
Meet DBSCAN++: The Faster and Scalable Alternative to DBSCAN
Addressing major limitations of the most popular density-based clustering algorithm — DBSCAN.

Non-parametric unsupervised algorithms are widely used in industry to analyze large datasets.
This is because in many practical applications, gathering true labels is pretty difficult or infeasible.

In such cases:
Either data teams annotate the data, which can be practically impossible at times,
Or use unsupervised methods to identify patterns.
While KMeans is widely used here due to its simplicity and effectiveness as a clustering algorithm, it has many limitations:
It does not account for cluster covariance.
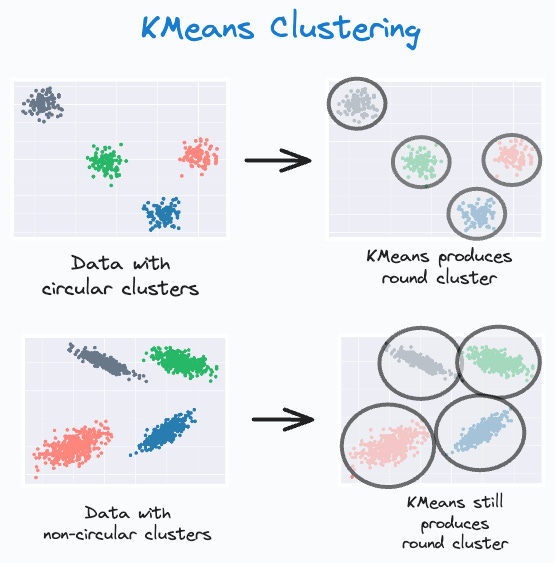
It can only produce spherical clusters. As shown below, even if the data has non-circular clusters, it still produces round clusters.

Density-based algorithms, like DBSCAN, quite effectively address these limitations.
The core idea behind DBSCAN is to group together data points based on “density”, i.e., points that are close to each other in a high-density region and are separated by lower-density regions.

But unfortunately, with the use of DBSCAN, we again run into an overlooked problem.
One of the things that makes DBSCAN infeasible to use at times is its run-time.
Until recently, it was believed that DBSCAN had a run-time of O(nlogn), but it was proven to be O(n²) in the worst case.
In fact, this can also be verified from the figure below. It depicts the run-time of DBSCAN with the number of samples:

It is clear that DBSCAN has a quadratic relation with the dataset’s size.
Thus, there is an increasing need to establish more efficient versions of DBSCAN.
DBSCAN++ is a major step towards a fast and scalable DBSCAN.
Simply put, DBSCAN++ is based on the observation that we only need to compute the density estimates for a subset “m” of the “n” data points in the given dataset, where “m” can be much smaller than “n” to cluster properly.
The effectiveness of DBSCAN++ is evident from the image below:

On a dataset of 60k data points:
DBSCAN++ is 20x faster than DBSCAN.
DBSCAN++ produces better clustering scores than DBSCAN.
But how does it work end-to-end?
Why selecting a subset of data points is still effective?
What strategies can we use to select a subset of data points?
What other limitations does DBSCAN++ address?
DBSCAN++ is a new algorithm. So what are the things to keep in mind to use it effectively?
If you are curious, then the most recent machine learning deep dive talks exactly about this: DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering

Most real-world datasets are unsupervised and inherently quite large in size:
KMeans is typically not useful because of the strict assumptions stated above.
DBSCAN can work, but it will suffer from run-time.
As a result, awareness about algorithms like DBSCAN++ becomes pretty crucial.
Of course, I know that many of you might not have a clear understanding of DBSCAN itself.
So I have provided a detailed overview of DBSCAN as well, which serves as a natural buildup for DBSCAN++.
Also, one issue with DBSCAN++ is that it is not integrated into Sklearn.
But don’t worry.
For this article, I wrote an entirely vectorized implementation of DBSCAN++, which is linked in the article and you can use it in your projects.
Read it here: DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering.
I am sure that learning about DBSCAN++ will be extremely valuable to your skillset and projects :)
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Loved the content and its simplicity to be explained!
Educational Journey!