
Memory Pinning to Accelerate Model Training
A simple technique, and some key considerations.

If you regularly use GPUs to accelerate model training, then today, let me show you a pretty simple technique I often use to accelerate model training.
…And by changing just two lines of code.
Let’s begin!
Consider the standard model training loop in PyTorch, as shown below:

In the above code:
Line 5 transfers the data to the GPU from the CPU.
Everything executes on the GPU after the data transfer, i.e., lines 7-15.
This means when the GPU is working, the CPU is idle, and when the CPU is working, the GPU is idle, as depicted below:

But here’s what we can do to optimize this:
When the model is being trained on the 1st mini-batch, the CPU can transfer the 2nd mini-batch to the GPU.
This ensures that the GPU does not have to wait for the next mini-batch of data as soon as it completes processing an existing mini-batch.
Thus, the resource utilization chart will look something like this:
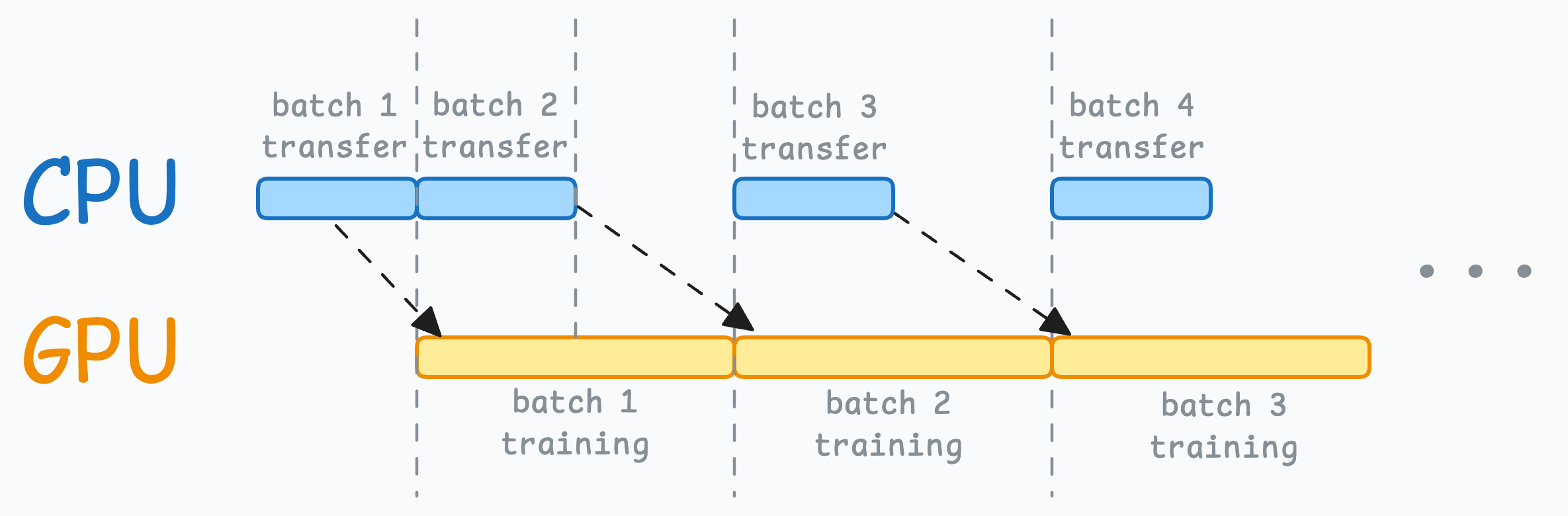
While the CPU may remain idle, this process ensures that the GPU (which is the actual accelerator for our model training) always has data to work with.
Formally, this process is known as memory pinning, and it is used to speed up the data transfer from the CPU to the GPU by making the training workflow asynchronous.
This allows us to prepare the next training mini-batch in parallel to training the model on the current mini-batch.
Enabling this is quite simple in PyTorch.
Firstly, when defining the DataLoader object, set pin_memory=True and specify num_workers.

Next, during the data transfer step in the training step, specify non_blocking=True, as depicted below:

Done!
The speedup on the MNIST dataset with a simple neural network is depicted below:
Without memory pinning, the model takes about 43 seconds to train on 5 epochs.

But with memory pinning, the same model trains in less than 10 seconds:

Isn’t that impressive?
That said, one of the things that you need to be cautious about when using memory pinning is if several tensors (or big tensors) are allocated to the pinned memory, it will block a substantial portion of your RAM.
As a result, the overall memory available to other operations will be negatively impacted.
So whenever I use memory pinning, I profile my model training procedure to track the memory consumption.
Also, when the dataset is quite small (or tensors are small), I have observed that memory pinning has negligible effect since the data transfer from the CPU to the GPU does not take that time anyway:

I intend to cover the underlying details of memory pinning and how it exactly works in another issue soon.
👉 Over to you: What are some other ways to optimize model training?
One way is multi-GPU training, which we covered here:: A Beginner-friendly Guide to Multi-GPU Model Training.
Also, here’s an article that teaches CUDA programming from scratch, which will help you understand the underlying details of CUDA and how it works: Implementing (Massively) Parallelized CUDA Programs From Scratch Using CUDA Programming.
For those who want to build a career in DS/ML on core expertise, not fleeting trends:
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
Quantization: Optimize ML Models to Run Them on Tiny Hardware
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 88,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.