
Is Data Normalization Always Necessary Before Training ML Models?
If not, when is it not needed?


Data normalization is commonly used to improve the performance and stability of ML models.
This is because normalization scales the data to a standard range. This prevents a specific feature from having a strong influence on the model’s output. What’s more, it ensures that the model is more robust to variations in the data.
For instance, in the image above, the scale of Income could massively impact the overall prediction. Normalizing the data by scaling both features to the same range can mitigate this and improve the model’s performance.
But is it always necessary?
While normalizing data is crucial in many cases, knowing when to do it is also equally important.
The following visual depicts which algorithms typically need normalized data and which don’t.
As shown above, many algorithms typically do not need normalized data. These include decision trees, random forests, naive bayes, gradient boosting, and more.
Consider a decision tree, for instance. It splits the data based on thresholds determined solely by the feature values, regardless of their scale.
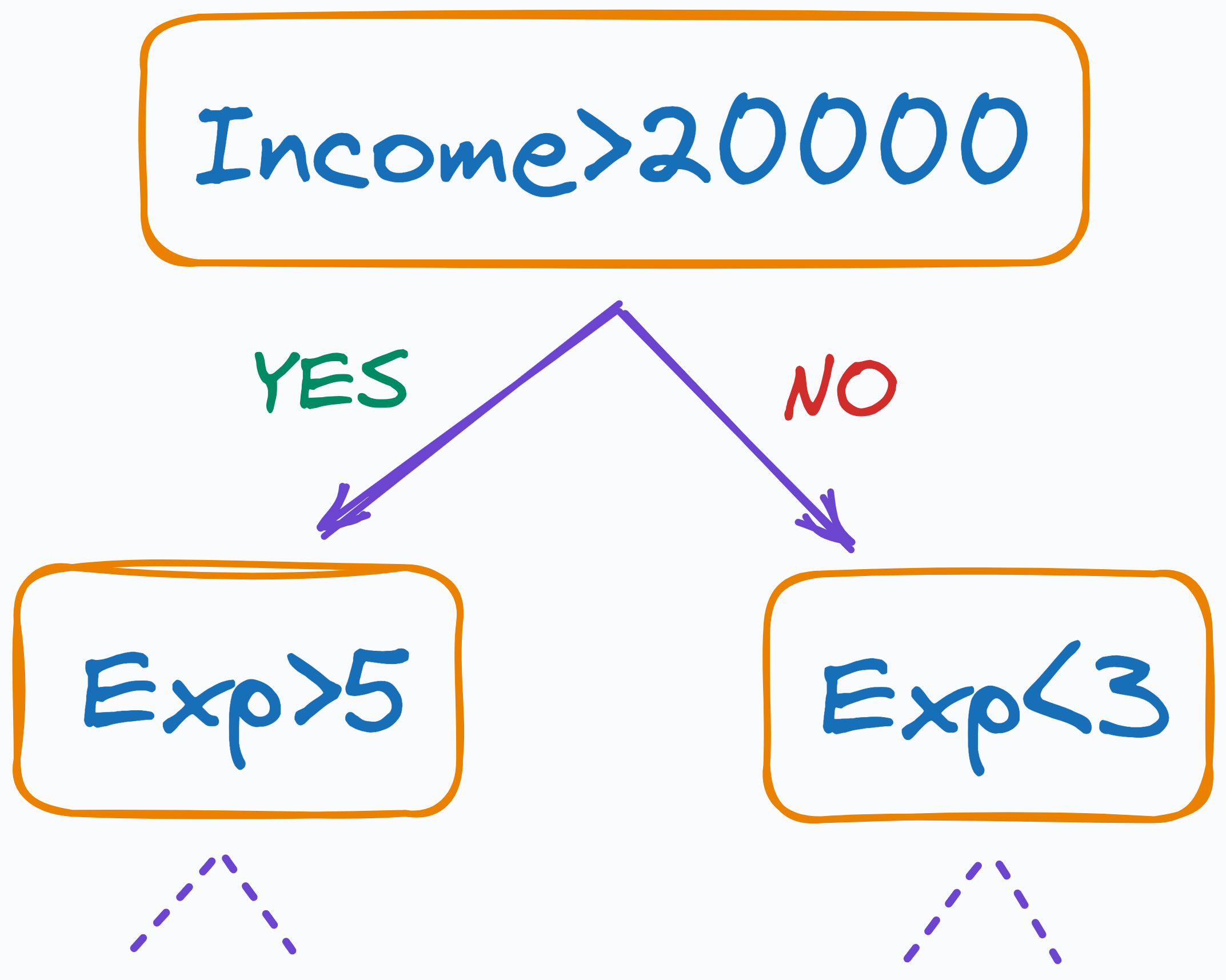
Thus, it’s important to understand the nature of your data and the algorithm you intend to use.
You may never need data normalization if the algorithm is insensitive to the scale of the data.
Over to you: What other algorithms typically work well without normalizing data? Let me know :)
👉 Read what others are saying about this post on LinkedIn and Twitter.
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
👉 If you love reading this newsletter, feel free to share it with friends!
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.