
KMeans vs. Gaussian Mixture Models
Addressing the major limitation of KMeans.

I like to think of Gaussian Mixture Models as a more generalized version of KMeans.
While we have covered all the necessary conceptual and practical details here: Gaussian Mixture Models…
…let me tell you some of the widely known limitations of KMeans that you might not be aware of.
Limitations of KMeans
To begin:
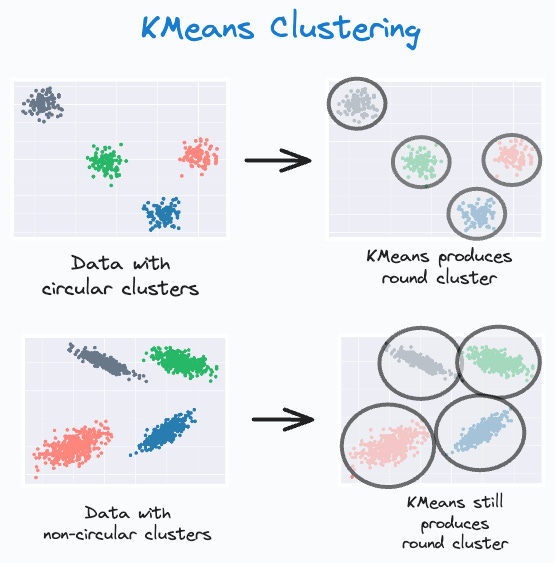
It can only produce globular clusters. For instance, as shown below, even if the data has non-circular clusters, it still produces round clusters.
It performs a hard assignment. There are no probabilistic estimates of each data point belonging to each cluster.

It only relies on distance-based measures to assign data points to clusters.
To understand better, consider two clusters in 2D — A and B. Cluster A has a higher spread than B.

Now consider a line that is mid-way between centroids of A and B.
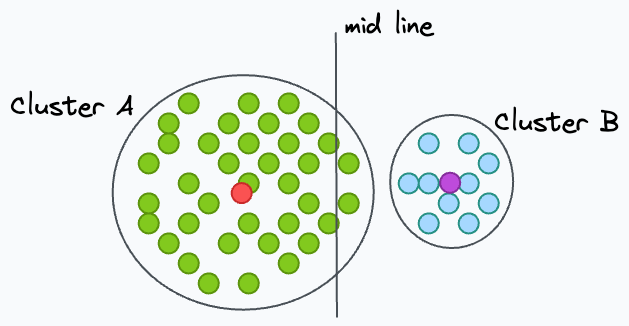
Although A has a higher spread, even if a point is slightly right to the midline, it will get assigned to cluster B.
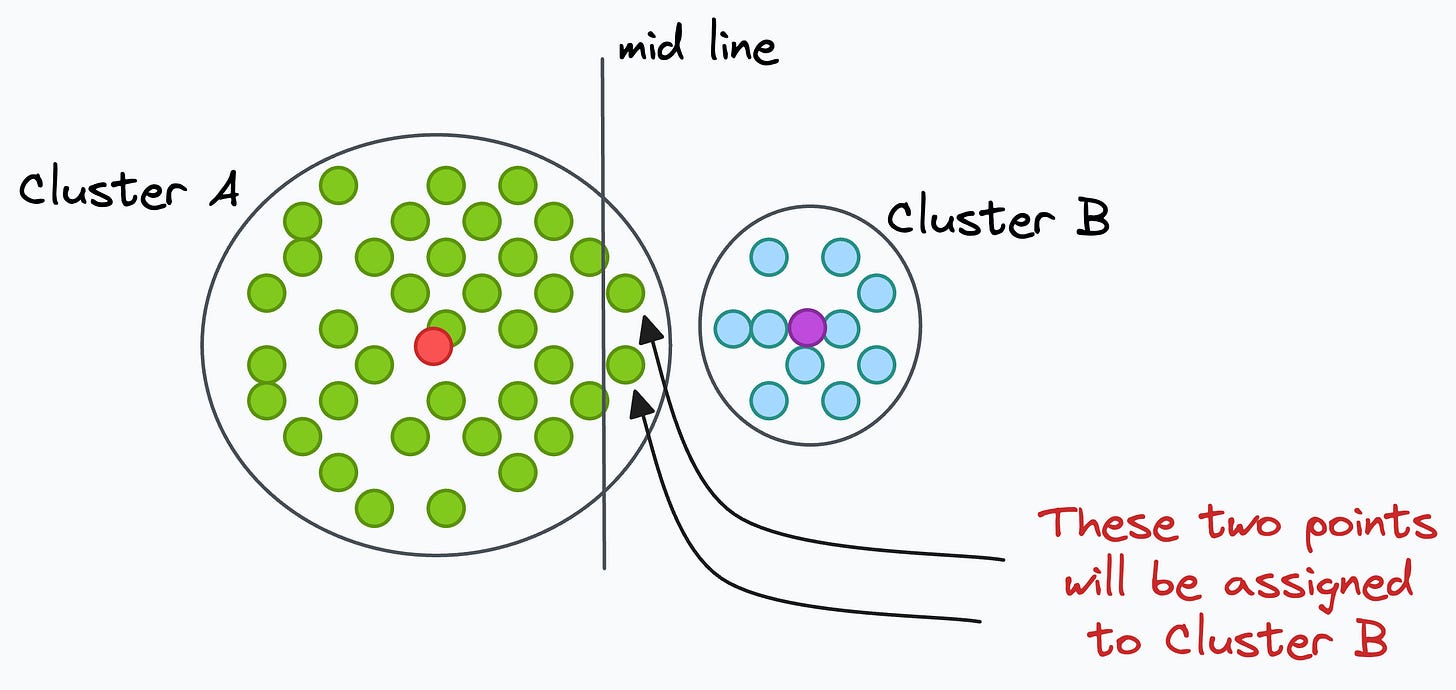
Ideally, however, cluster A should have had a larger area of influence.



