
Karpathy’s Prediction About RL is Coming True Now!
..and an open-source framework that's making it happen.

A lesson from running AI in production
In 2023, AI products were thin wrappers. The LLM call was the entire workload, so cheaper models meant cheaper bills.
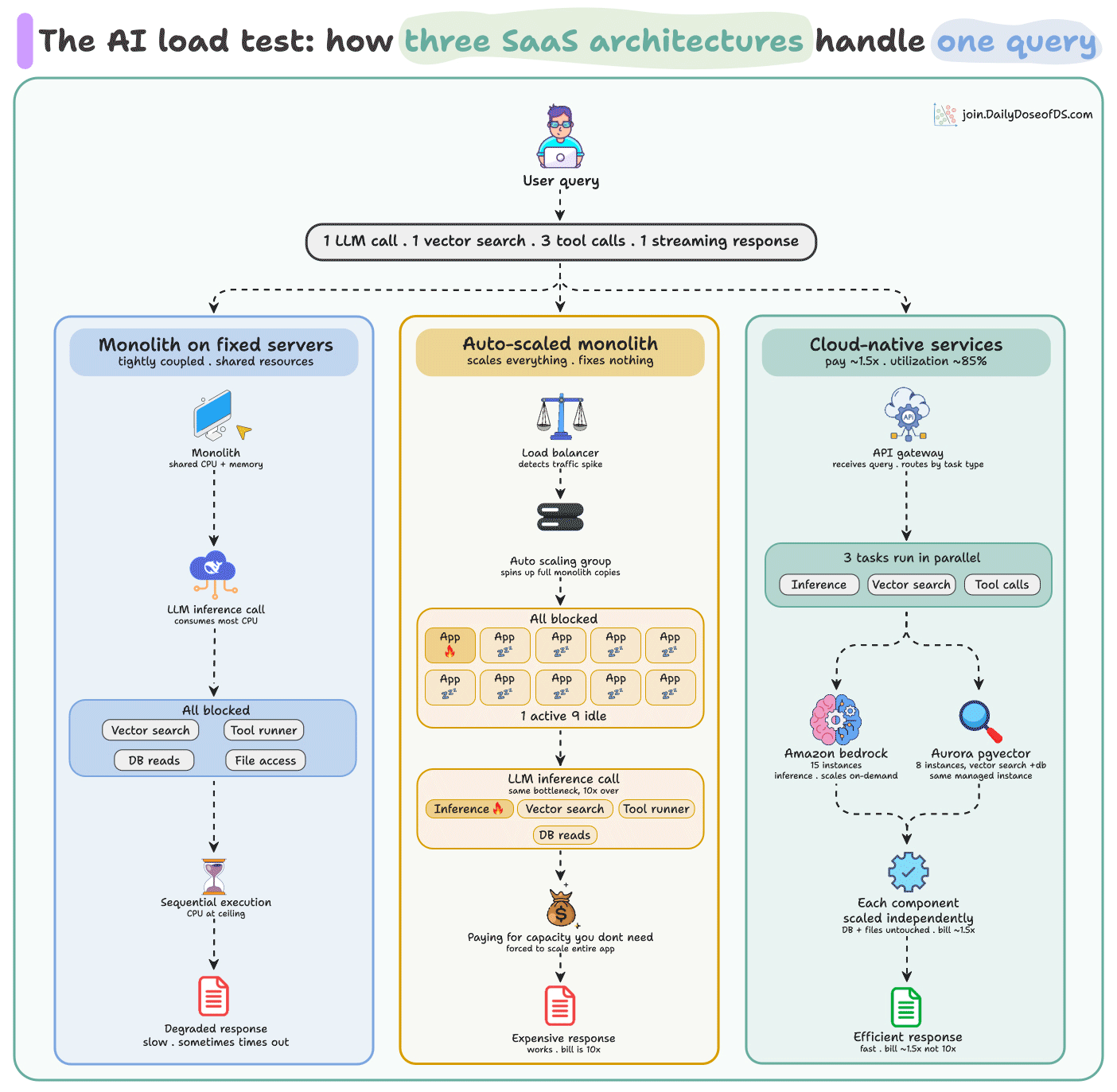
That’s not what AI queries look like today.
