
KernelPCA vs. PCA for Dimensionality Reduction
...explained with visuals.

Interact with your MongoDB Databases and Atlas Clusters via MCP!

MongoDB’s MCP Server lets AI tools like Claude, Cursor, and GitHub Copilot talk directly to any MongoDB deployment.
That means anyone (technical or non-technical) can now say:
“Show me the most active users”
“Create a new database user with read-only access”
“What’s the schema for my orders collection?”
...and let the Agent handle the rest.
This MCP server works across:
Atlas
Community Edition
Enterprise Advanced
Natural language is all you need now to write production-grade queries.
100% open-source!
Here is the GitHub repo → (don’t forget to star it)
Thanks to the MongoDB team for partnering today!
KernelPCA vs. PCA for Dimensionality Reduction
During dimensionality reduction, PCA finds a low-dimensional linear subspace that the given data conforms to.
For instance, consider this dummy dataset:

It’s clear that there is a linear subspace along which the data could be represented while retaining maximum data variance. This is shown below:

But what if our data conforms to a low-dimensional yet non-linear subspace?
For instance, consider this dataset:

The low-dimensional non-linear subspace that this specific data could be represented along is depicted below:
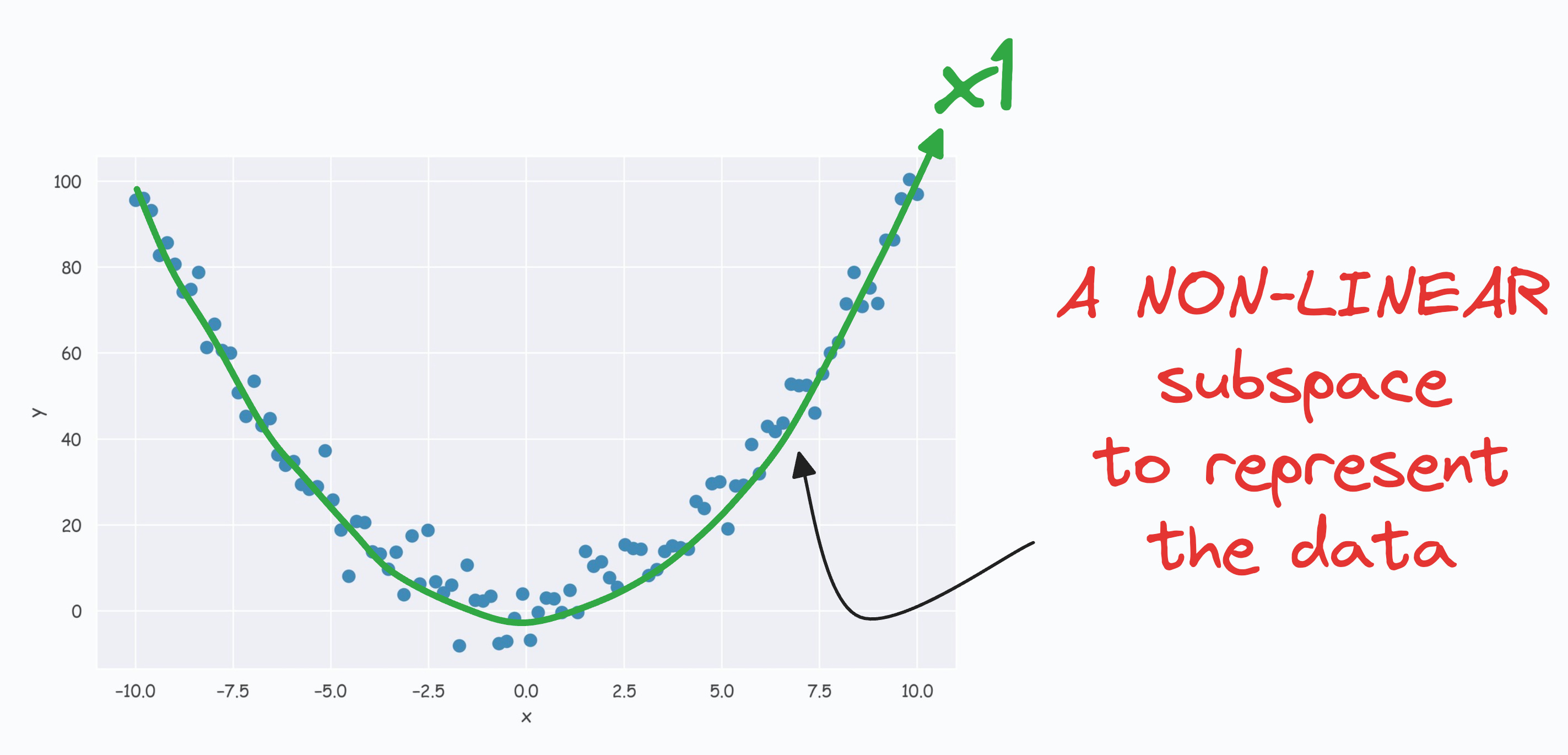
The above curve is a continuous non-linear and low-dimensional subspace that we could represent our data given along.
But the problem is that PCA cannot determine this subspace because the data points are not aligned along a straight line.
KernelPCA (or the kernel trick) precisely addresses this limitation of PCA.
The idea is pretty simple.
In standard PCA, we compute the eigenvectors and eigenvalues of the standard covariance matrix (we covered the mathematics here).
In KernelPCA, however:
We first use a kernel function to compute the pairwise high-dimensional dot product between two data points, X and Y, without explicitly projecting the vectors to that space.
This produces a kernel matrix.
Next, perform eigendecomposition on this kernel matrix instead and select the top “
p” components.Done!
If there’s any confusion in the above steps, I would highly recommend reading this deep dive on PCA, where we formulated the entire PCA algorithm from scratch. It will help you understand the underlying mathematics.
The efficacy of KernelPCA over PCA is evident from the demo below.
As shown below, even though the data is non-linear, PCA still produces a linear subspace for projection:

