
KMeans vs. Gaussian Mixture Models
Addressing some limitations of KMeans.

[REMINDER] Update to Daily Dose of Data Science
We have started moving from Substack (our current newsletter platform) to another platform.
Switch for free here: https://switch.dailydoseofds.com.
Right away, you will receive an email with some instructions.
Done!

We urge you to take a minute and join below:
KMeans vs. Gaussian Mixture Models
I like to think of Gaussian Mixture Models as a generalized version of KMeans.
Today, let’s understand some common limitations of KMeans and how Gaussian Mixture Models address them.
To begin, KMeans only considers a globular symmetry in cluster shapes:
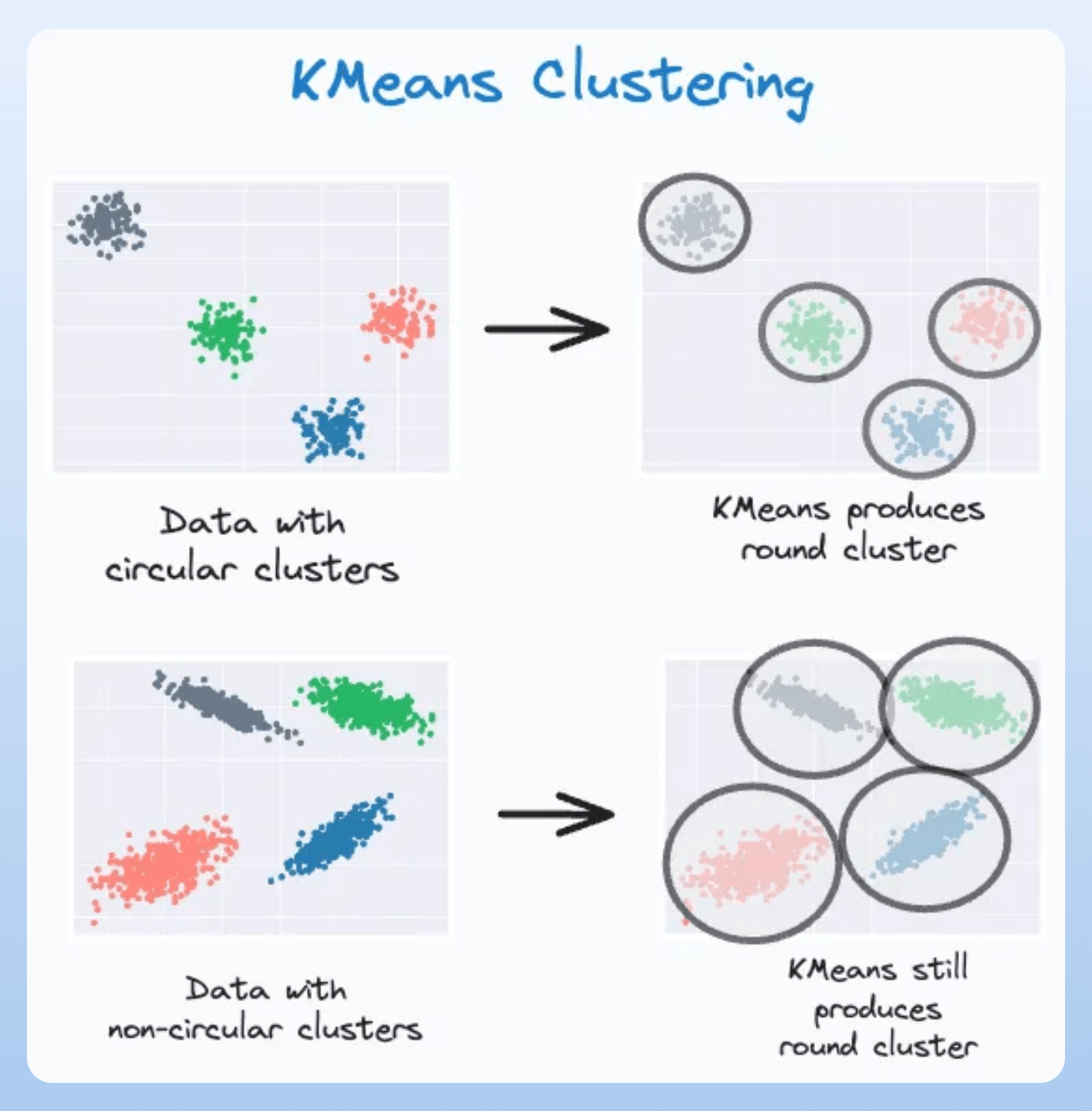
Next, KMeans only performs a hard assignment. There are no probabilistic estimates of each data point belonging to each cluster.
