
Markov Decision Processes and Value Functions in RL
The full RL nanodegree, covered with implementation.

Last week, we launched a hands-on course series on reinforcement learning.
Part 2 is now available, and you can read it here →
Part 1 gave you the RL interaction loop and the exploration-exploitation tradeoff through bandits, and this one gives you the formal language that every RL algorithm is built on.
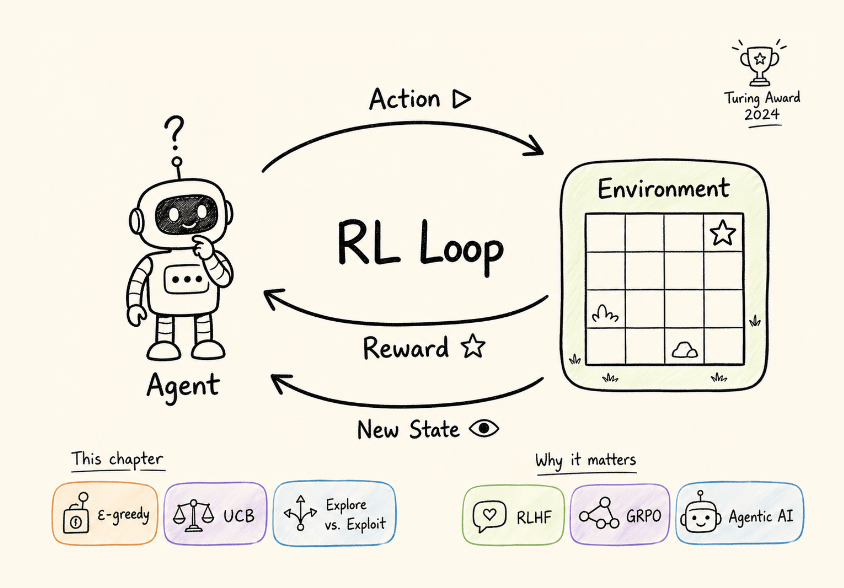
It covers:
the Markov property and why it makes RL tractable
the MDP as a 5-tuple (states, actions, transitions, rewards, discount factor)
episodic vs. continuing tasks
returns and discounting with concrete numerical examples
the reward hypothesis and its limits (including reward hacking),
deterministic and stochastic policies, state-value functions
and a complete hands-on implementation of Monte Carlo policy evaluation on a 4×4 gridworld.
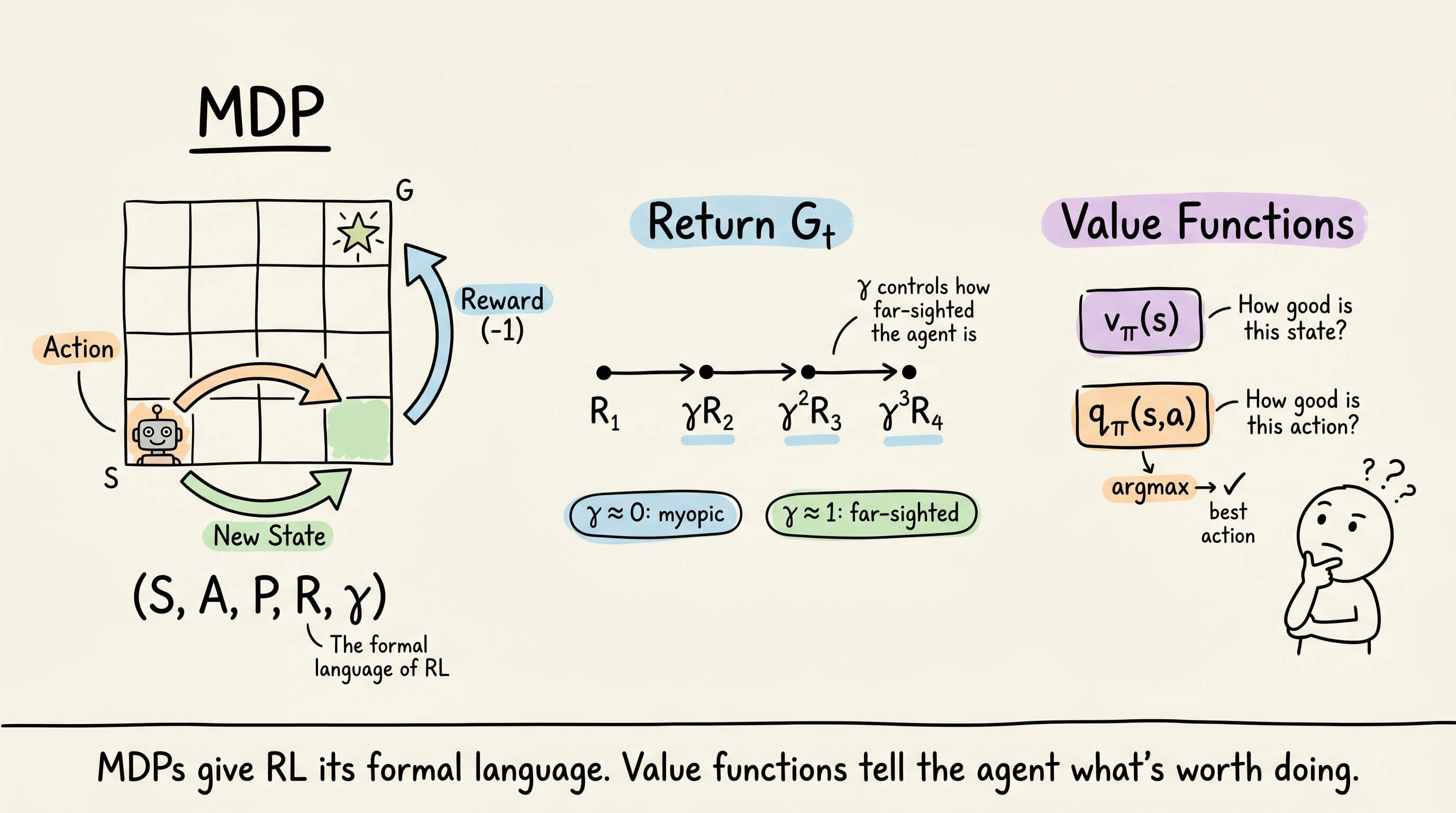
Everything is covered from scratch, so no RL background is required.
