
Loop Engineering: Design the System That Prompts Agents
...explained visually.

Strands Agents
-10.png")
Your first agent: running in a few lines of code.
Your production agent: the same lines of code, scaled.
Strands grows with your use case, from a local prototype to a deployed system handling real workloads, without a rewrite in between.
Open source. Model-driven. Any backend.
Thanks to AWS for partnering today!
Loop engineering: Design the system that prompts agents
In a hand-run agent session, you hold two jobs:
deciding what the agent runs next
and checking its output before the next step.
Loop engineering moves both into the system.
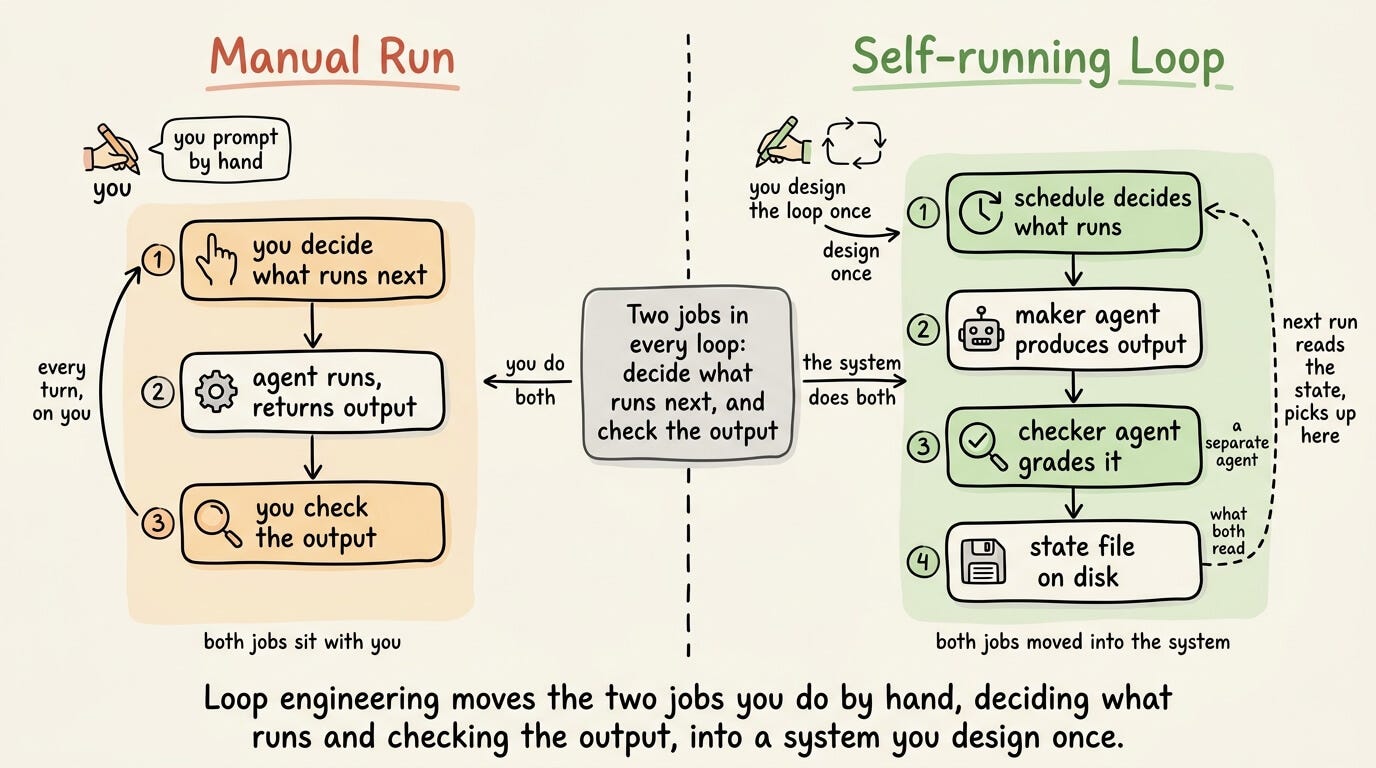
Essentially, a schedule decides what runs, a separate checker agent grades the output, and a file on disk holds the state that they both read.