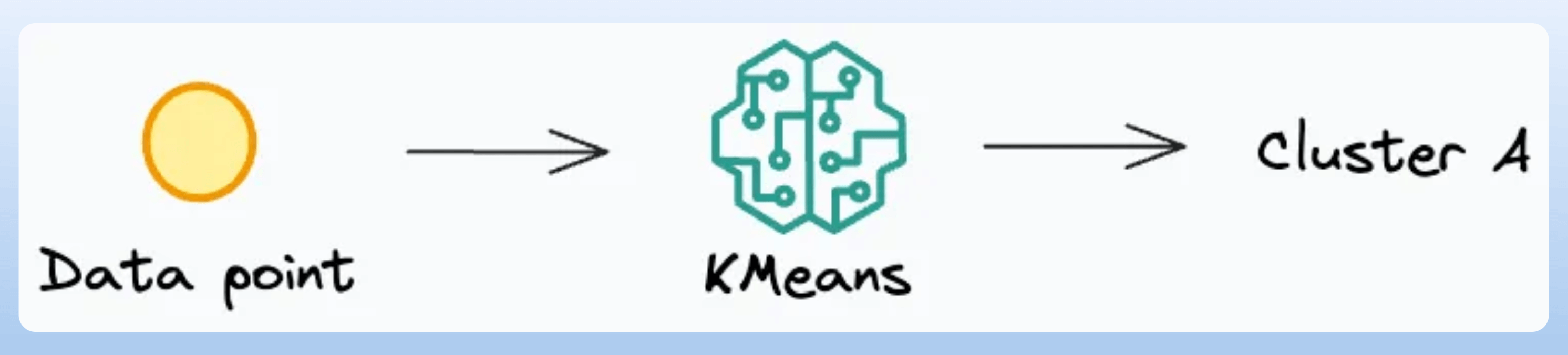
Lastly, KMeans only relies on a distance-driven metric to assign data points to clusters.
To understand this, consider two clusters in 2D—A and B, where Cluster A has a higher spread than B, and there’s a line mid-way between their centroids:
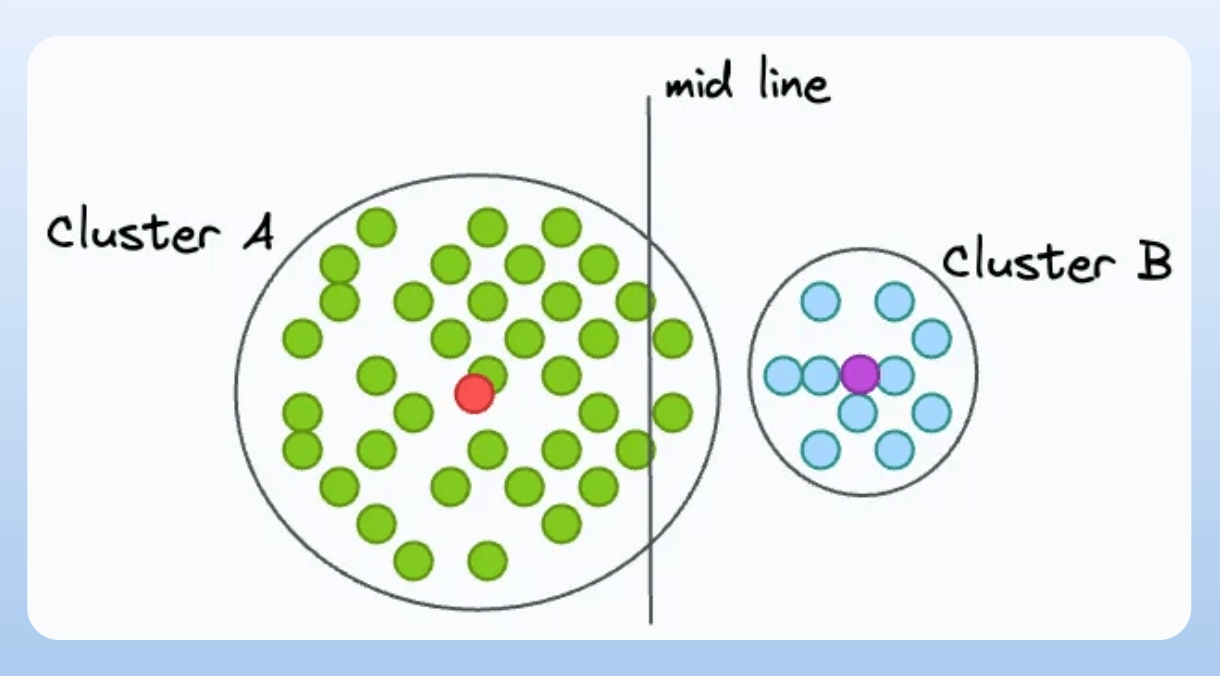
