
LoRA/QLoRA—Explained From a Business Lens
From 350 GB to 25 MB.

Build production-grade Agents with CoAgents [Open-source]
Building agent-native apps is challenging, and a lot of it boils down to not having appropriate tooling.
But this is changing!
CoAgents, an open-source framework by CopilotKit, lets you build Agents with human-in-the-loop workflows: CopilotKit GitHub Repo (star the repo).

The latest updates to CoAgents bring together:
LangGraph JS to build modular, debuggable workflow creation.
LangGraph Platform to ensure production-grade reliability.
LangSmith to monitor, debug, and visualise the agent.
Moreover, CoAgents also lets you:
Steer Agent to correct things.
Stream the intermediate agent states.
Share the state between the agent & the app.
Use Agentic UI to generate custom UI components.
Impressive, right?
Big thanks to CopilotKit for partnering today and showing what's possible with their powerful Agent-development framework.
LoRA/QLoRA—Explained from a business lens
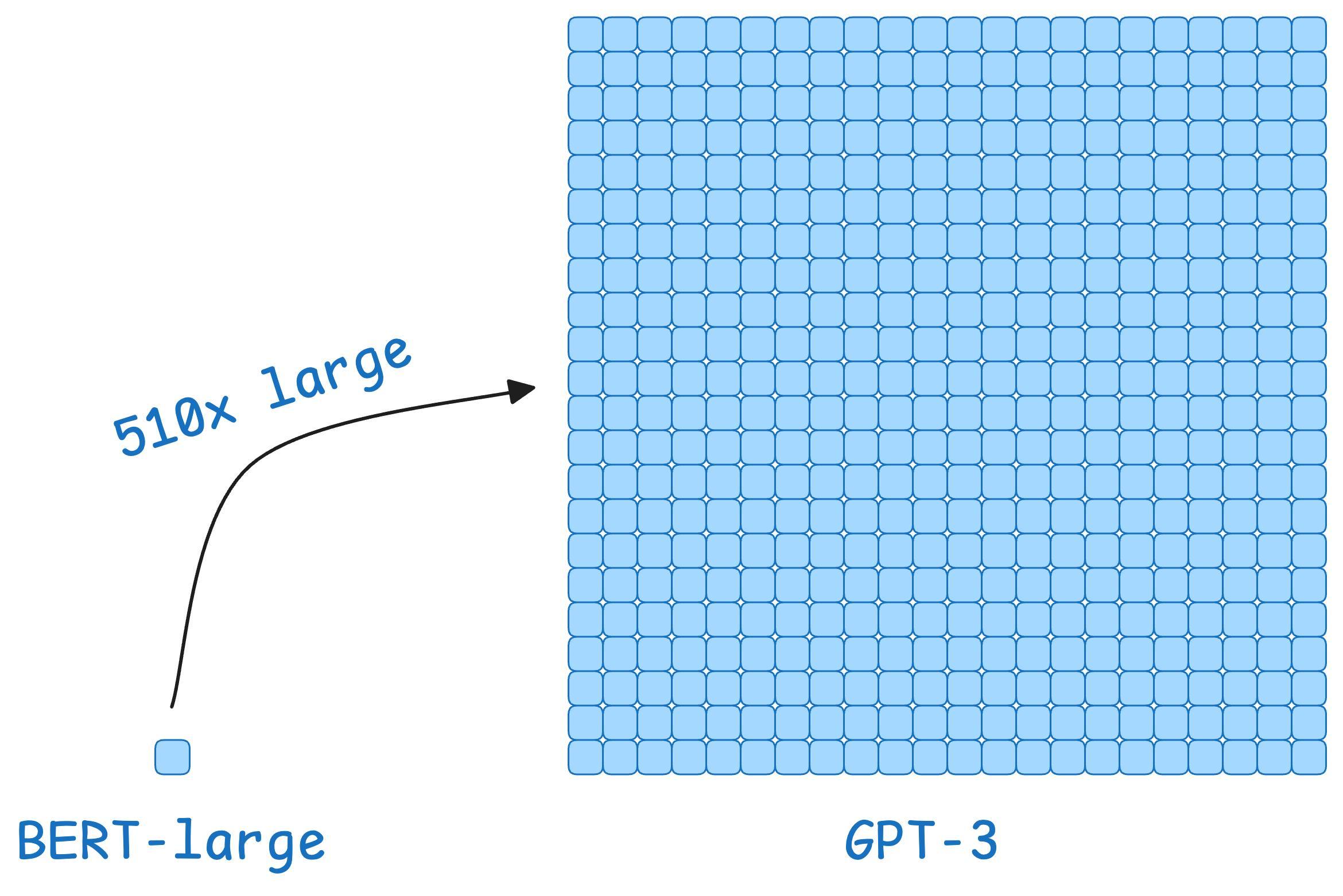
Consider the size difference between BERT-large and GPT-3:
I have fine-tuned BERT-large several times on a single GPU using traditional fine-tuning:
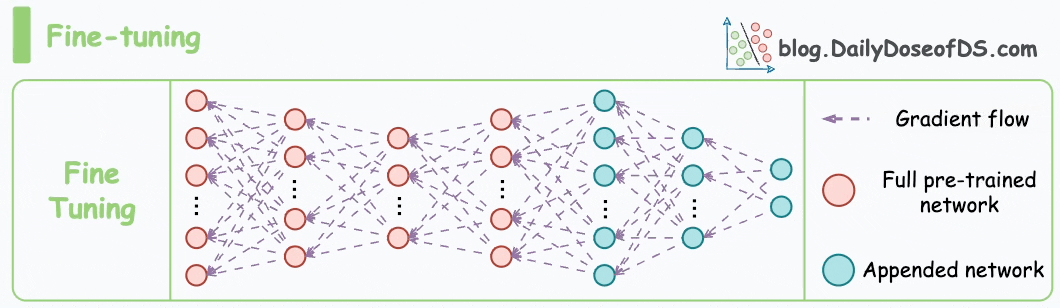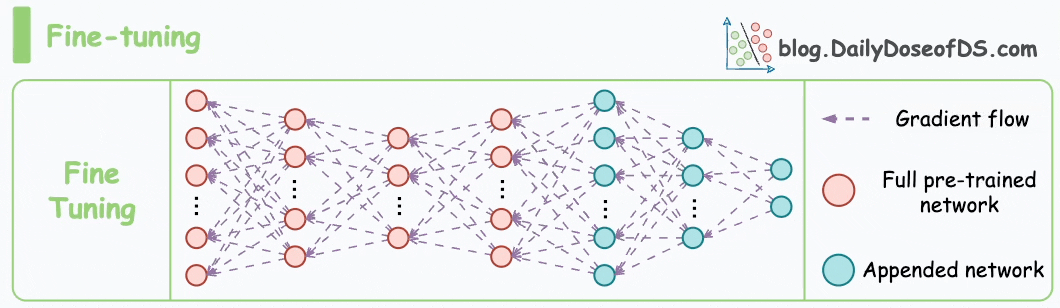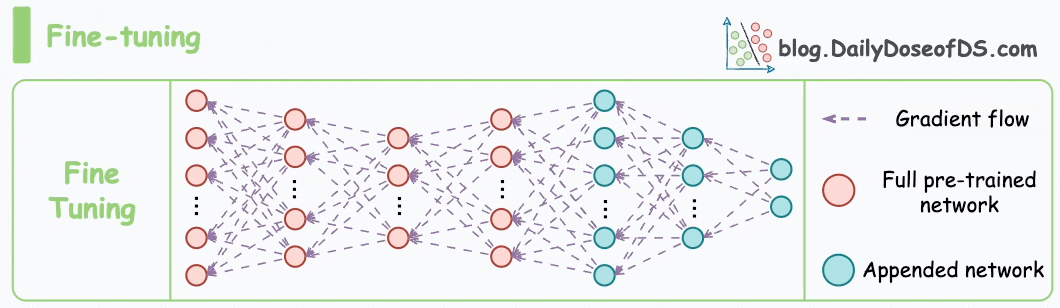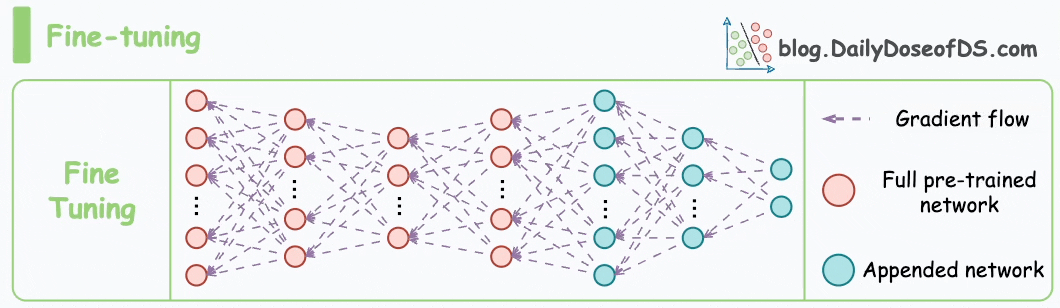
But this is impossible with GPT-3, which has 175B parameters. That's 350GB of memory just to store model weights under float16 precision.
