
Introduction to Information Environment for LLMs
The full LLMOps course (with code).

Part 7 of the full LLMOps course is now available, where we zoom out from prompt engineering to the broader discipline of context engineering, and understand the much larger information environment that drives model behavior.
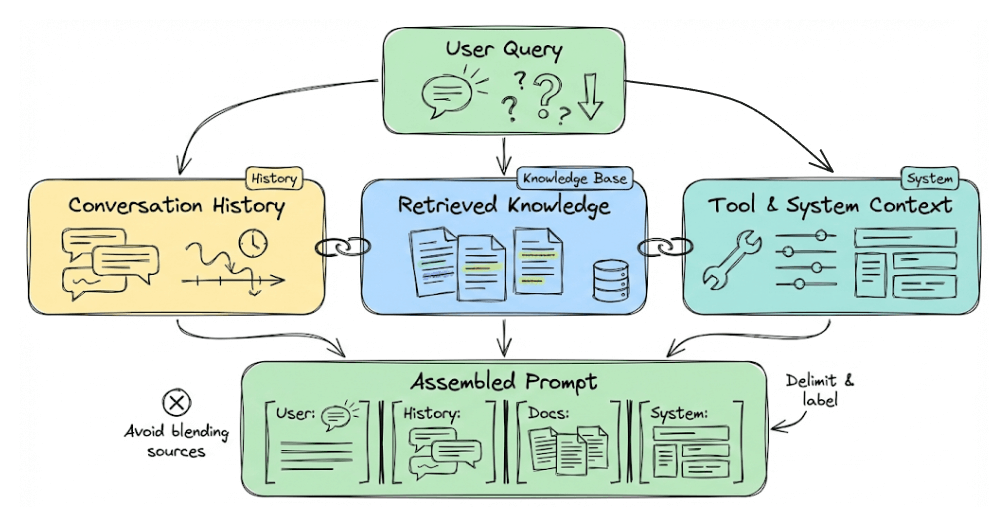
It also covers hands-on code demos to make context engineering feel concrete by showing:
Chunking, specifically semantic and code (AST-based)
Retrieval + re-ranking
Prompt compression via LLMLingua.
The AI stack has fundamentally changed.
Traditional ML was about pipelines: data processing, feature engineering, model training, and deployment. You owned every layer.
The new stack is different. The model is an API. The training is prompting and fine-tuning. The evaluation has no ground truth. The costs scale with usage, not computation.
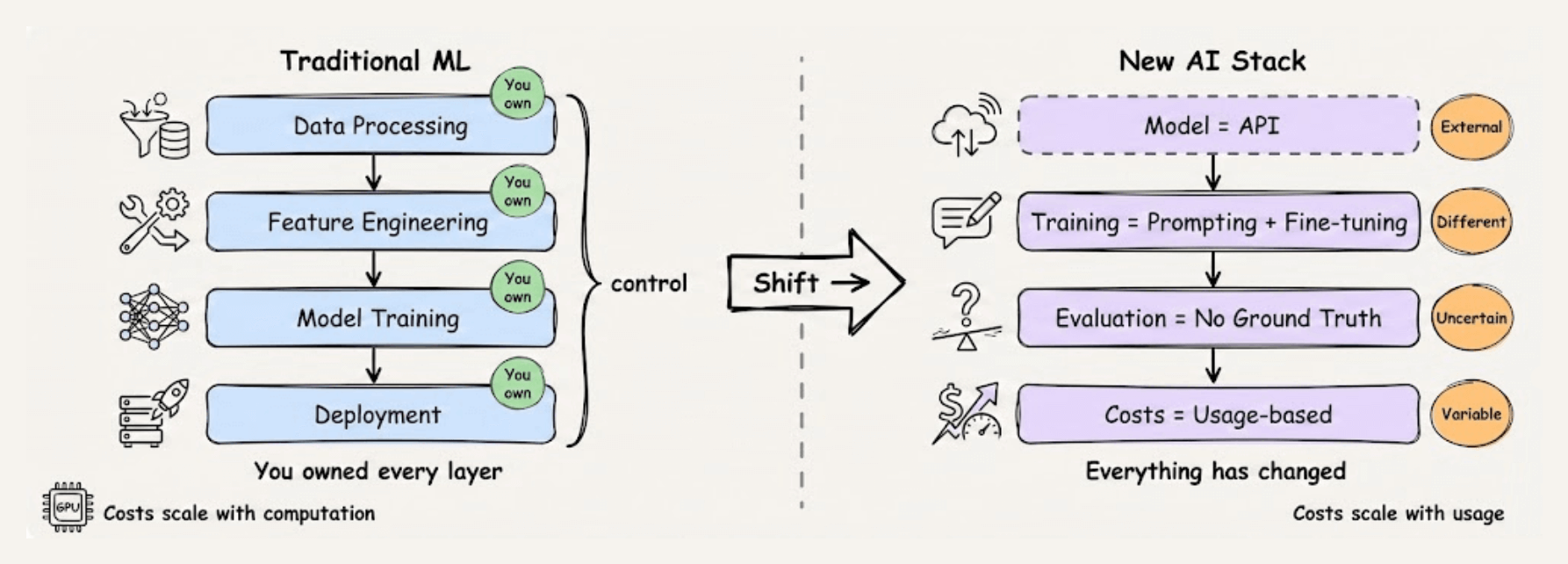
LLMOps is the discipline for this new stack.
This course helps you build a production mindset and intuition for how these systems actually work in production and what it takes to make them reliable, cost-effective, and maintainable.
Each chapter breaks down the concepts you need, backs them with clear examples and diagrams, and gives you hands-on implementations you can actually use.
More importantly, it develops the critical thinking to navigate decisions that have no single right answer, because in LLM systems, the tradeoffs are constant and the playbook is still being written.
Just like the MLOps course, each chapter will clearly explain necessary concepts, provide examples, diagrams, and implementations.
As we progress, we will see how we can develop the critical thinking required for taking our applications to the next stage and what exactly the framework should be for that.
👉 Over to you: What would you like to learn in the LLMOps course?
Thanks for reading!