Although A has a higher spread, even if a point is slightly right to the midline, it will get assigned to cluster B:
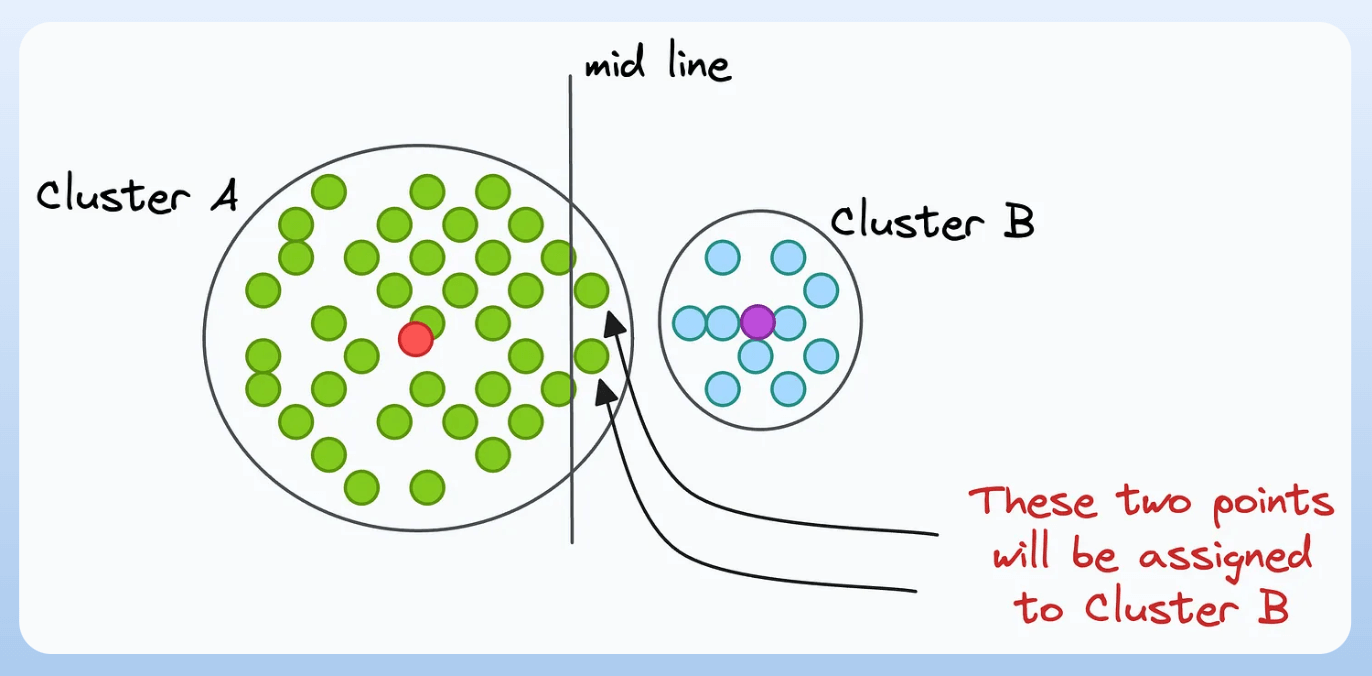
Gaussian Mixture Models address these limitations since they cluster a dataset that has a mixture of many Gaussian distributions.
The primary difference is that:
KMeans learns centroids.
Gaussian mixture models learn a distribution.
