
Manual RAG Pipeline vs Agentic Context Engineering
...a popular interview question (explained visually).

A new benchmark for reliable OCR is here!
OCR benchmarks often reward text similarity.
However, a document can be 99% “correct” and still be 100% useless if the structure collapses.
Tensorlake’s latest Document Parsing Model addresses this!
Instead of asking “Does the text look similar?”, it asks “Can your downstream system actually use this data?” using two real-world metrics:
TEDS → Measures structural fidelity (tables, layouts, reading order)
JSON F1 → Measures extraction usability for automation

Tensorlake’s model hit 91.7 F1 on enterprise docs, outperforming Azure, AWS Textract, and open-source models like Docling and Marker, while matching Azure’s cost and beating Textract’s by 50%.
If you’re building RAG pipelines or financial data extraction, take a look.
Thanks to Tensorlake for partnering today!
Manual RAG Pipeline vs Agentic Context Engineering
Imagine you have data that’s spread across several sources (Gmail, Drive, etc.).

How would you build a unified query engine over it?
Devs would typically treat context retrieval like a weekend project.
...and their approach would be: “Embed the data, store in a vector DB, and do RAG.”
This works beautifully for static sources.
But the problem is that no real-world workflow looks like this.
To understand better, consider this query:
What’s blocking the Chicago office project, and when’s our next meeting about it?
Answering this single query requires searching across sources like Linear (for blockers), Calendar (for meetings), Gmail (for emails), and Slack (for discussions).
No naive RAG setup can handle this!
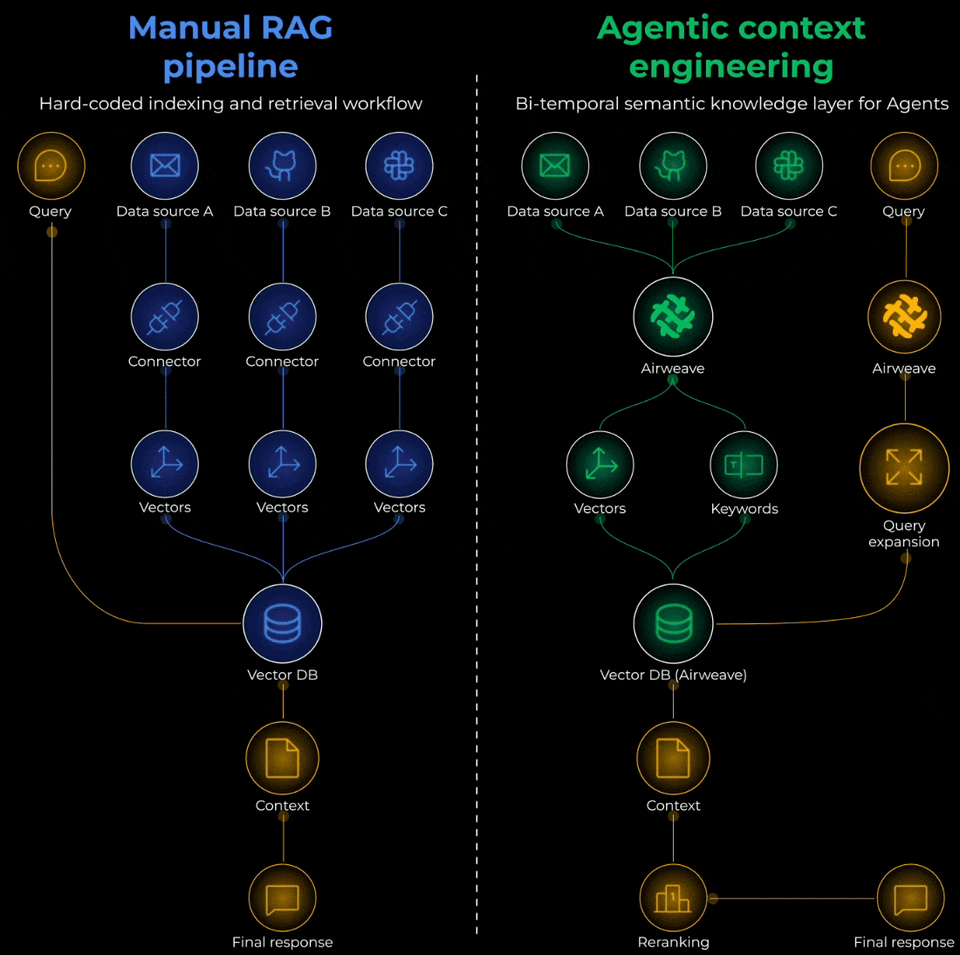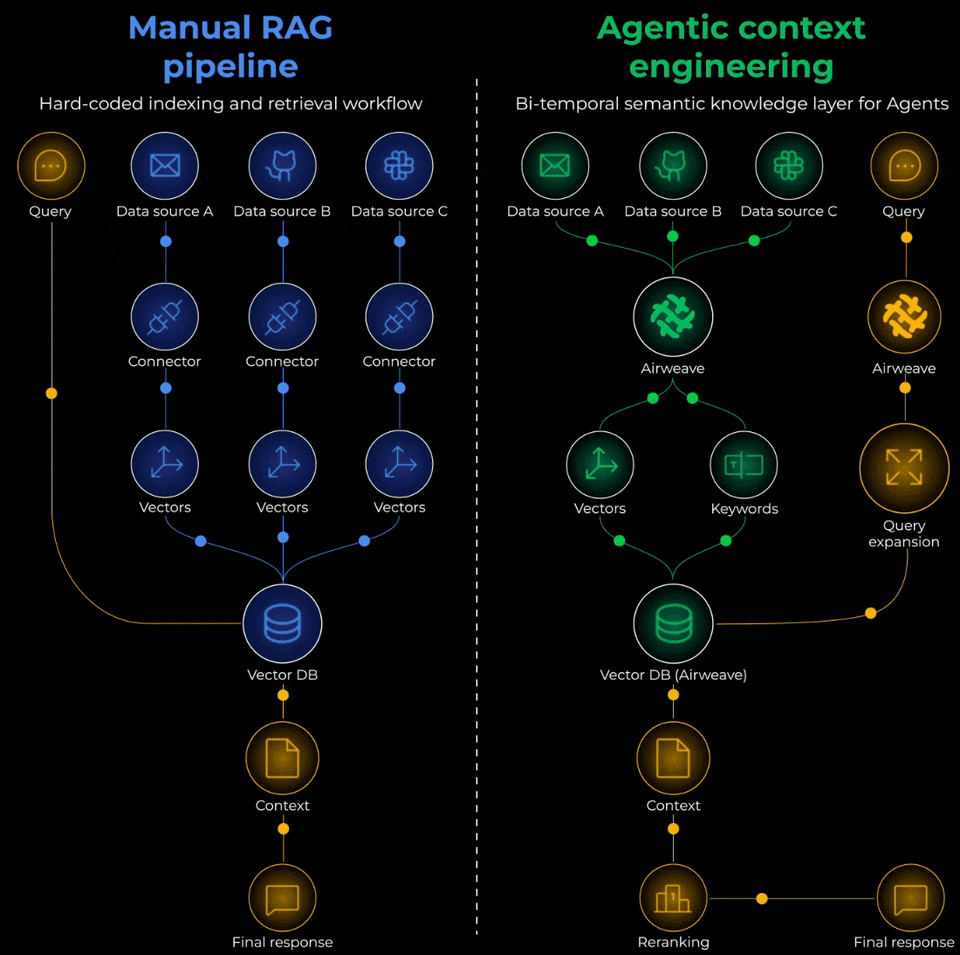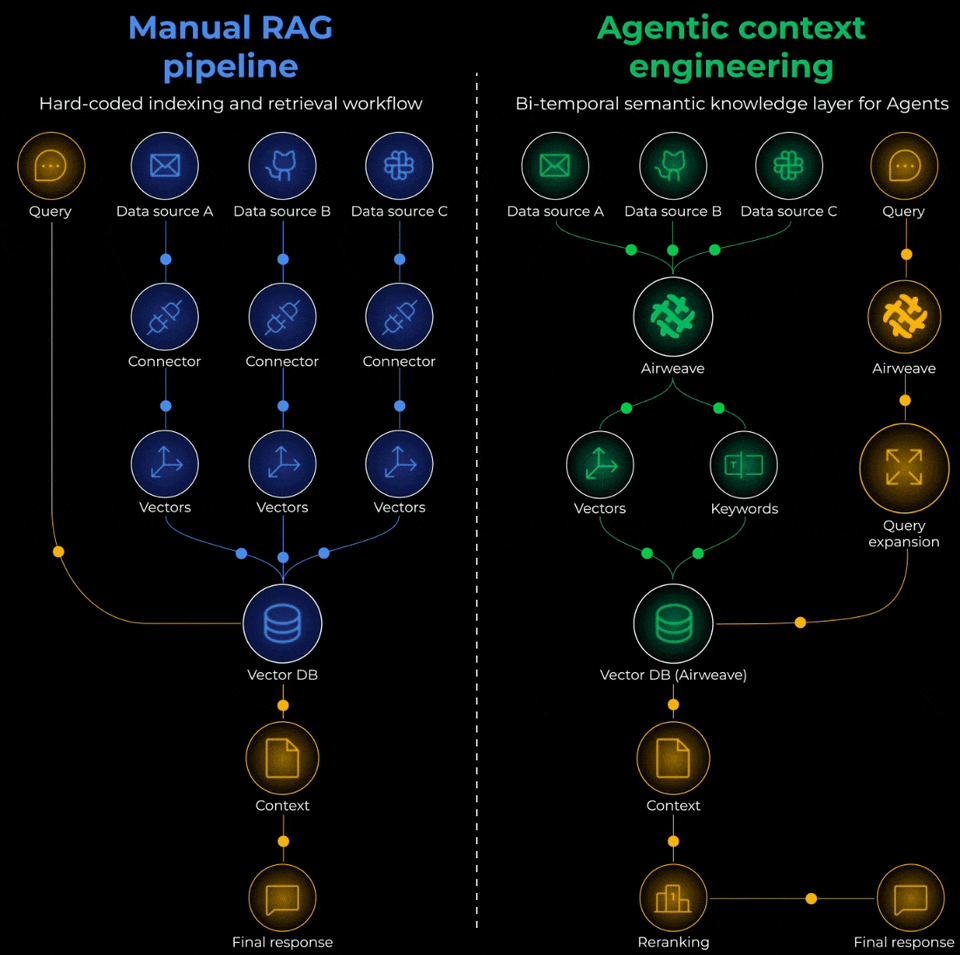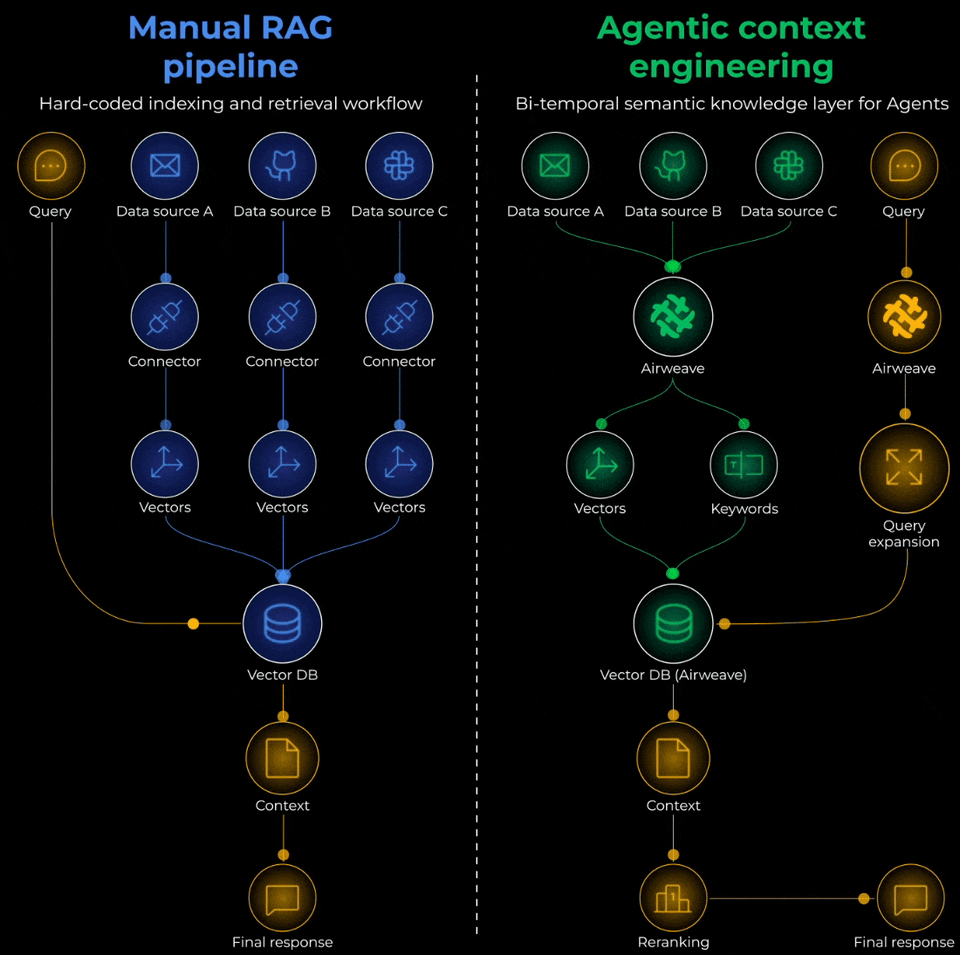
To actually solve this problem, you’d need to think of it as building an Agentic context retrieval system with three critical layers:
Ingestion layer:
Connect to apps without auth headaches.
Process different data sources properly before embedding (email vs code vs calendar).
Detect if a source is updated and refresh embeddings (ideally, without a full refresh).
Retrieval layer:
Expand vague queries to infer what users actually want.
Direct queries to the correct data sources.
