
MiniMax-M2 vs. Kimi-K2 vs. Sonnet 4.5 on Code Generation
+ A big moment for Postgres!

Big moment for Postgres!
AI agents broke the idea of what a database is supposed to do.
Traditional databases were built for humans, and Agents broke that model.
They branch endlessly.
They run ten experiments at once.
They need isolation, context, memory, structured reasoning, and safe sandboxes.
Letting agents touch production systems is terrifying because the old model of Postgres was never built for this kind of behavior.
Agentic Postgres is an agent-ready version of Postgres by Tiger Data that solves this.
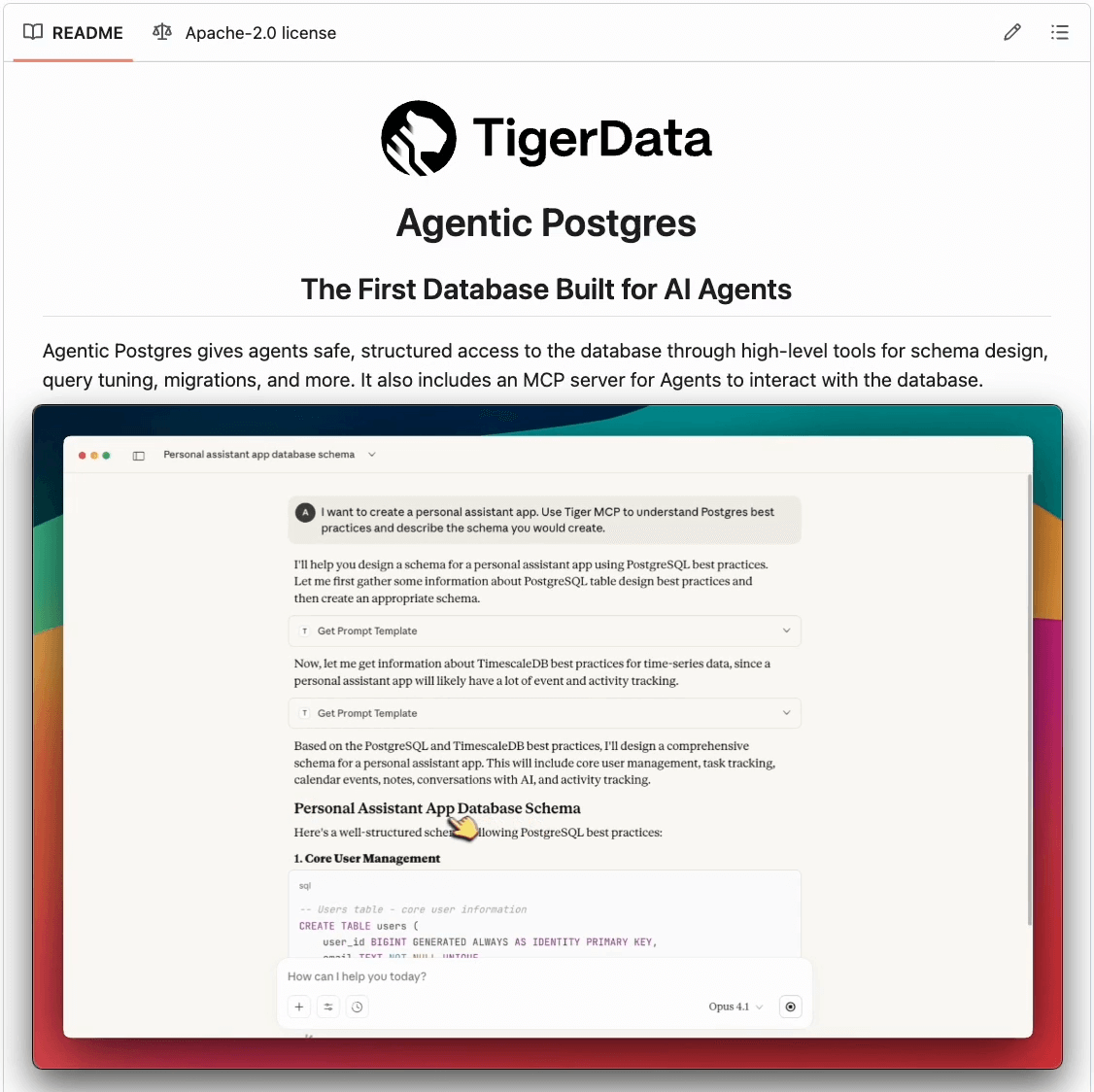
Some key features:
It instantly creates branches of an entire database, which is perfect for parallel agent evals, safe experiments, migrations, or isolated testing. Forks take seconds and cost almost nothing.