However, KernelPCA produces a non-linear subspace:
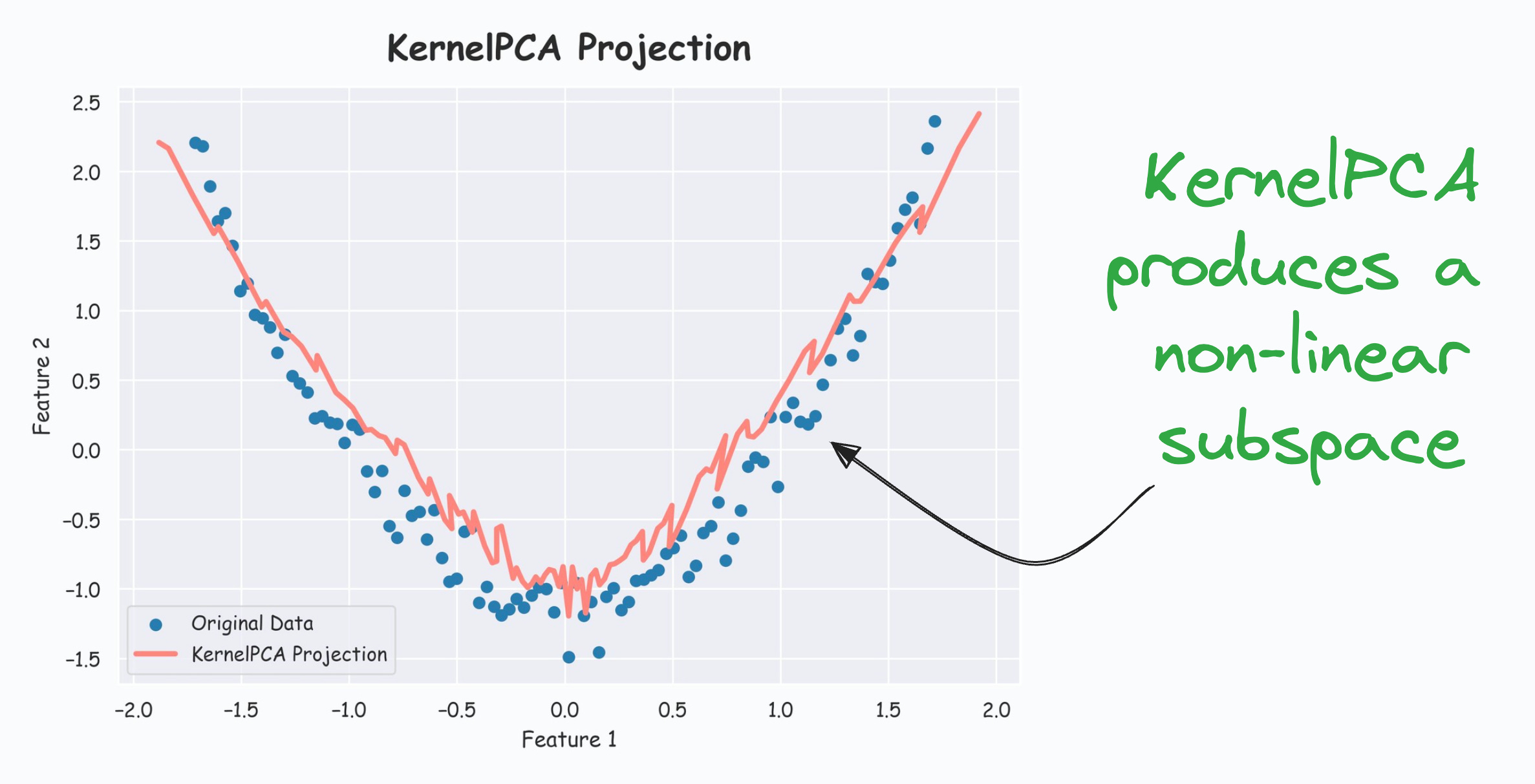
Of course, there’s a catch, which is the run time.
Since we compute the pairwise dot products in KernelPCA, this adds an additional O(n^2) time-complexity.
Thus, it increases the overall run time. This is something to be aware of when using KernelPCA.
If you want to dive into the clever mathematics of the kernel trick and why it is called a “trick,” we covered this in the newsletter here:
👉 Over to you: What are some other limitations of PCA?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.