Layer multiple search strategies like semantic-based, keyword-based, and graph-based.
Ensure retrieving only what users are authorized to see.
Weigh old vs. new retrieved info (recent data matters more, but old context still counts).
Generation layer:
Provide a citation-backed LLM response.
That’s months of engineering before your first query works.
It’s definitely a tough problem to solve...
...but this is precisely how giants like Google (in Vertex AI Search), Microsoft (in M365 products), AWS (in Amazon Q Business), etc., are solving it.
If you want to see it in practice, this approach is actually implemented in Airweave, a recently trending 100% open-source framework that provides the context retrieval layer for AI agents across 30+ apps and databases.

It implements everything we discussed above, like:
How to handle authentication across apps.
How to process different data sources.
How to gather info from multiple tools.
How to weigh old vs. new info.
How to detect updates and do real-time sync.
How to generate perplexity-like citation-backed responses, and more.
For instance, to detect updates and initiate a re-sync, one might do timestamp comparisons.

But this does not tell if the content actually changed (maybe only the permission was updated), and you might still re-embed everything unnecessarily.
Airweave handles this by implementing source-specific hashing techniques like entity-level hashing, file content hashing, cursor-based syncing, etc.
You can see the full implementation on GitHub and try it yourself.
But the core insight applies regardless of the framework you use:
Context retrieval for Agents is an infrastructure problem, not an embedding problem.
You need to build for continuous sync, intelligent chunking, and hybrid search from day one.
You can find the Airweave repo here →
Some time back, we recorded a live demo, where you can learn how to provide agents with a context retrieval layer that can search across any app, database, or document store in real time.
It seamlessly connects to tools like Notion, Google Drive, and SQL databases, transforming their contents into searchable knowledge.
The entire setup runs locally inside a Docker container on your machine.
You can also expose it via an API and an MCP server.
GitHub repo → github.com/airweave-ai/airweave (don’t forget to star it)
👉 Over to you: How would you solve this problem?
Thanks for reading!