For instance, in 2 dimensions:
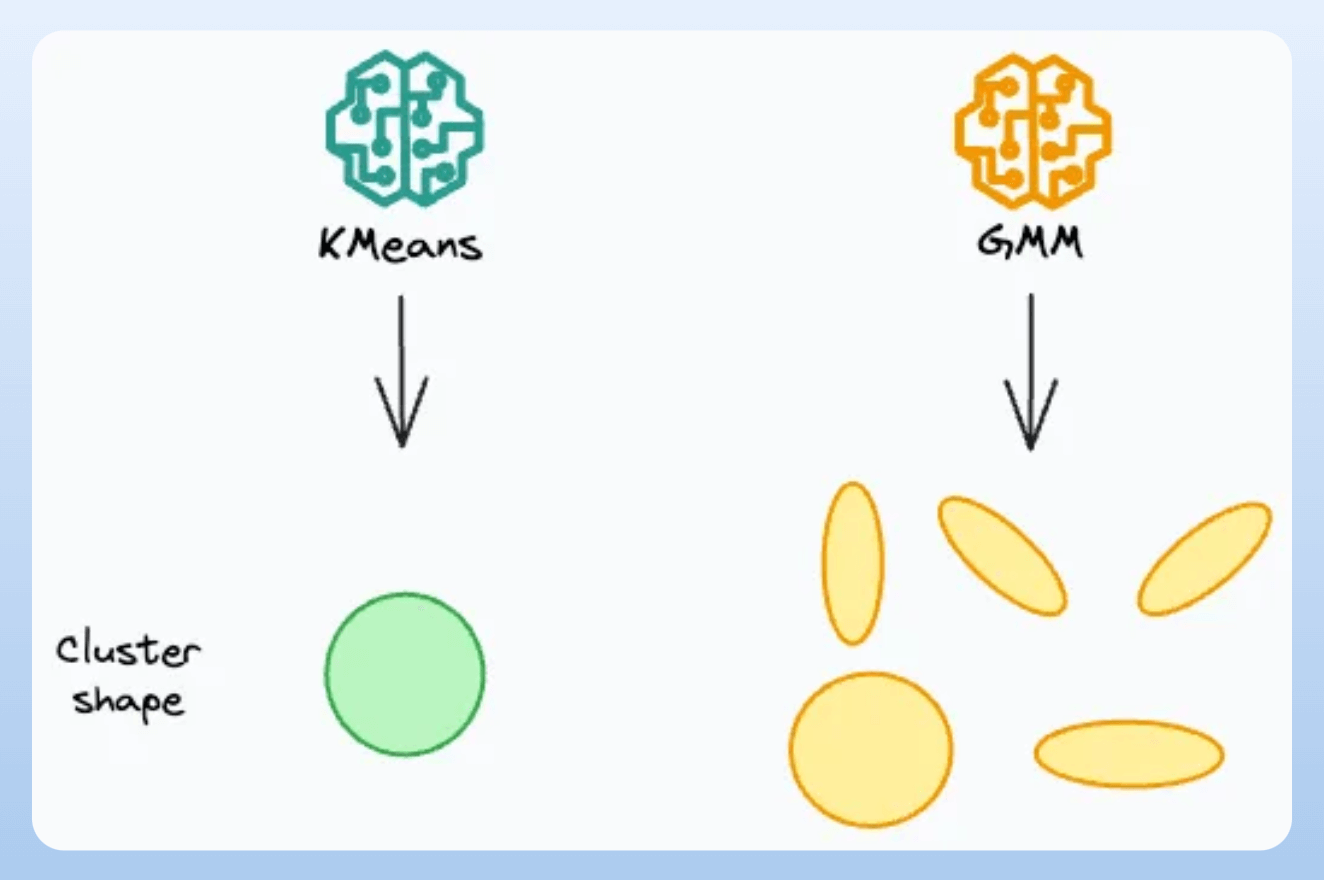
KMeans will assume circular clusters.
GMM can still work with oval-shaped clusters.
This is illustrated in the animation below:

The effectiveness of GMMs over KMeans is evident from the image below.