You can read Part 2 of the course here →
Why care?
Every frontier LLM released in the past two years uses RL in its post-training pipeline.
ChatGPT was shaped by RLHF.
DeepSeek-R1 used GRPO to develop reasoning capabilities.
Claude uses constitutional AI with RL.
The pattern is consistent: pre-training gives the model knowledge, but RL is what gives it behavior.
And it is not just LLMs.
Agentic AI systems that take actions, interact with tools, and operate in multi-step environments are fundamentally RL problems. Robotics, recommendation systems, game-playing, autonomous driving, drug discovery: RL is the common thread.
Google Trends for “reinforcement learning” was nearly flat from 2004 to 2023. In the past year, it hit an all-time high.
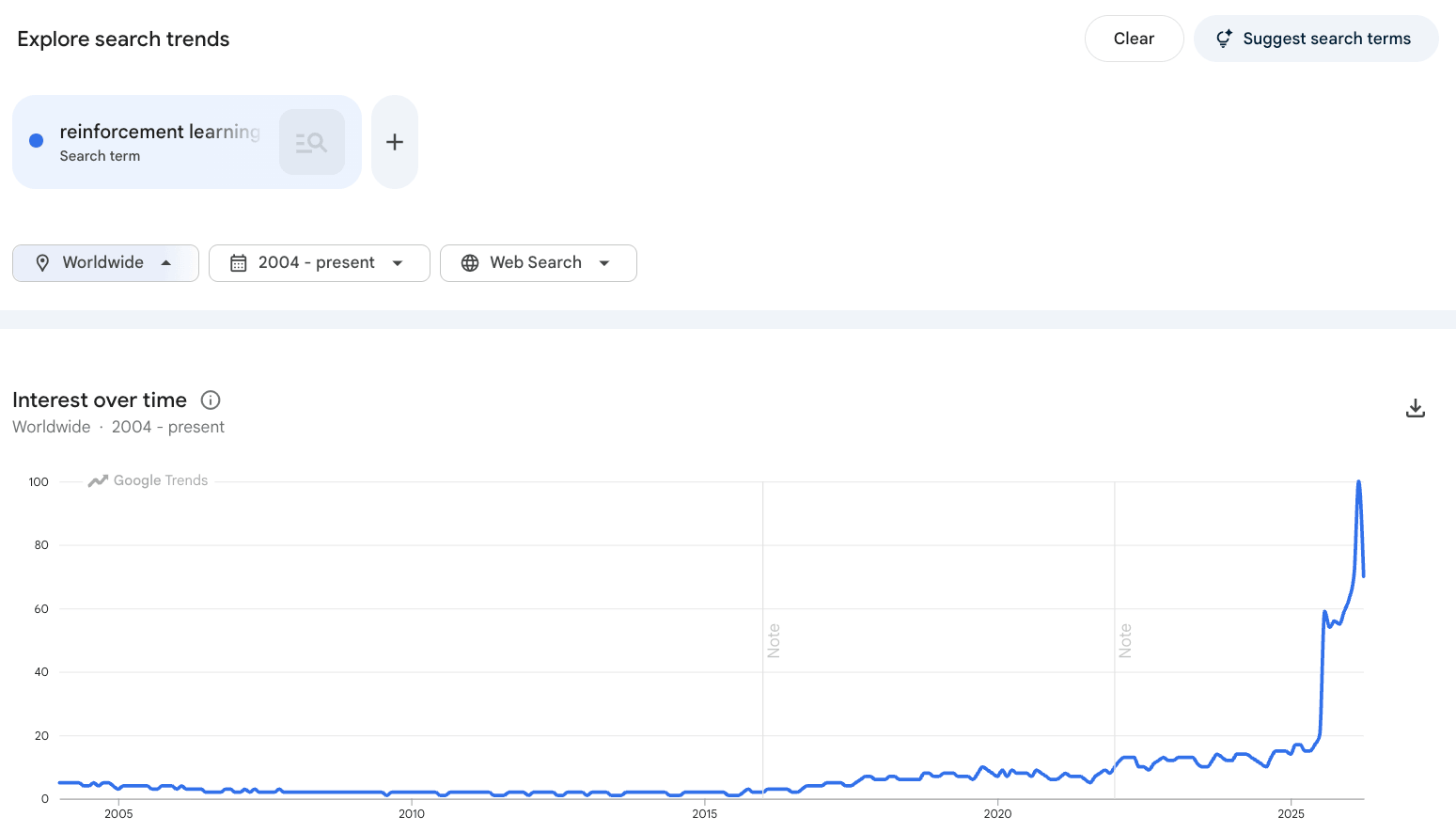
The field is having its moment, and the demand for engineers who understand it deeply is growing fast.
This series builds that understanding from the ground up, concept by concept, with math where it matters and hands-on code you can run. No prior RL background needed.
This series is structured the same way as our MLOps/LLMOps course: concept by concept, with clear explanations, diagrams, math where it matters, and hands-on implementations you can run.
And no prior RL background is needed.
If you haven’t read Part 1, start there first. It covers the agent-environment loop, exploration vs. exploitation, and multi-armed bandits.
Over to you: What topics would you like us to cover in this RL series?
Thanks for reading!