It comes with a built-in MCP server, which agents can use to get schema guidance, best practices, and safe, structured access to Postgres. This is also helpful to run migrations with a real understanding.
It comes with actual hybrid search (vector search and BM25), so Agents can retrieve data directly inside the database.
The database is Memory native. This gives a persistent context for Agents to evolve.
This is one of the first times we have seen Postgres feel ready for the AI native era.
You can try Agentic Postgres here →
Thanks to Tiger Data for partnering today!
MiniMax-M2 vs. Kimi-K2 vs. Sonnet 4.5 on Code Generation
Nobody wants to send their data to OpenAI or Google. Full Stop.
Yet here we are, shipping proprietary code, customer information, and sensitive business logic to closed-source APIs we don’t control.
While everyone’s chasing the latest closed-source releases, open-source models are quietly becoming the practical choice for production systems.
Here’s what everyone is missing:
Open-source models are catching up fast, and they bring something the big labs can’t: privacy, speed, and control.
We built a playground to test this:
We used CometML’s Opik to evaluate models on real code generation tasks - testing correctness, readability, and best practices against actual GitHub repos.
Some observations:
OSS models like MiniMax-M2, Kimi k2 performed on par with the likes of Gemini 3 and Claude Sonnet 4.5 on most tasks.
Practically, Minimax M2 turns out to be a winner as it’s twice as fast and costs 8% of the price when you compare it to models like Sonnet 4.5.
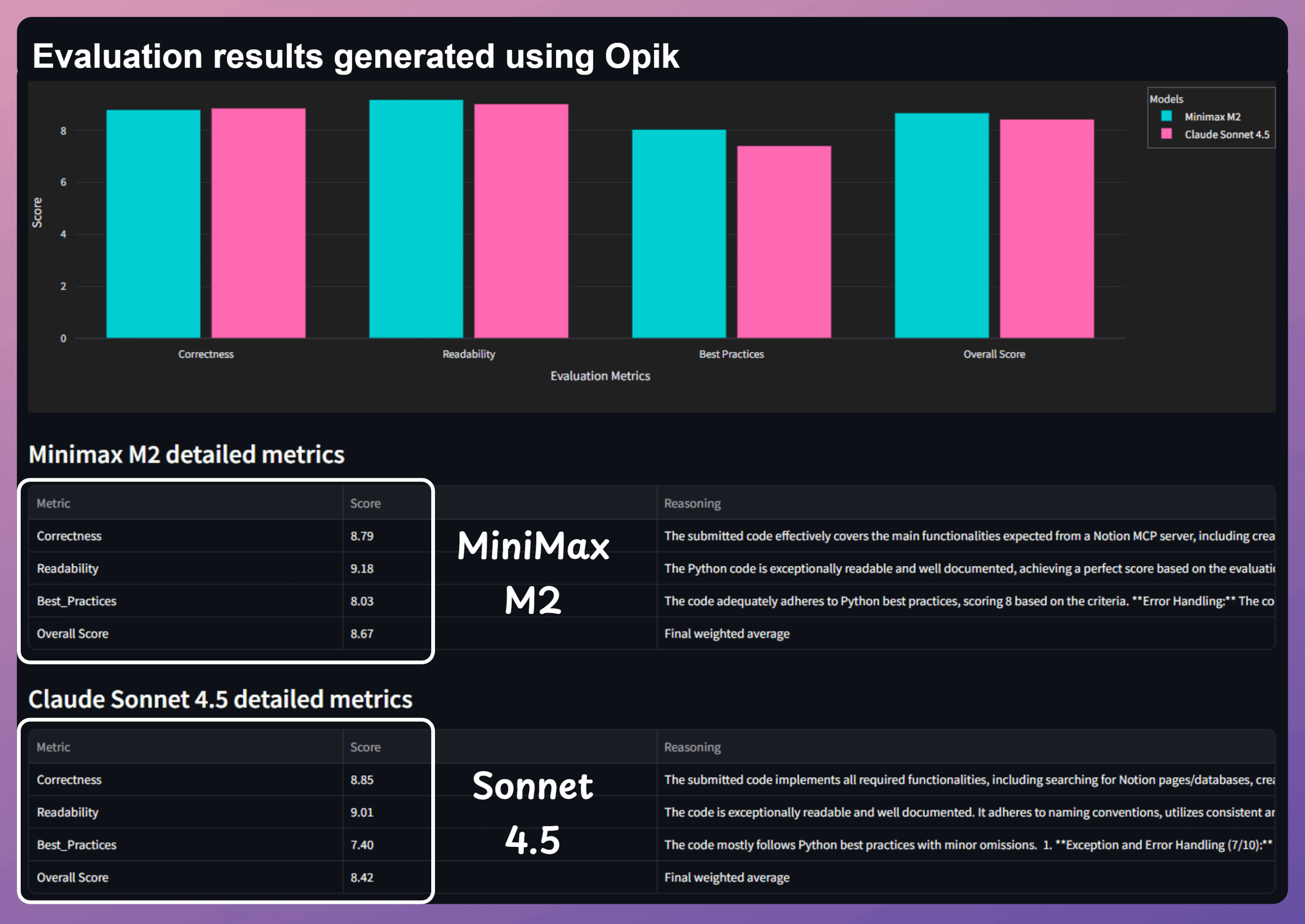
This isn’t just about saving money, since when your model is smaller and faster, you can deploy it in places closed-source APIs can’t reach:
↳ Real-time applications that need sub-second responses
↳ Edge devices where latency kills user experience
↳ On-premise systems where data never leaves your infrastructure
MiniMax-M2 runs with only 10B activated parameters. That efficiency means lower latency, higher throughput, and the ability to handle interactive agents without breaking the bank.