Gaussian Mixture Models
These limitations often make KMeans a non-ideal choice for clustering.
Gaussian Mixture Models are often a superior algorithm in this respect.
As the name suggests, they can cluster a dataset that has a mixture of many Gaussian distributions.
They can be thought of as a more flexible twin of KMeans.
The primary difference is that:
KMeans learns centroids.
Gaussian mixture models learn a distribution.
For instance, in 2 dimensions:

KMeans can only create circular clusters
GMM can create oval-shaped clusters.
This is illustrated in the animation below:

The effectiveness of GMMs over KMeans is evident from the image below.
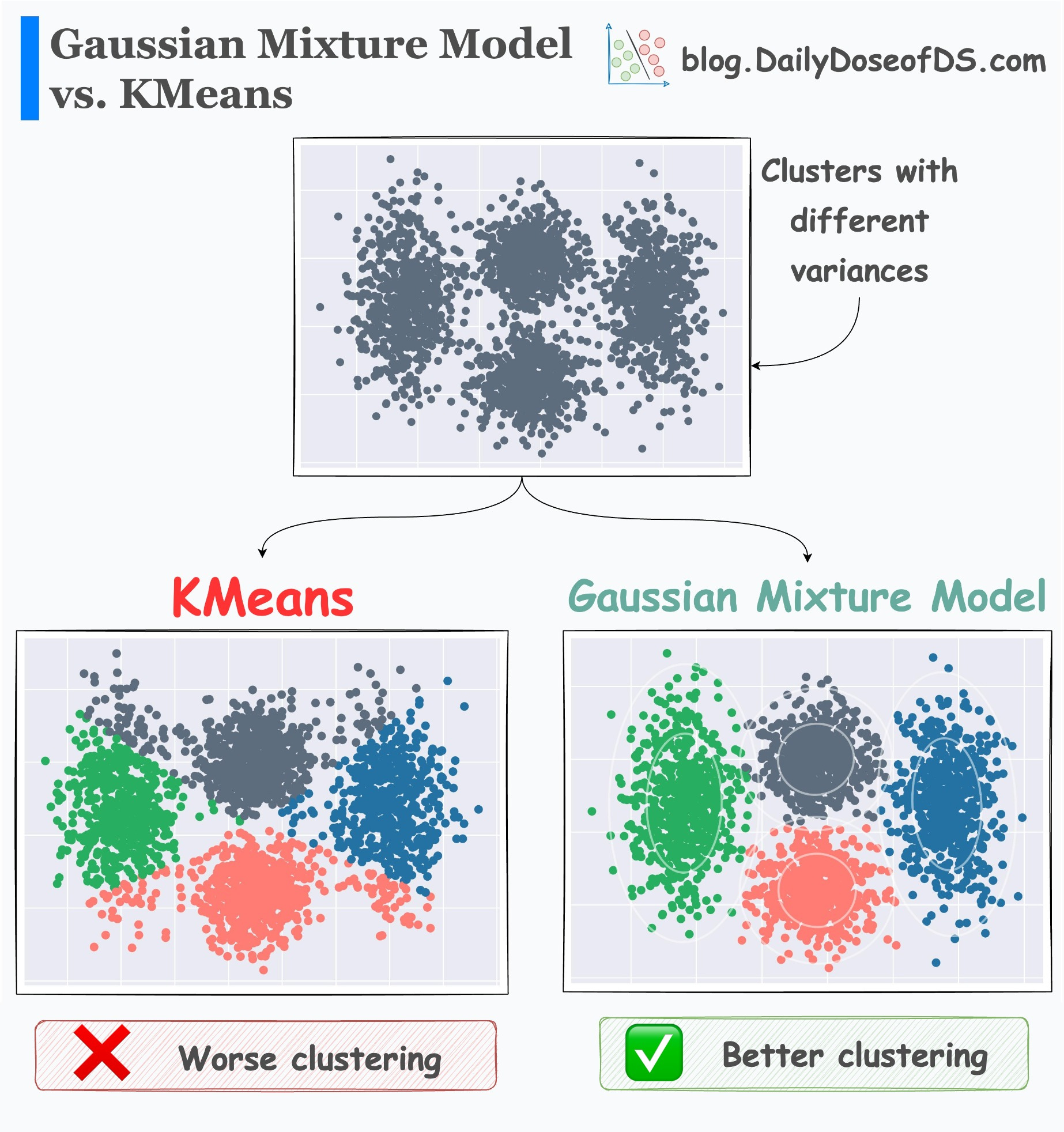
KMeans just relies on distance and ignores the distribution of each cluster.
GMM learns the distribution and produces better clustering.
If you want to get into more details, I covered them in-depth here: Gaussian Mixture Models.
It covers:
What is the motivation and intuition behind GMMs?
The end-to-end mathematical formulation of GMMs.
How to use Expectation-Maximization to model data using GMMs?
Coding a GMM from scratch (no sklearn).
Comparing results of GMMs with KMeans.
How to determine the optimal number of clusters for GMMs?
Some practical use cases of GMMs.
Takeaways.
👉 Over to you: What are some other shortcomings of KMeans?
Thanks for reading!
Whenever you are ready, here’s one more way I can help you:
Every week, I publish 1-2 in-depth deep dives (typically 20+ mins long). Here are some of the latest ones that you will surely like:
[FREE] A Beginner-friendly and Comprehensive Deep Dive on Vector Databases.
A Detailed and Beginner-Friendly Introduction to PyTorch Lightning: The Supercharged PyTorch
You Are Probably Building Inconsistent Classification Models Without Even Realizing
Why Sklearn’s Logistic Regression Has no Learning Rate Hyperparameter?
PyTorch Models Are Not Deployment-Friendly! Supercharge Them With TorchScript.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
You Cannot Build Large Data Projects Until You Learn Data Version Control!
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 If you love reading this newsletter, feel free to share it with friends!
👉 Tell the world what makes this newsletter special for you by leaving a review here :)