for “reinforcement learning” was nearly flat from 2004 to 2024. In the past year, it has gone vertical, hitting an all-time high.
The demand for RL expertise has followed.
If you look at ML engineering roles at labs like OpenAI, Anthropic, DeepMind, or any team working on post-training, alignment, or agentic systems, RL fluency shows up as a requirement consistently.
Understanding how reward signals shape model behavior, how policy optimization works, and how exploration interacts with credit assignment is becoming as fundamental as understanding backpropagation was five years ago.
This series is structured the same way as our MLOps/LLMOps course: concept by concept, with clear explanations, diagrams, math where it matters, and hands-on implementations you can run.
👉 Over to you: What topics would you like us to cover in this RL series?
Thanks for reading!