Boris Cherny, who leads Claude Code, stopped prompting Claude by hand and now writes the loops that prompt it instead.
So today, let’s break down what a loop is built from, the split that does the real work, and what stays manual.
The six parts a loop are built from
A loop is assembled from five components plus a memory, and Claude Code and Codex both ship all of them now.
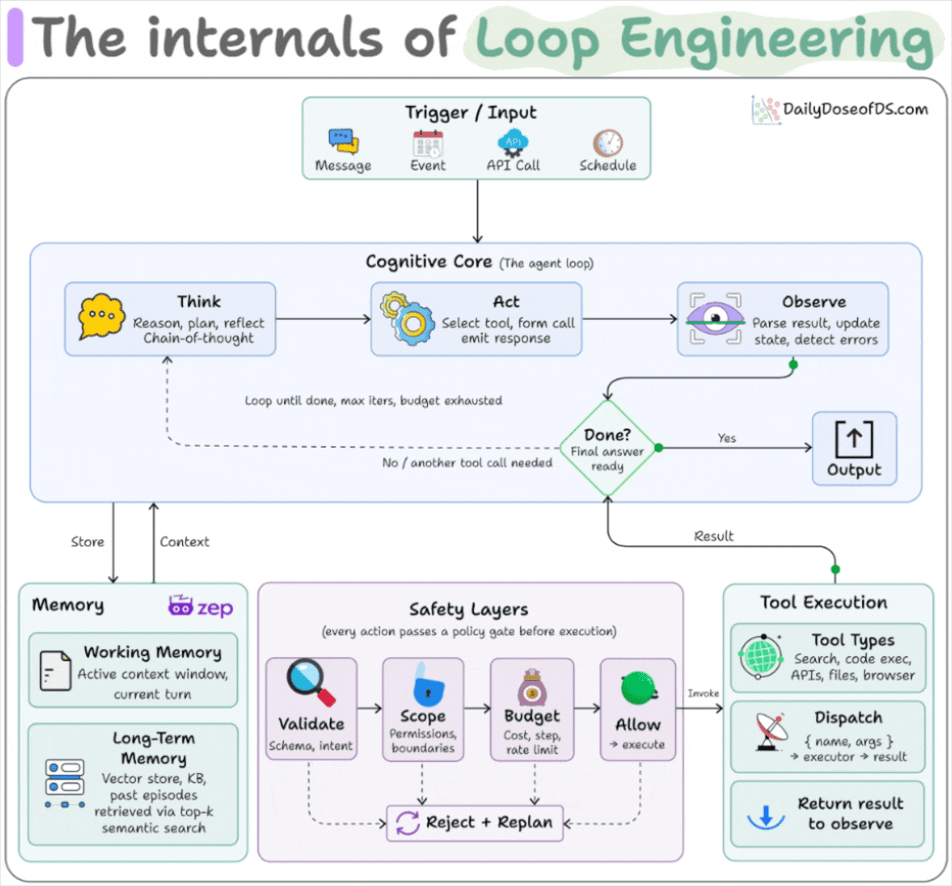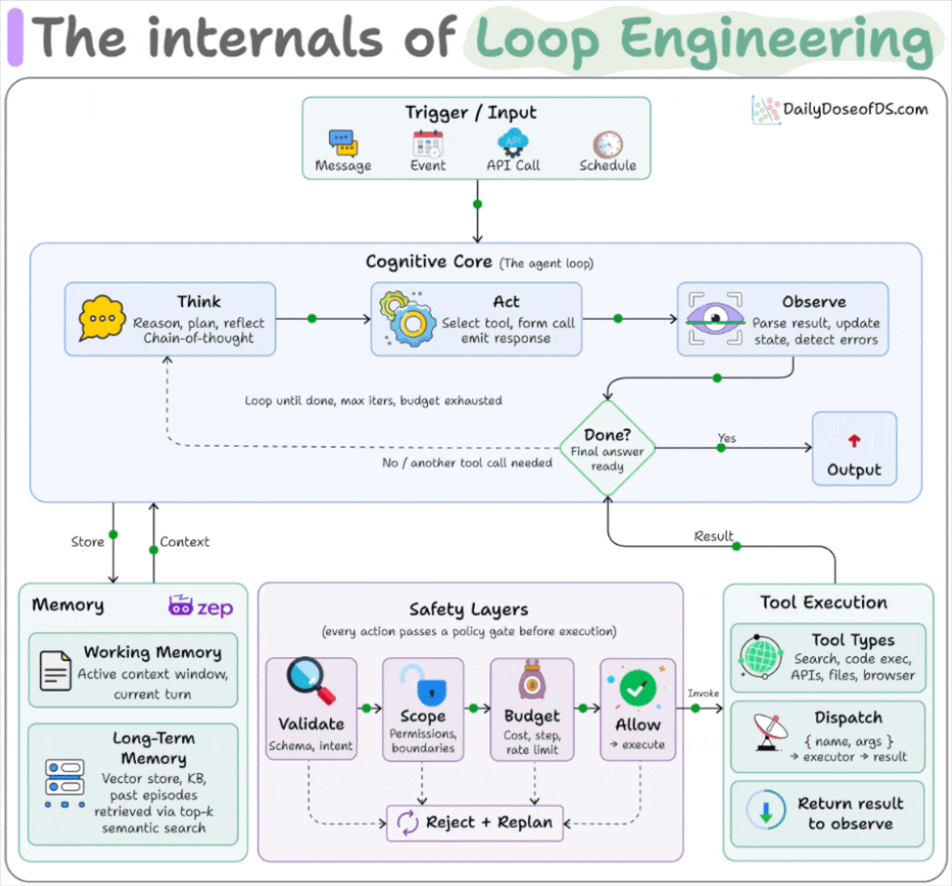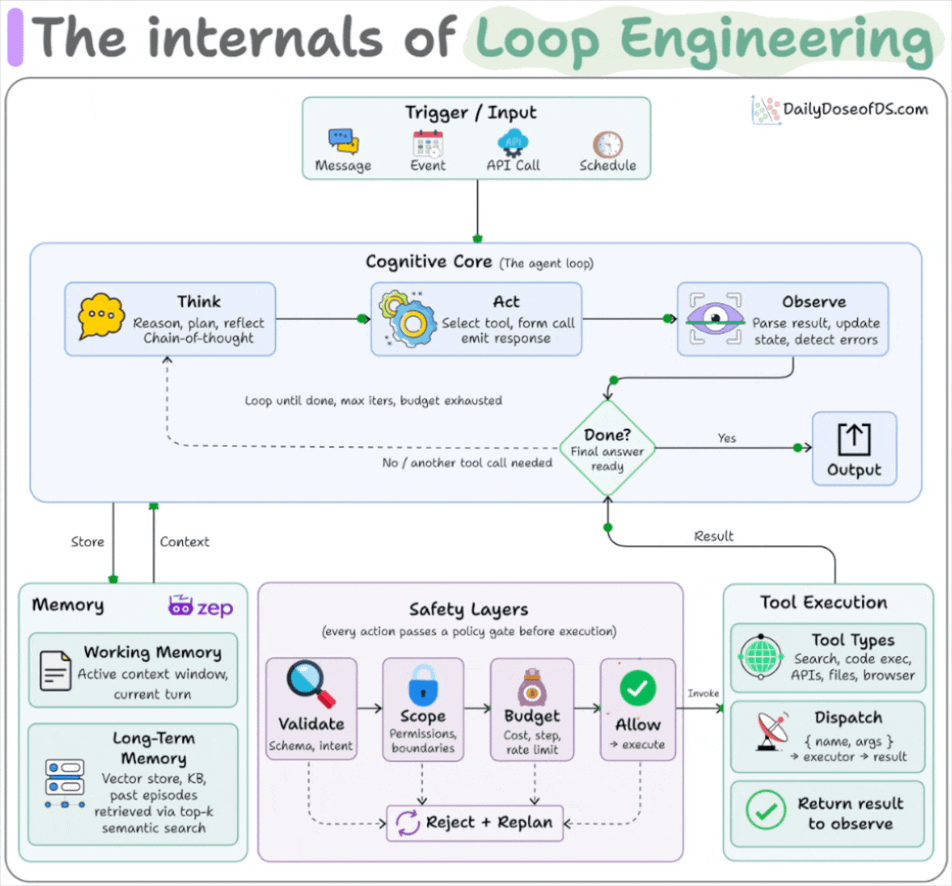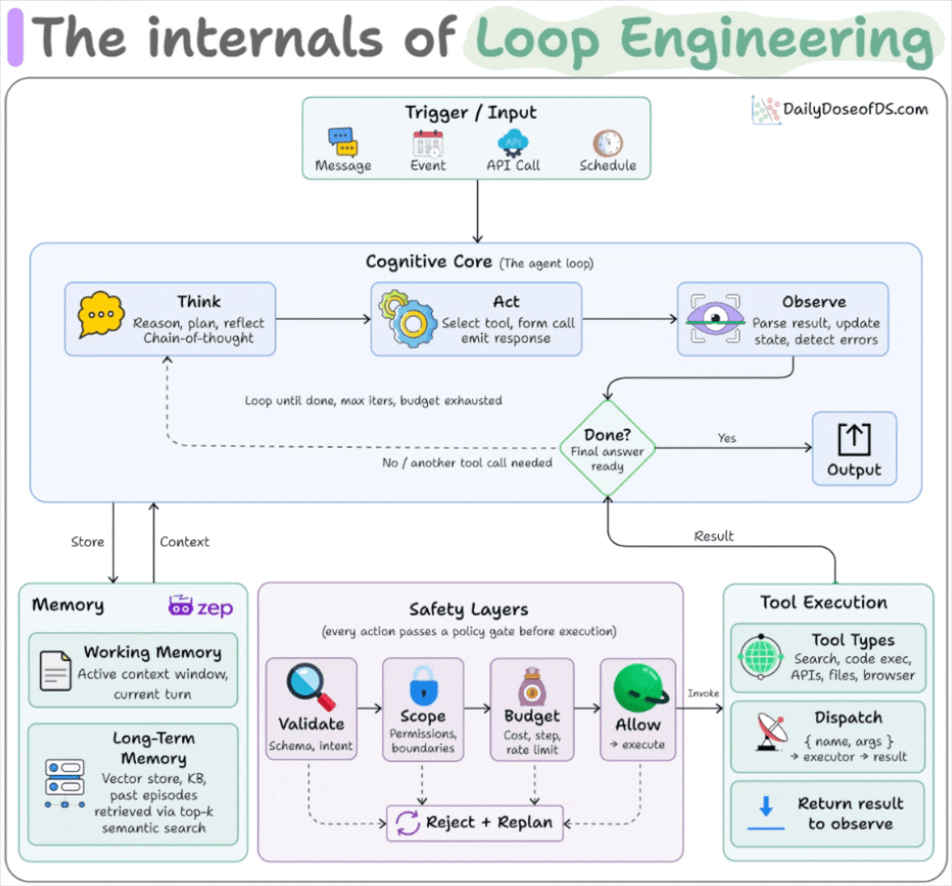
Automations fire on a schedule and do discovery and triage on their own.
Worktrees give each agent its own checkout, so two running in parallel don’t overwrite each other’s files. Leaving orphaned worktrees behind is the main way this turns messy.