This means that if OpenAI used traditional fine-tuning within its fine-tuning API, it would have to maintain one model copy per user:
If 10 users fine-tuned GPT-3 → they need 3500 GB to store model weights.
If 1000 users fine-tuned GPT-3 → they need 350k GB to store model weights.
If 100k users fine-tuned GPT-3 → they need 35 million GB to store model weights.
And the problems don't end there:
OpenAI bills solely based on usage. What if someone fine-tunes the model for fun or learning purposes but never uses it?
Since a request can come anytime, should they always keep the fine-tuned model loaded in memory? Wouldn't that waste resources since several models may never be used?
LoRA (+ QLoRA and other variants) neatly solved this critical business problem.
The core idea revolves around training a few parameters compared to the base model.
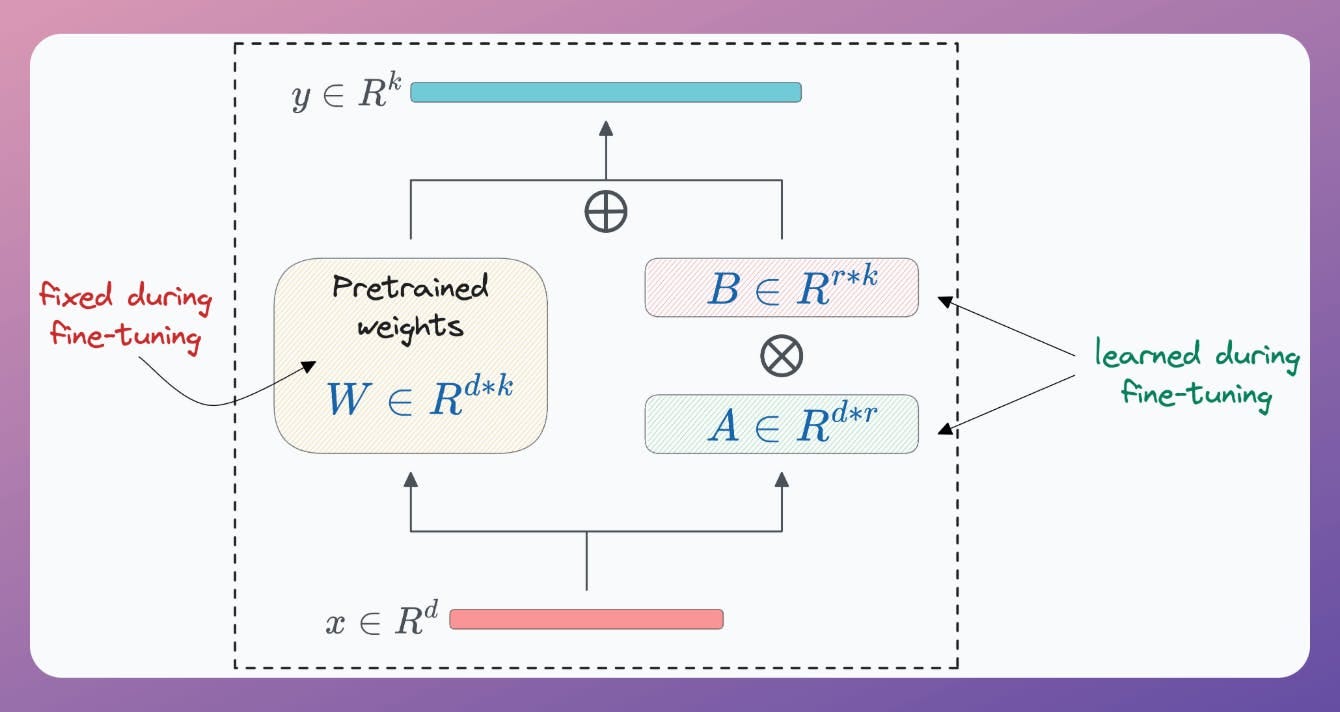
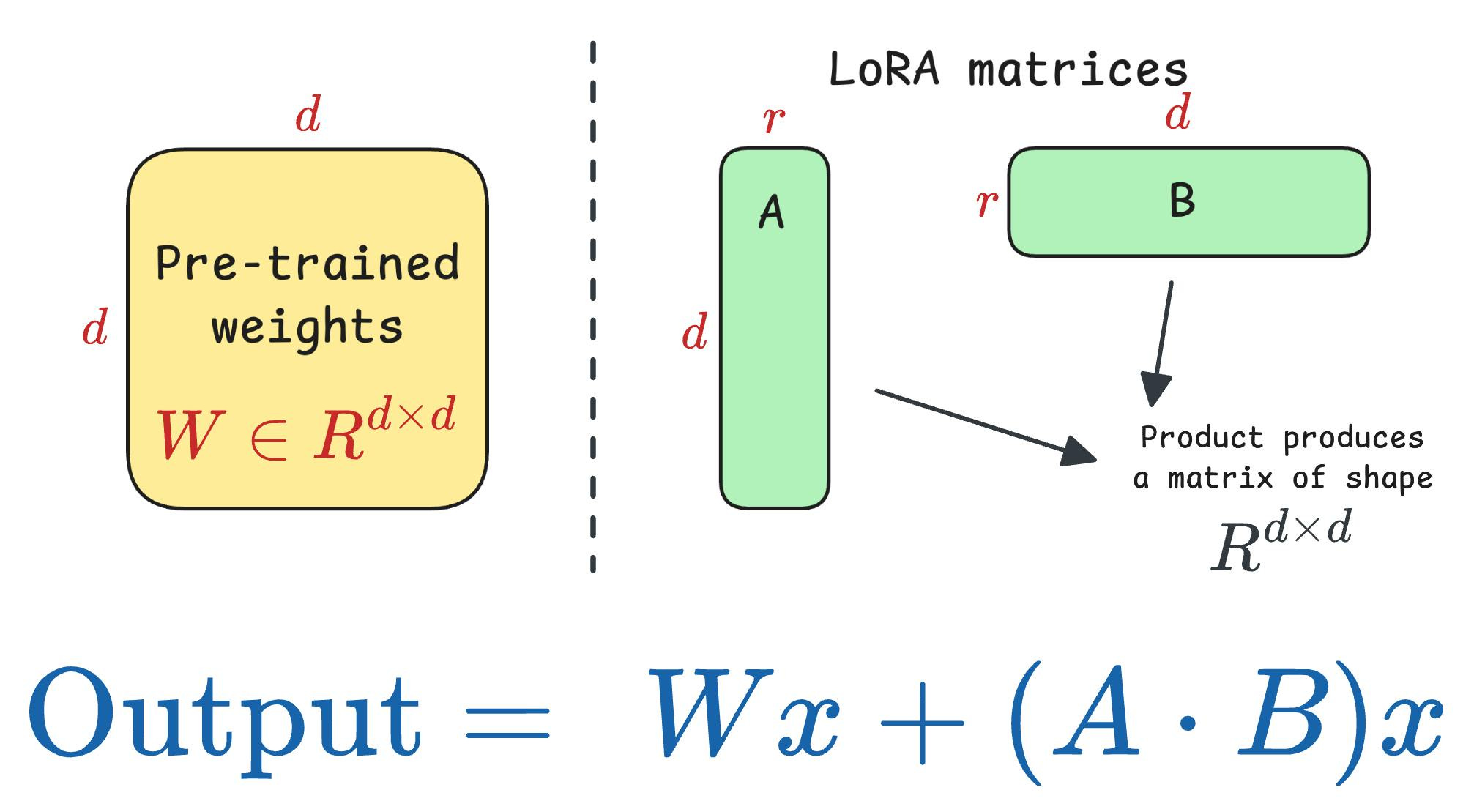
For instance, if the original model has a weight matrix W (shape d*d), one can define the corresponding LoRA matrices A (d*r) and B (r*d)
↳ where r <<<< d (typically, r is a single-digit number).
During fine-tuning, freeze the weight matrix W and update the weights of the LoRA matrices.
During inference, the product of the LoRA matrices results in a matrix of the same shape as W. So one can obtain the output as follows:
This way, every user gets their LoRA matrices, and OpenAI can maintain just one global/common model to infer the result.