A single request can trigger a vector DB, web search, tools, and multiple LLM inferences before streaming a response back. The model got cheaper, but the infrastructure serving each query got heavier.
And when all of that runs inside a single deployable unit, auto-scaling makes it worse.
A spike in inference forces the entire app to scale, even when every other component is idle. The bill lands at 10x for a single-component problem.
AWS’ managed services decompose this by running each layer independently. Inference on Bedrock, vector search on Aurora pgvector, orchestration on EKS, each scaling on its own load curve.
Innovaccer runs this pattern for a healthcare AI platform serving 54M patients. After decomposing, they achieved 33% lower cloud costs and 65% less management overhead.
You can explore AWS’s resources for building AI-native SaaS here →
Thanks to AWS for partnering today!
Karpathy’s prediction about RL is coming true now!
Karpathy called reward functions unreliable and argued that a single reward number is too low-dimensional to teach an agent what “good” means for complex tasks.
To solve this, Agents need a knowledge-guided review as a higher-dimensional feedback channel.
Every major AI lab trains models with RL today (OpenAI, Anthropic, DeepSeek).
And their key bottleneck has always been the reward functions.
GRPO by DeepSeek worked well for math and code because the environment gave a binary signal.
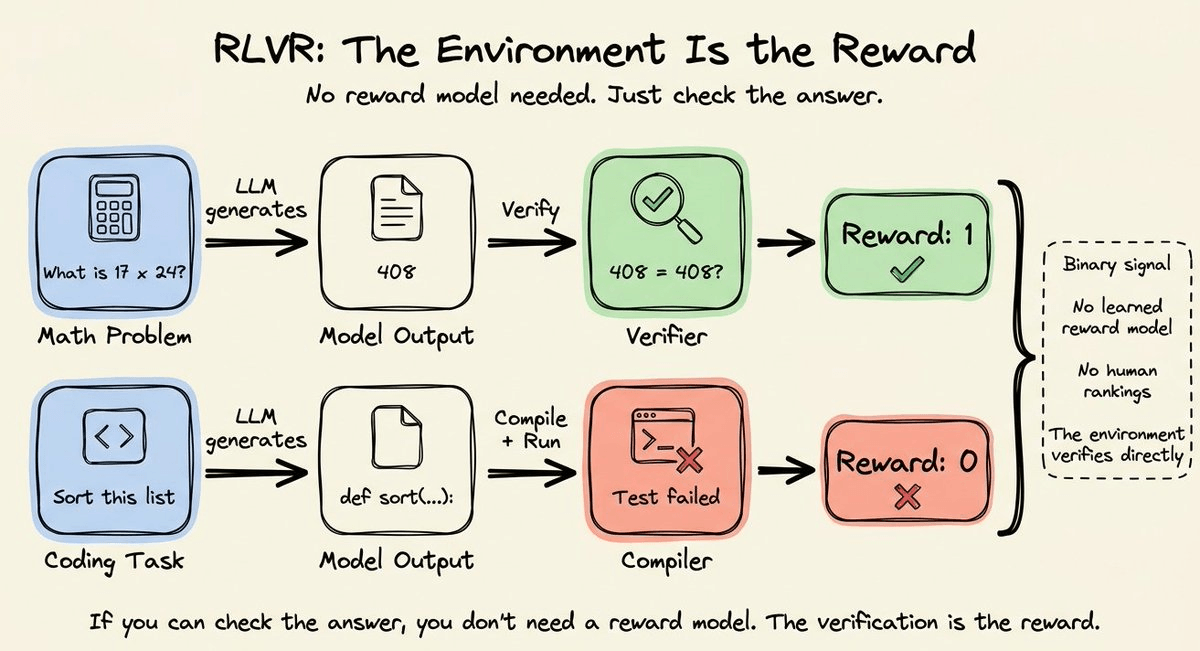
But for real agent tasks, someone still has to hand-code the scoring function. That takes days and breaks every time the pipeline changes.
RULER (implemented in OpenPipe ART, 10k stars) addresses the exact problem Karpathy identified.
The reward criteria are defined in plain English, and an LLM evaluates each trajectory against that description to provide feedback for training.
We trained a Qwen3 1.4B agent that plays 2048 using GRPO with this exact workflow.