Skills hold the project knowledge the agent would otherwise re-derive from zero every run, like conventions, build commands, and review standards. An automation can fire a skill by name instead of carrying a wall of instructions that nobody maintains.
Connectors wire the agent into your real tools over MCP, the issue tracker, the database, Slack.
Sub-agents split the work, so one agent makes the change and a different one checks it.
Memory is the sixth piece, giving you a dedicated knowledge graph (using Zep Graphiti, for instance) that lives outside the conversation and records what’s done and what’s next.
Here’s what you need to make sure when building these systems:
The maker-checker split
The split between the maker and the checker makes a loop safe to leave alone.
This is important because a model grading its own output is too lenient to catch its own bugs, so the checker runs as a separate agent, ideally a different model, scored against independent signals.
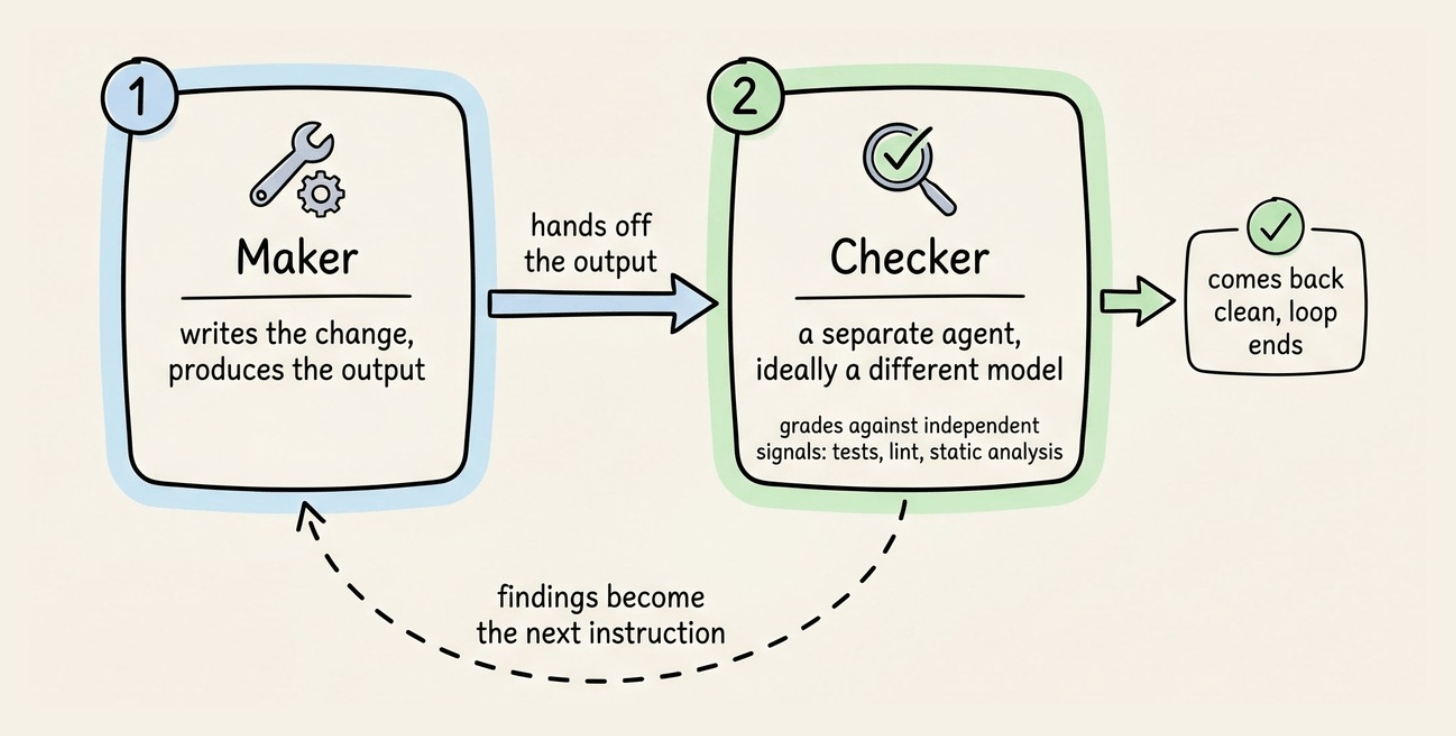
Its findings go back to the maker as the next instruction, and the cycle repeats until they come back clean.