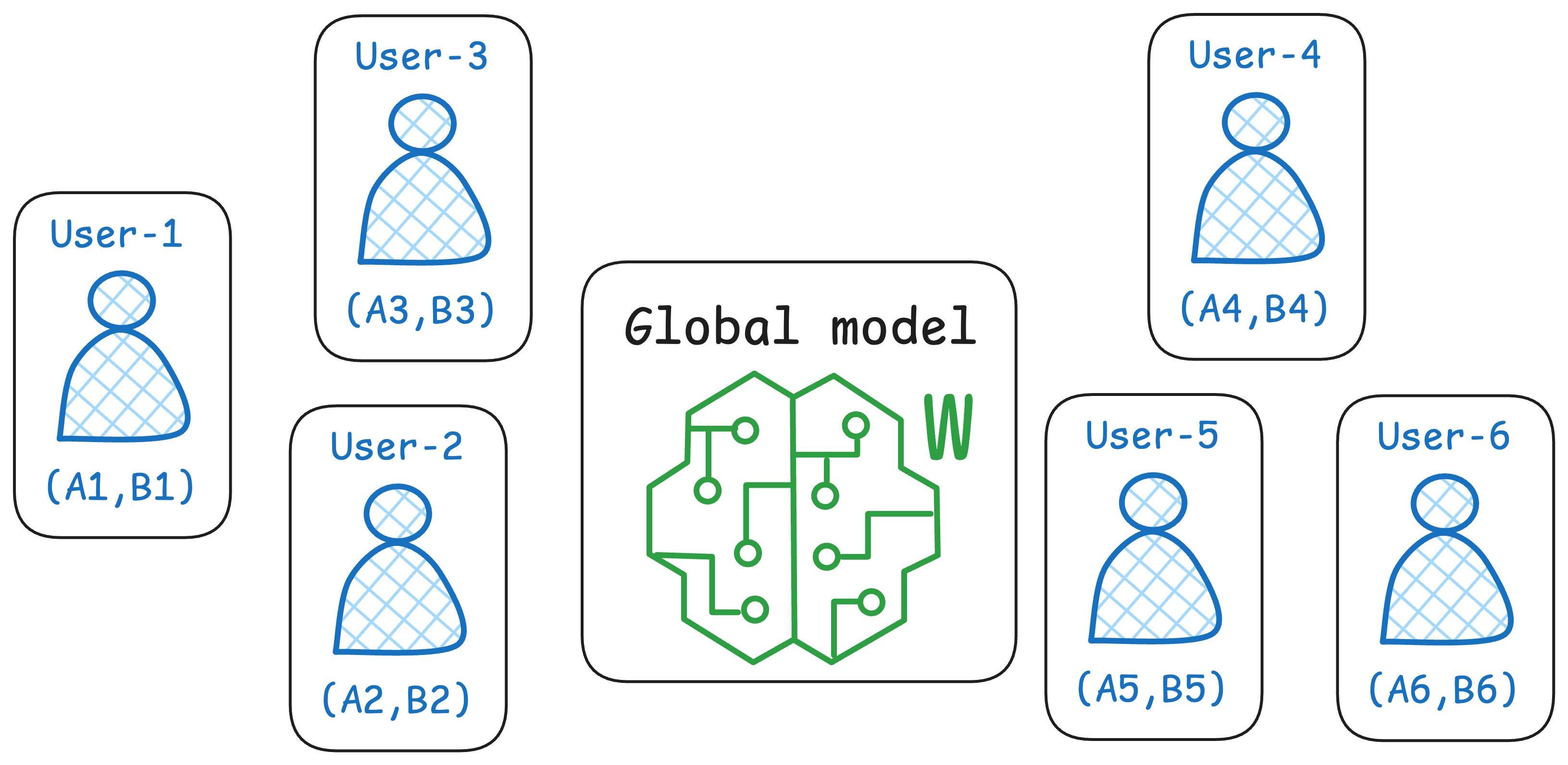
Another good thing is that LoRA matrices usually do not require more than 20-25 MB of memory per user. This is immensely smaller than what we get from traditional fine-tuning.
Lastly, this also solves the other two problems we mentioned earlier:
If someone fine-tunes the model just for fun or learning purposes but never uses it, it's okay; LoRA matrices are still manageable.
Loading small LoRA matrices from disk isn't tedious either. These small matrices can be off-loaded if not used for a while and reloaded when needed.
We implemented LoRA for fine-tuning LLMs from scratch here →
LoRA has several efficient variants. We covered them here →
If you want to develop expertise in “business ML,” we have discussed several other topics (with implementations) that align with it:
Here are some of them:
Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Conformal Predictions: Build Confidence in Your Model's Predictions.
5 Ways to Test ML Models in Production (Implementation Included).
Model Compression: A Step Towards Efficient Machine Learning.
Why care?
All businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?

Thus, the ability to make decisions, guide strategy, and build solutions that solve real business problems and have a business impact will separate practitioners from experts.
👉 Over to you: What are some other benefits of LoRA over traditional fine-tuning?