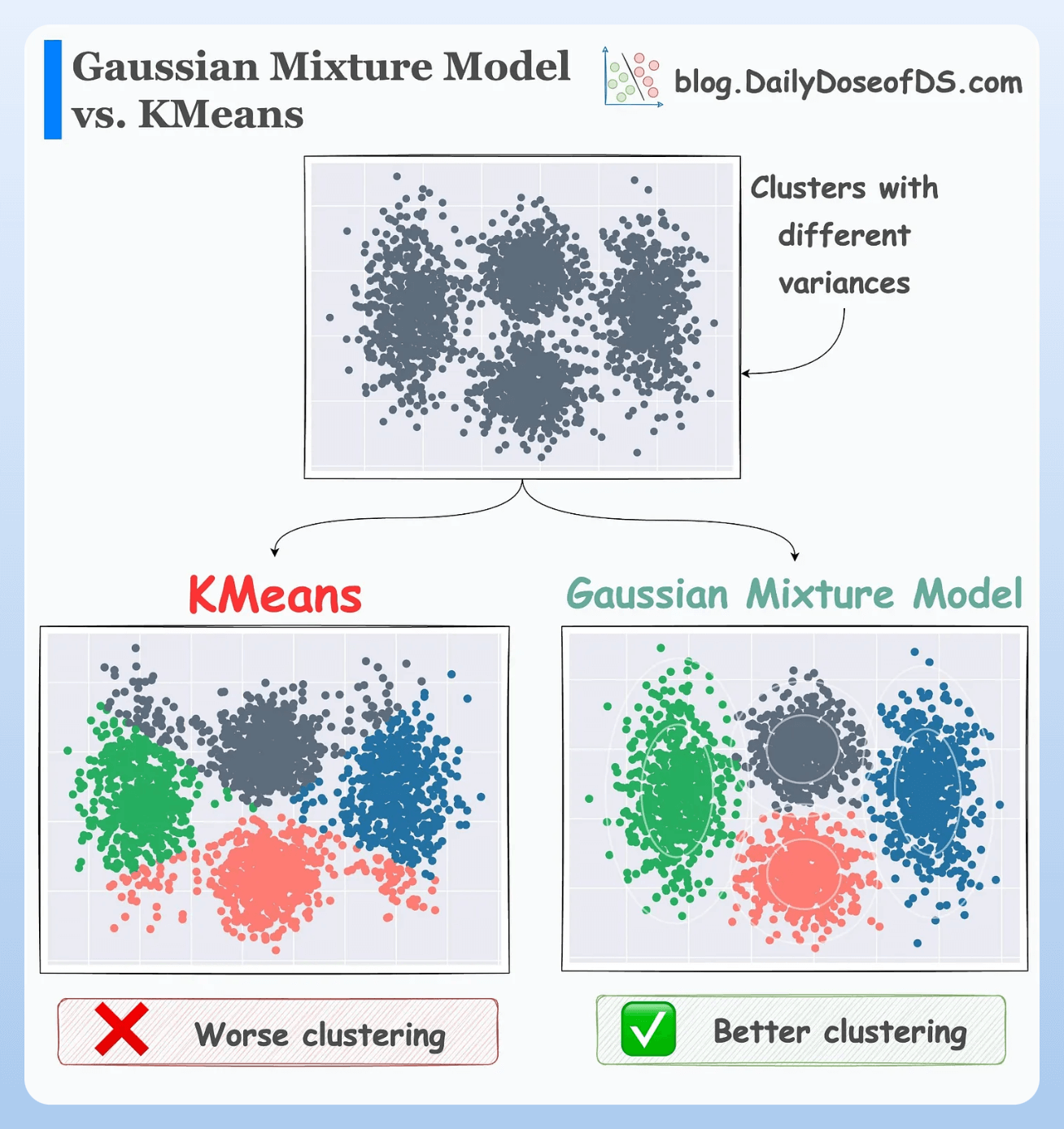
KMeans just relies on distance and ignores the distribution of each cluster.
GMM learns the distribution and produces better clustering.
If you want to get into more details, we covered them in-depth here: Gaussian Mixture Models.
It covers:
The motivation and intuition behind GMMs.
The end-to-end mathematical formulation of GMMs.
Using Expectation-Maximization to model data using GMMs
Coding a GMM from scratch (no sklearn).
Ways to determine the optimal number of clusters for GMMs.
Practical use cases of GMMs.
Takeaways.
👉 Over to you: What are some other shortcomings of KMeans?
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.