Set the exit before you start
A loop with no stop condition churns and burns tokens, and the token cost climbs fast once sub-agents and long runs stack up.
One thing you can do in practice goes something like…fix major issues only, run one final pass, then stop after two loops, with “all tests pass and lint clean” as the explicit exit.
Decide this before the loop runs, not while it’s running.
State lives on disk, not in context
The model forgets everything between runs, so the state has to sit outside the conversation.
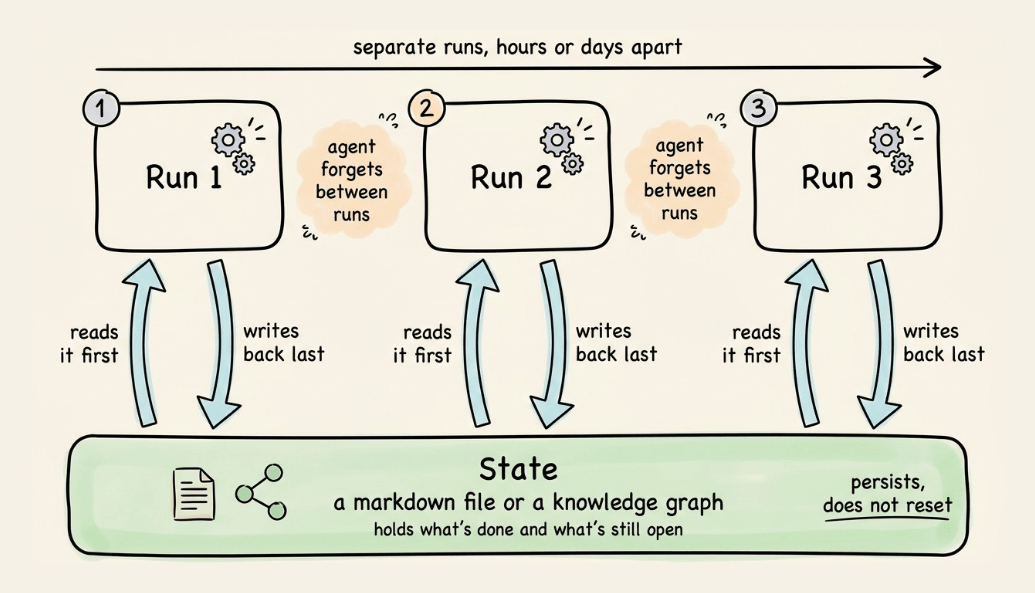
A markdown file or a knowledge graph can hold what’s done and what’s still open, and each run reads it first and writes back to it last.
The agent forgets between runs, but this does not, which is precisely what lets a loop pick up across days instead of resetting every session.
Loops are important on the boring, high-frequency checks you skip by eye, like a stale version string or a missing test, but not on work that needs judgment.
An unattended loop fails in two ways.
It reports done when nothing actually verified the work, which is what the separate checker is there to prevent.
And it merges code faster than you read it, so over weeks, you stop understanding your own codebase while every check stays green.
Green tests tell you the code passed the tests, not that you know what shipped, so the habit that keeps a loop honest is reading what it merges, not just watching the checks pass.
We’ll make this much more concrete by sharing a hands-on demo soon.
In the meantime, just remember that loop engineering is a simple trade where you stop being the one who prompts and become the one who designs the loop that prompts it.
👉 Over to you: where would you actually let an agent loop run unattended, and where would you keep your hand on every turn?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.