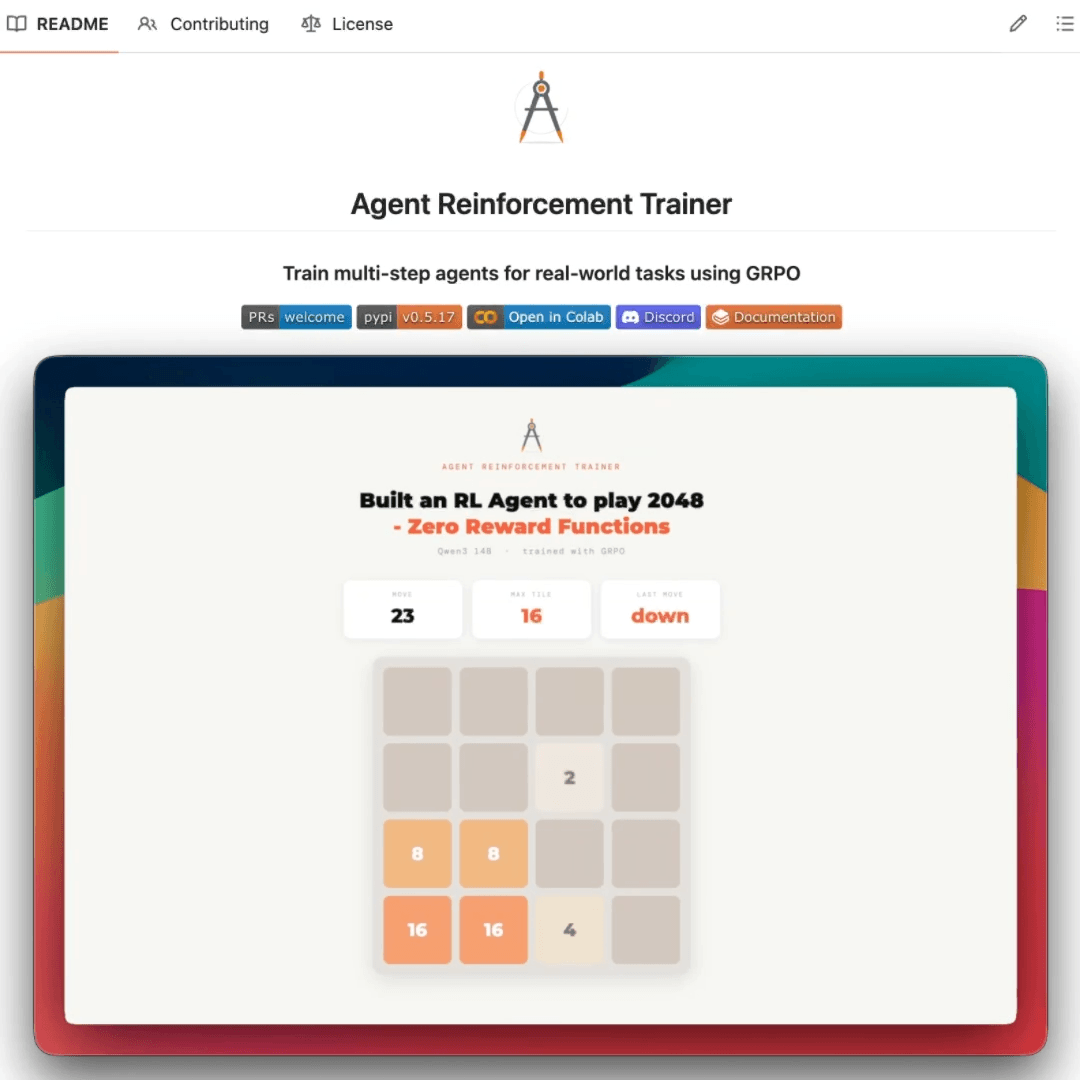
In this case, the agent saw the board, picked a direction, and RULER evaluated the outcome, all from this natural language definition.
You can see the full implementation on GitHub and try it yourself.
Here’s the ART Repo → (don’t forget to star it ⭐ )
Just like RLHF replaced manual rankings and GRPO replaced the critic model, natural language rewards are replacing hand-coded scoring functions.
RL reward engineering is now prompt engineering.
We also wrote a full walkthrough covering RL for LLM agents, from RLHF to GRPO to RULER. You can read it here →
Thanks for reading!