
Knowledge Distillation for Model Compression
A practical walkthrough

Model accuracy alone (or an equivalent performance metric) rarely determines which model will be deployed.
This is because we also consider several operational metrics, such as:
Inference Latency: Time taken by the model to return a prediction.
Model size: The memory occupied by the model.
Ease of scalability, etc.

Today, let me share a technique (with a demo) called knowledge distillation, which is commonly used to compress ML models and contribute to the above operational metrics.
This newsletter is taken from my article on model compression, where we discussed 5 more techniques: Model Compression: A Critical Step Towards Efficient Machine Learning.
Let’s begin!
What is knowledge distillation?
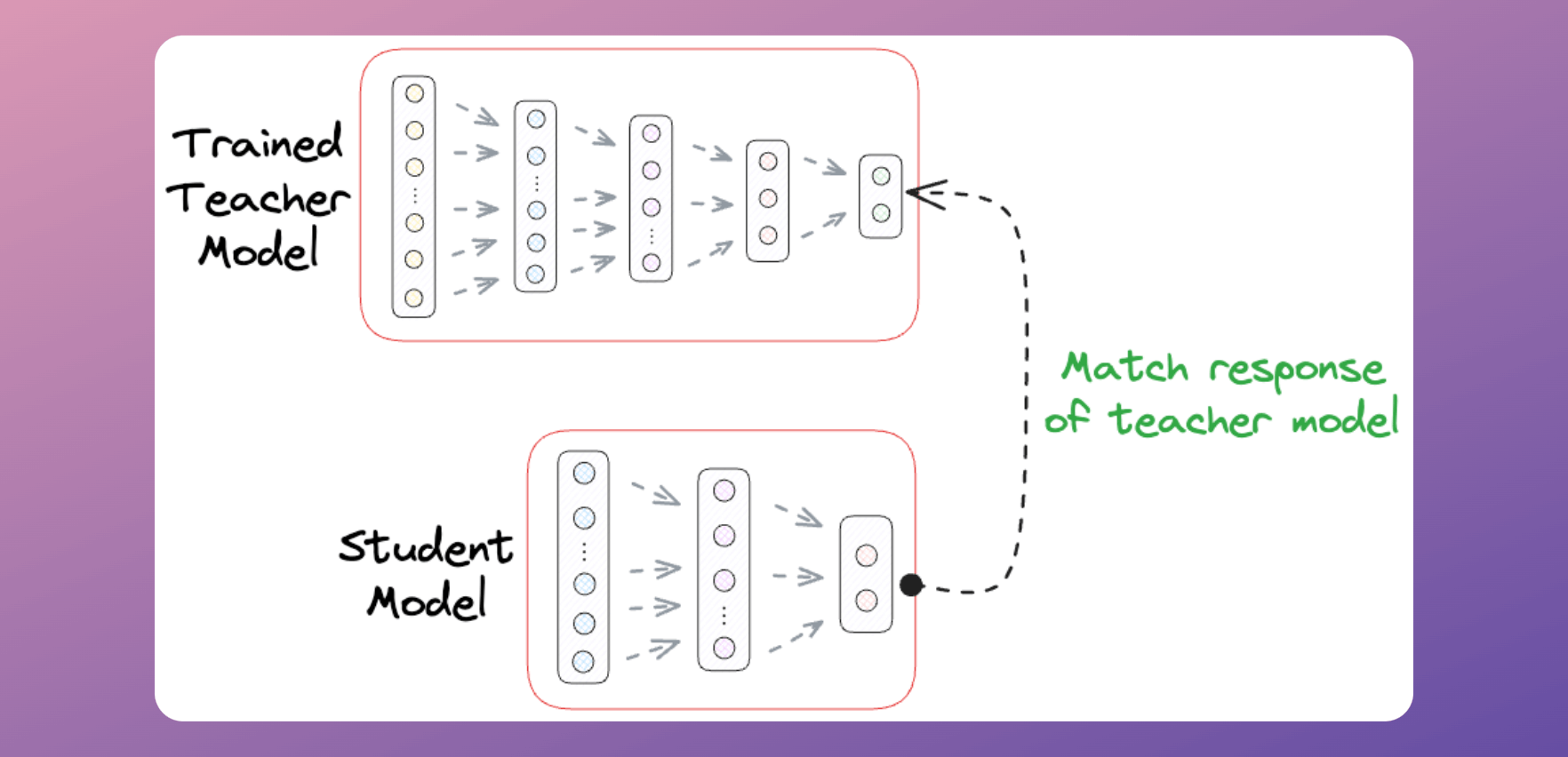
In a gist, the idea is to train a smaller/simpler model (called the “student” model) that mimics the behavior of a larger/complex model (called the “teacher” model).
This involves two steps:
Train the teacher model as we typically would.
Train a student model that matches the output of the teacher model.
If we compare it to an academic teacher-student scenario, the student may not be as performant as the teacher.
But with consistent training, a smaller model may get (almost) as good as the larger one.
A classic example of a model developed in this way is DistillBERT. It is a student model of BERT.
DistilBERT is approximately 40% smaller than BERT, which is a massive difference in size.
Still, it retains approximately 97% of the BERT’s capabilities.
Next, let’s look at a demo.
Knowledge distillation demo
In the interest of time, let’s say we have already trained the following CNN model on the MNIST dataset (I have provided the full Jupyter notebook towards the end, don’t worry):

