
L2 Regularization is NOT Just a Regularization Technique
A lesser-known usage of L2 regularization.

An open-source, enterprise-grade RAG solution!
If you’re building an enterprise-grade RAG system, you’ll run into 2 challenges:
Data scattered across 100s of sources.
Need for real-time sync.
Knowledge bases by MindsDB is an open-source solution that solves this!

A knowledge base is an advanced AI table that organizes data by semantic meaning, not just simple keyword matching.
It integrates embedding models, reranking models, and vector stores to enable context-aware data retrieval.
The core philosophy behind its operation:
Connect your data: MindsDB connects to 200+ enterprise sources (Postgres, Salesforce, S3, Slack, etc.), so you can access everything, everywhere.
Unify your data: It gives you views and knowledge bases that organize structured + unstructured data as if it lived in one place.
Respond using data: MindsDB has built-in agents that answer questions using your data.
So if you need a real-time sync, just schedule a job, and it automates unification on the fly.
You can also plug in any external agent or AI app using its open-source MCP server.
This whole stack can be self-hosted with a single Docker command.
GitHub repo → (don’t forget to star it)
We’ll cover this in more detail with a hands-on demo soon!
L2 regularization is NOT just a regularization technique
L2 regularization is commonly used to prevent overfitting.
But in addition to this, L2 regularization also solves multicollinearity, which arises when two (or more) features are highly correlated OR two (or more) features can predict another feature:
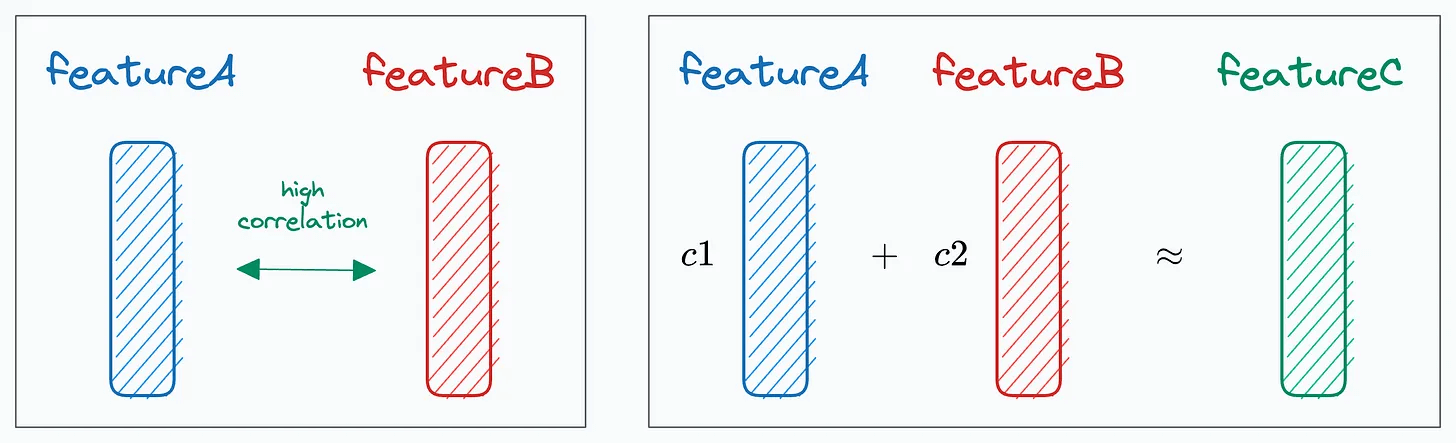
Let’s understand how L2 regularization does that!
Note: If you want to learn about the probabilistic origin of L2 regularization, check out this article: The Probabilistic Origin of Regularization.
For demonstration purposes, consider this dummy dataset with two features, where featureB highly correlated with featureA:
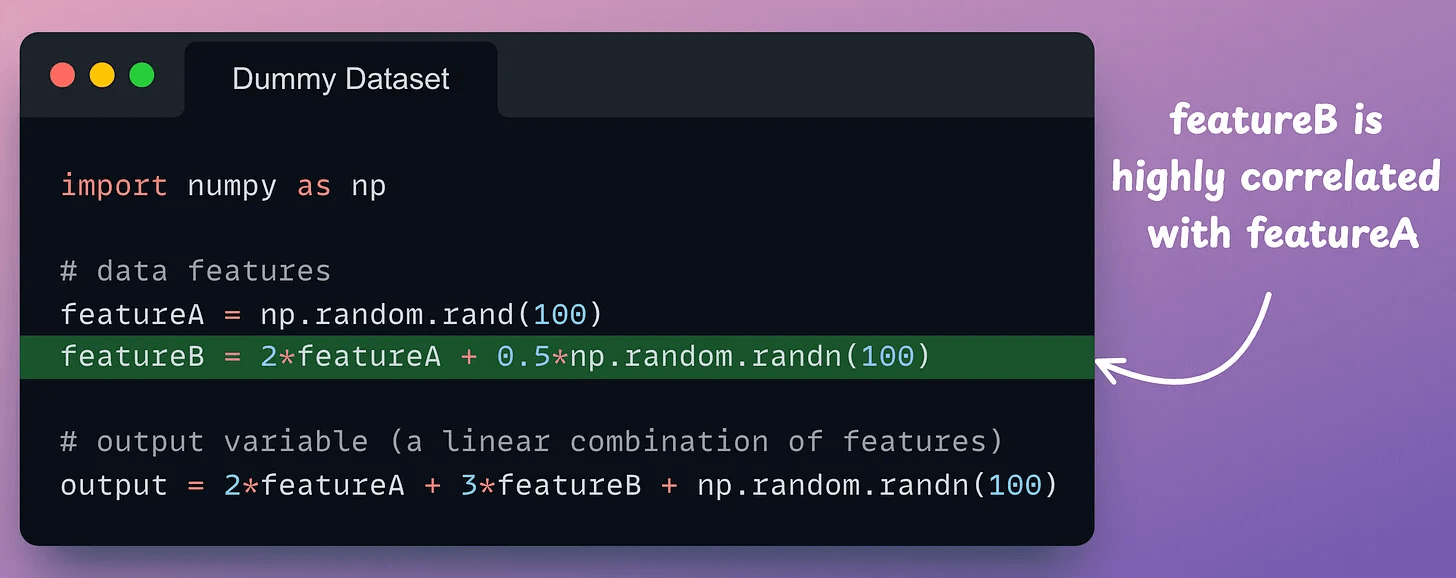
Two features mean two parameters (θ₁, θ₂), and the objective will be to minimize the residual sum of squares (RSS):

