
Memory Pinning to Accelerate Model Training
A simple technique, and some key considerations.

A web browser for your AI
Browserbase powers web browsing capabilities for AI agents and applications.
If you’re building automations that need to interact with websites, fill out forms, or replicate users’ actions, Browserbase manages that infrastructure so you don’t have to maintain your fleet of headless browsers.

With the excitement of Open AI's new Computer Using Agent API, Browserbase has built an open-source version of this toolkit—CUA Browser, for you to try out yourself.
Supercharge your CUA with Browserbase's reliable, scalable browser infrastructure, and sign up for free.
Thanks to Browserbase for partnering on today’s issue.
Memory Pinning to accelerate model training
If you regularly use GPUs to accelerate model training, let us show you a simple technique to accelerate model training…
…by changing just two lines of code.
Let’s begin!
Here’s how we typically train a neural network using PyTorch:

Line 5 transfers the data to the GPU from the CPU.
Everything executes on the GPU after the data transfer, i.e., lines 7-15.
This means:
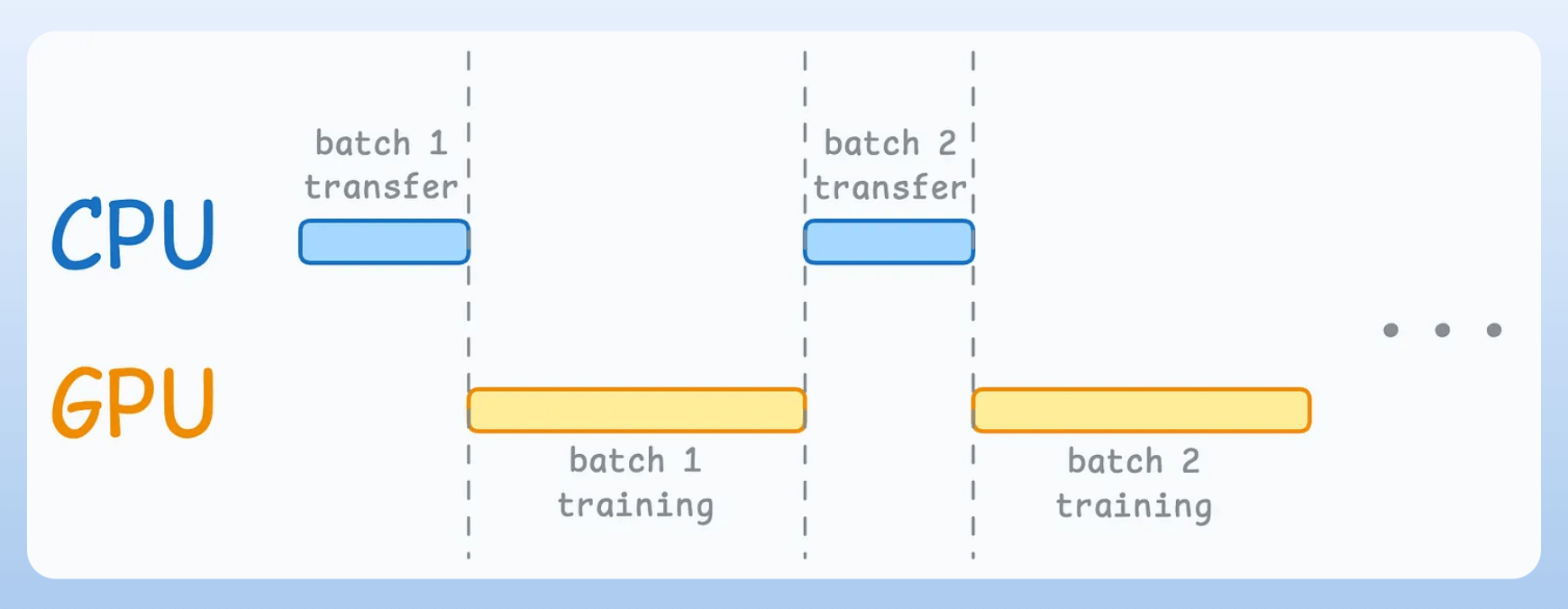
When the GPU is working, the CPU is idle,
And when the CPU is working, the GPU is idle.
This can be optimized as follows:
When the model is being trained on the 1st mini-batch, the CPU can transfer the 2nd mini-batch to the GPU.
This ensures that the GPU does not have to wait for the next mini-batch as soon as it has processed the current mini-batch.
Thus, the resource utilization chart should look like:
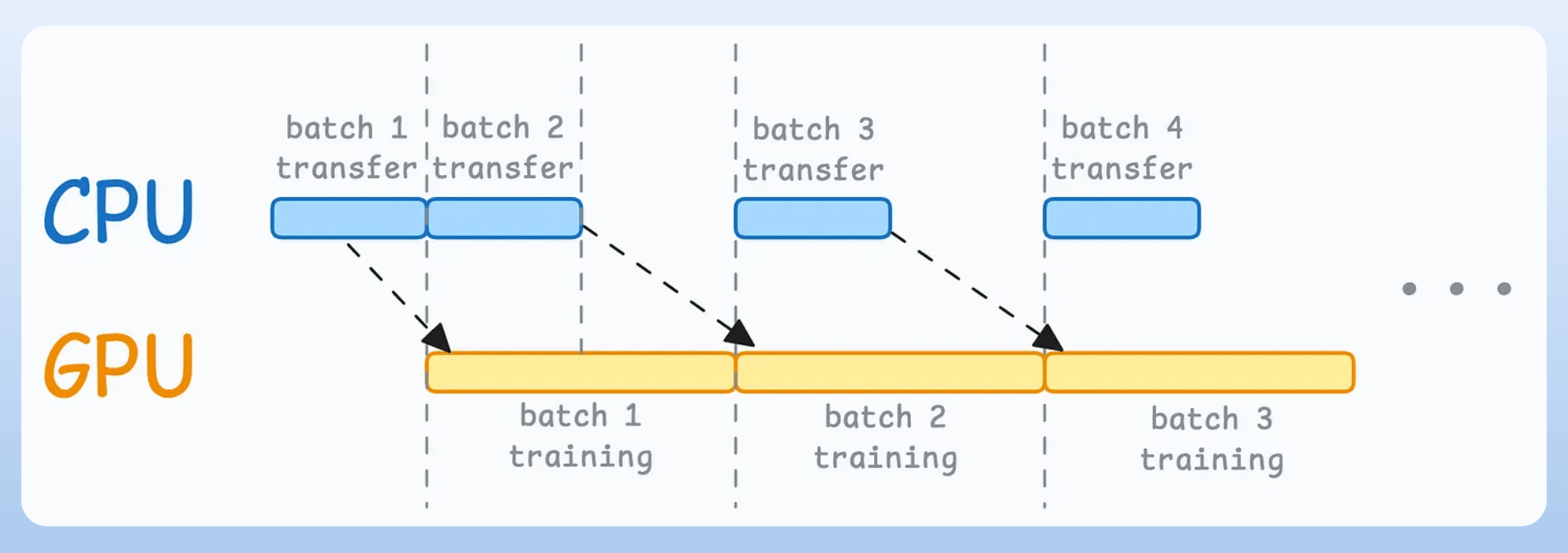
While the CPU may remain idle, this ensures that the GPU (which is the actual accelerator) is never idle.
This is known as memory pinning, and it is used to speed up the data transfer from the CPU to the GPU by making the training workflow asynchronous.
Enabling this is quite simple in PyTorch.
1) First, when defining the DataLoader object, set pin_memory=True and specify num_workers.