The epoch-by-epoch training loss and validation accuracy is depicted below:

Next, let’s define a simpler model without any convolutional layers:

Being a classification model, the output will be a probability distribution over the <N> classes:
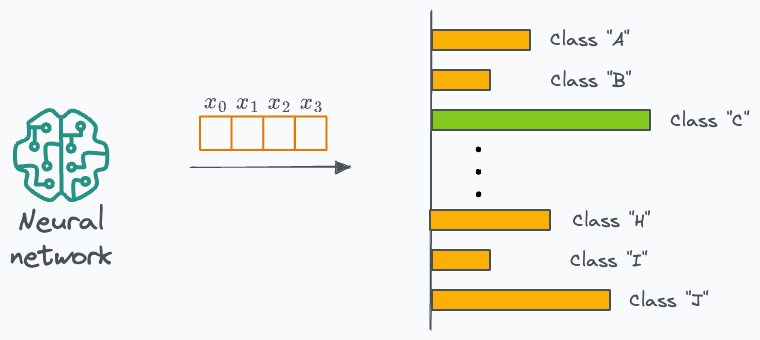
Thus, we can train the student model such that its probability distribution matches that of the teacher model.

One way to do this, which we also saw in the tSNE article, is to use KL divergence as a loss function.
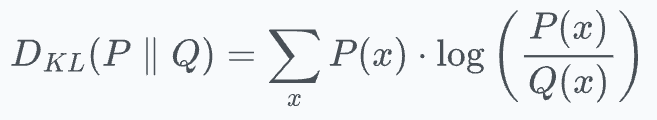
It measures how much information is lost when we use distribution Q to approximate distribution P.
A question for you: What will be the KL divergence if P=Q?
Thus, in our case:
Pwill be the probability distribution from the teacher model.Qwill be the probability distribution from the student model.
The loss function is implemented below:

Finally, we train the student model as follows:

Done!
The following image compares the training loss and validation accuracy of the two models:

Of course, as shown in the highlighted lines above, the performance of the student model is not as good as the teacher model, which is expected.
However, it is still pretty promising, given that it was only composed of simple feed-forward layers.
Also, as depicted below, the student model is approximately 35% faster than the teacher model, which is a significant increase in the inference run-time of the model for about a 1-2% drop in the test accuracy.

Cool, isn’t it?
That said, one of the biggest downsides of knowledge distillation is that one must still train a larger teacher model first to train the student model.
But in a resource-constrained environment, it may not be feasible to train a large teacher model.
So this technique assumes that we are not resource-constrained at least in the development environment.
In this issue, we only covered one technique — Knowledge distillation.
We covered 5 more techniques here: Model Compression: A Critical Step Towards Efficient Machine Learning.
Download the full code for this newsletter issue here: Knowledge distillation Jupyter notebook.
👉 Over to you: What are some other ways to build cost-effective models?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
A Beginner-friendly Introduction to Kolmogorov Arnold Networks (KANs).
5 Must-Know Ways to Test ML Models in Production (Implementation Included).
Understanding LoRA-derived Techniques for Optimal LLM Fine-tuning
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing.
How To (Immensely) Optimize Your Machine Learning Development and Operations with MLflow.
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 77,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
This is a cool technique, thank you for this article. Makes me curious how you would do it for other kinds of models besides classification, how their loss functions would look like when training the student model