Let’s do that visually by plotting the RSS value for many different combinations of (θ₁, θ₂) parameters.
This creates a 3D plot with:

x-axis → θ₁
y-axis → θ₂
z-axis → RSS value
The 3D plot above has a valley. This means there are multiple combinations of parameter values (θ₁, θ₂) for which RSS is minimum.
Thus, we cannot obtain a single value for the parameters (θ₁, θ₂) that minimizes the RSS.
Now we add the L2 penalty, and the objective function becomes:
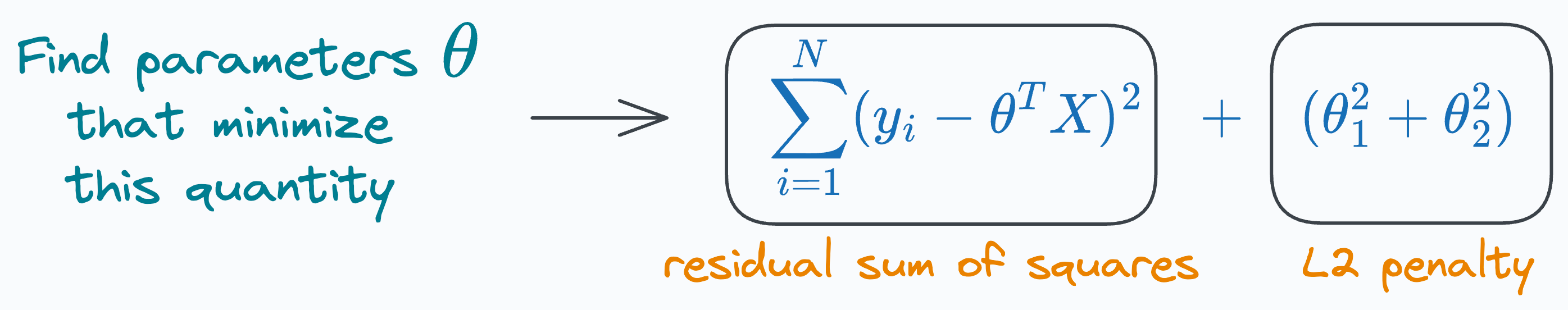
Creating the same plot again, we get:
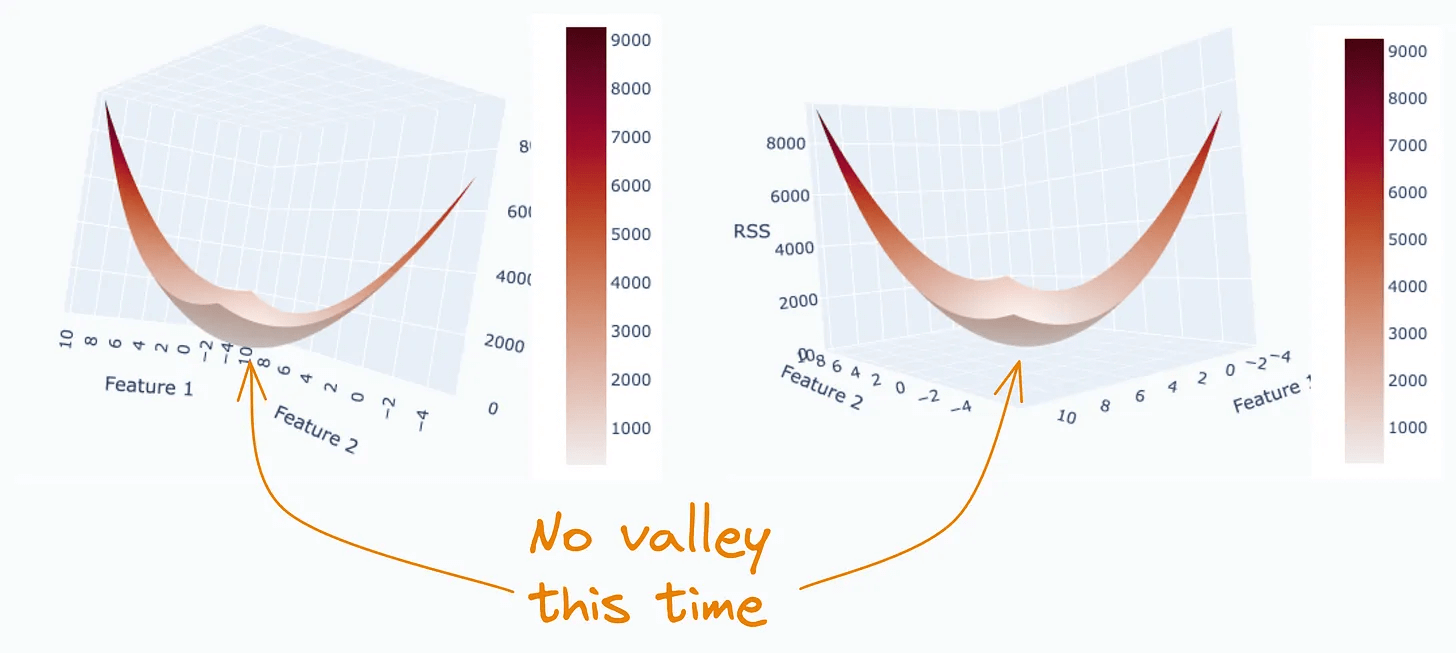
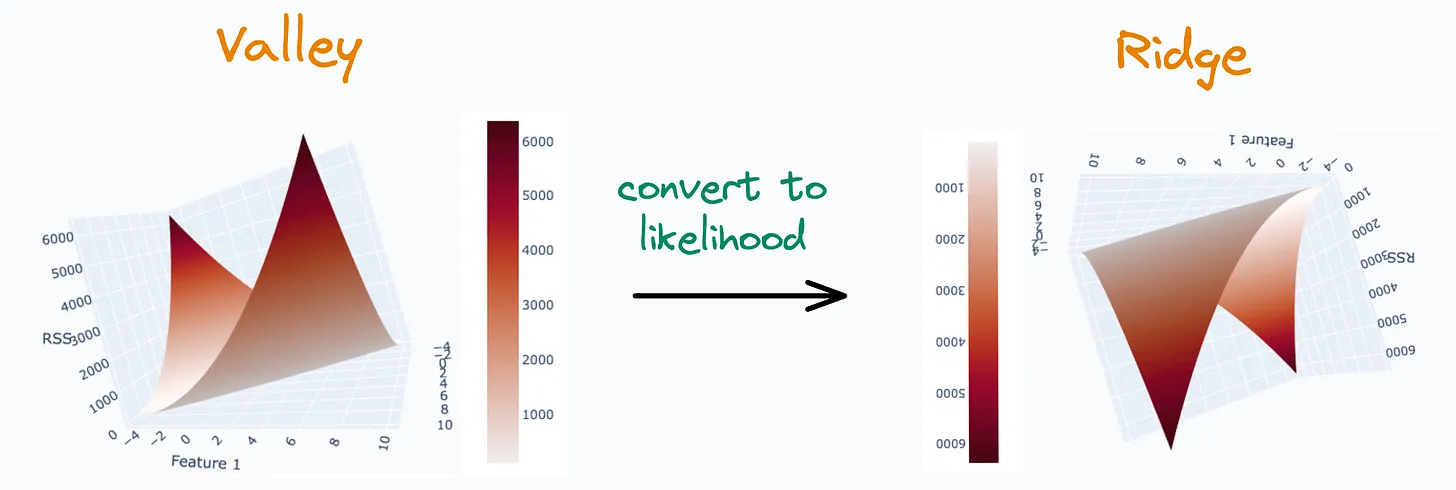
This time, we get a global minima since the valley has disappeared. This is exactly how L2 regularization helps eliminate multicollinearity.
In fact, that is why the algorithm is called “ridge regression”—L2 penalty eliminates the ridge in the likelihood function:

Although yes, in the demonstrations we discussed earlier, we noticed a valley, not a ridge.
But, in that case, we considered the residual sum of error (something which is minimized).
If we use likelihood instead (something which is maximized), it would invert the graph and result in a ridge:
To learn about the probabilistic origin of L2 regularization, check out this article: The Probabilistic Origin of Regularization.
Also, if you struggle with mathematical details, here are some topics that would interest you (covered with intuition):
You Are Probably Building Inconsistent Classification Models Without Even Realizing
Why Sklearn’s Logistic Regression Has no Learning Rate Hyperparameter?
👉 Over to you: What are some other advantages of using L2 regularization?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.