2) During the data transfer step in the training step, specify non_blocking=True, as depicted below:
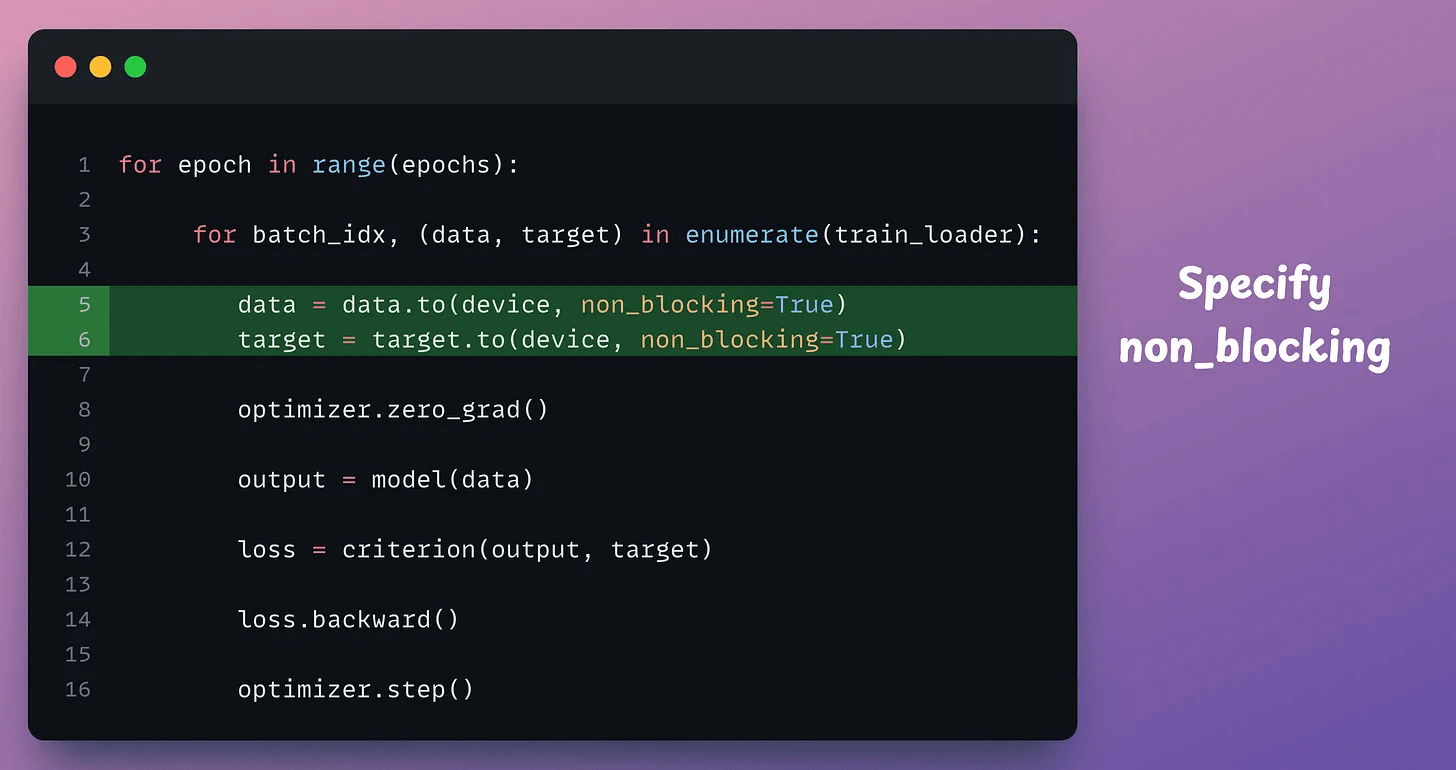
Done!
The speedup with a simple neural network is depicted below:
Without memory pinning, the model takes 43 seconds to train on 5 epochs.

But with memory pinning, the same model trains in less than 10 seconds:

That said, remember that if several tensors are allocated to the pinned memory, it will block a substantial portion of RAM.
This impacts the memory available to other operations. Thus, always profile your code to track the memory consumption.
Also, if the tensors are small, memory pinning has a negligible effect since the data transfer from the CPU to the GPU does not take that time anyway:

👉 Over to you: What are some other ways to optimize model training?
One way is multi-GPU training, which we covered here: A Beginner-friendly Guide to Multi-GPU Model Training.
And here are 15 more ways to optimize neural network training: 15 Ways to Optimize Neural Network Training (With Implementation).
Lastly, here’s an article that teaches CUDA programming from scratch, which will help you understand the underlying details of CUDA and how it works: Implementing (Massively) Parallelized CUDA Programs From Scratch Using CUDA Programming.
Thanks for reading!