The intelligence-to-cost ratio here changes what’s possible.
If you’re building anything that needs to be fast, private, or deployed at scale, it’s worth taking a look at what’s now available.
MiniMax-M2 is open-source and free for developers.
Find the MiniMax-M2 GitHub repo here →
Find the code for the playground and evaluations we’ve done →
Should you gather more data?
At times, no matter how much you try, the model performance barely improves:
Feature engineering gives a marginal improvement.
Trying different models does not produce satisfactory results either.
and more…
This is usually an indicator that we don’t have enough data to work with.
But since gathering new data can be a time-consuming and tedious process...
...here’s a technique to determine whether more data will help:
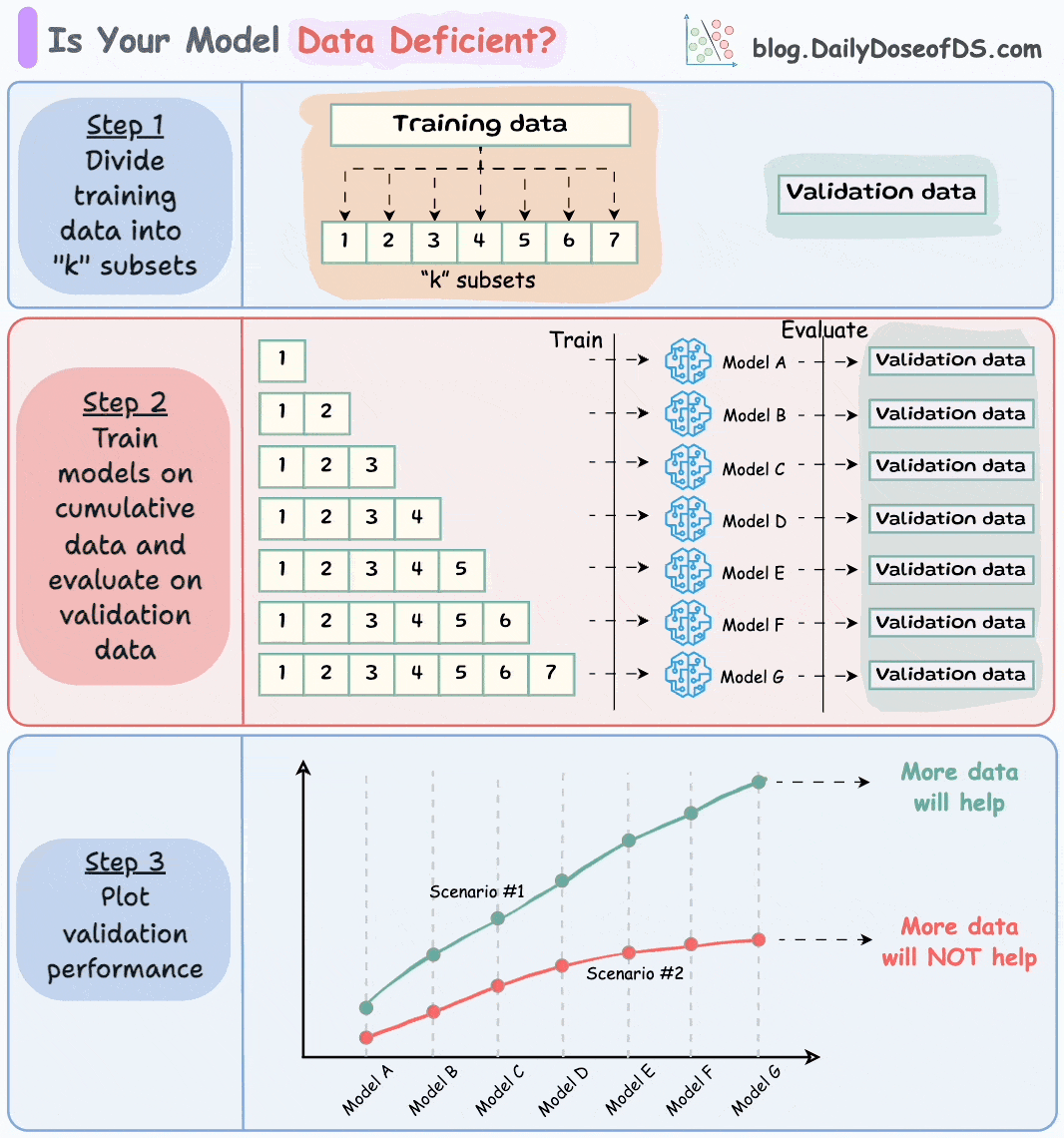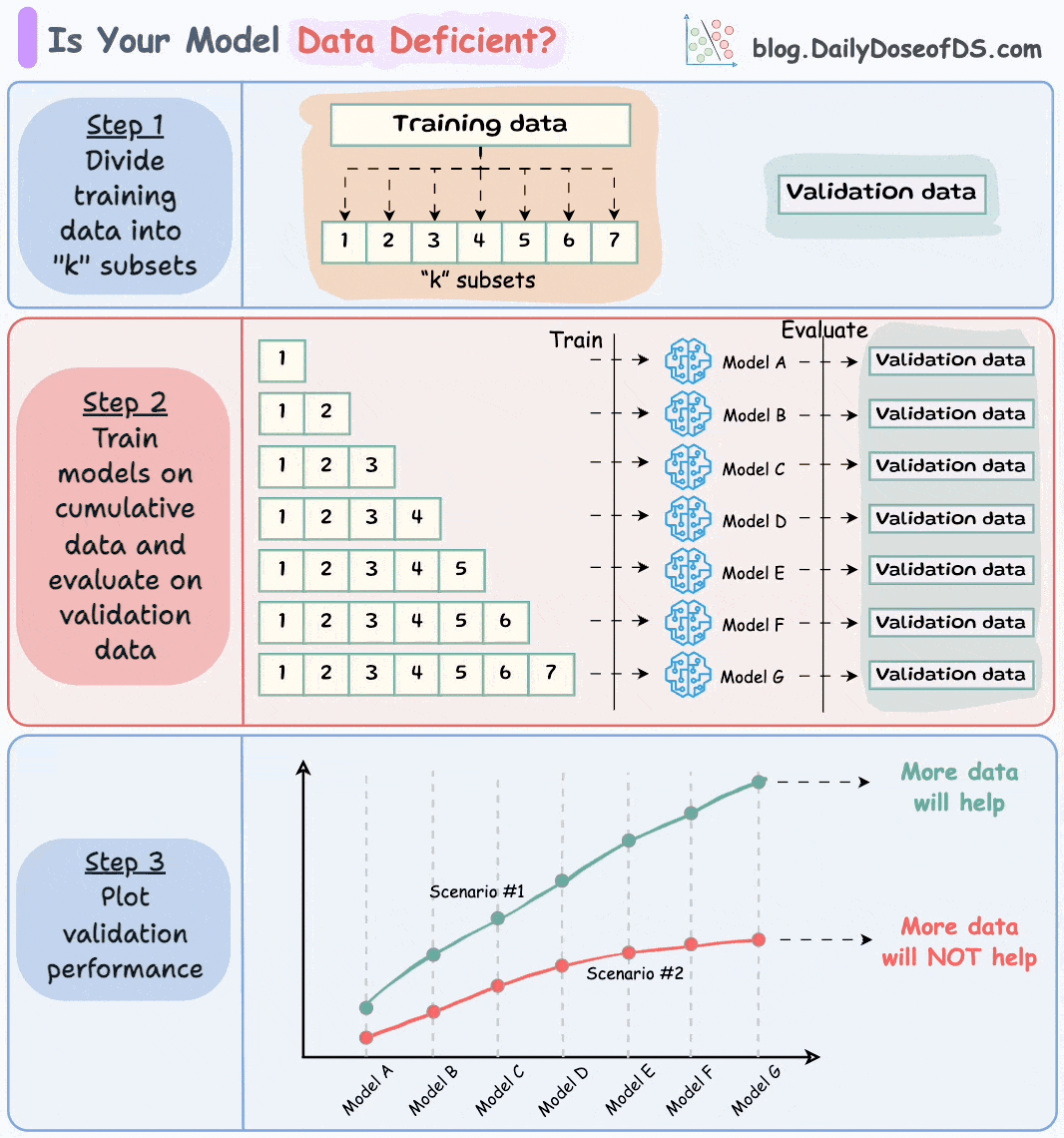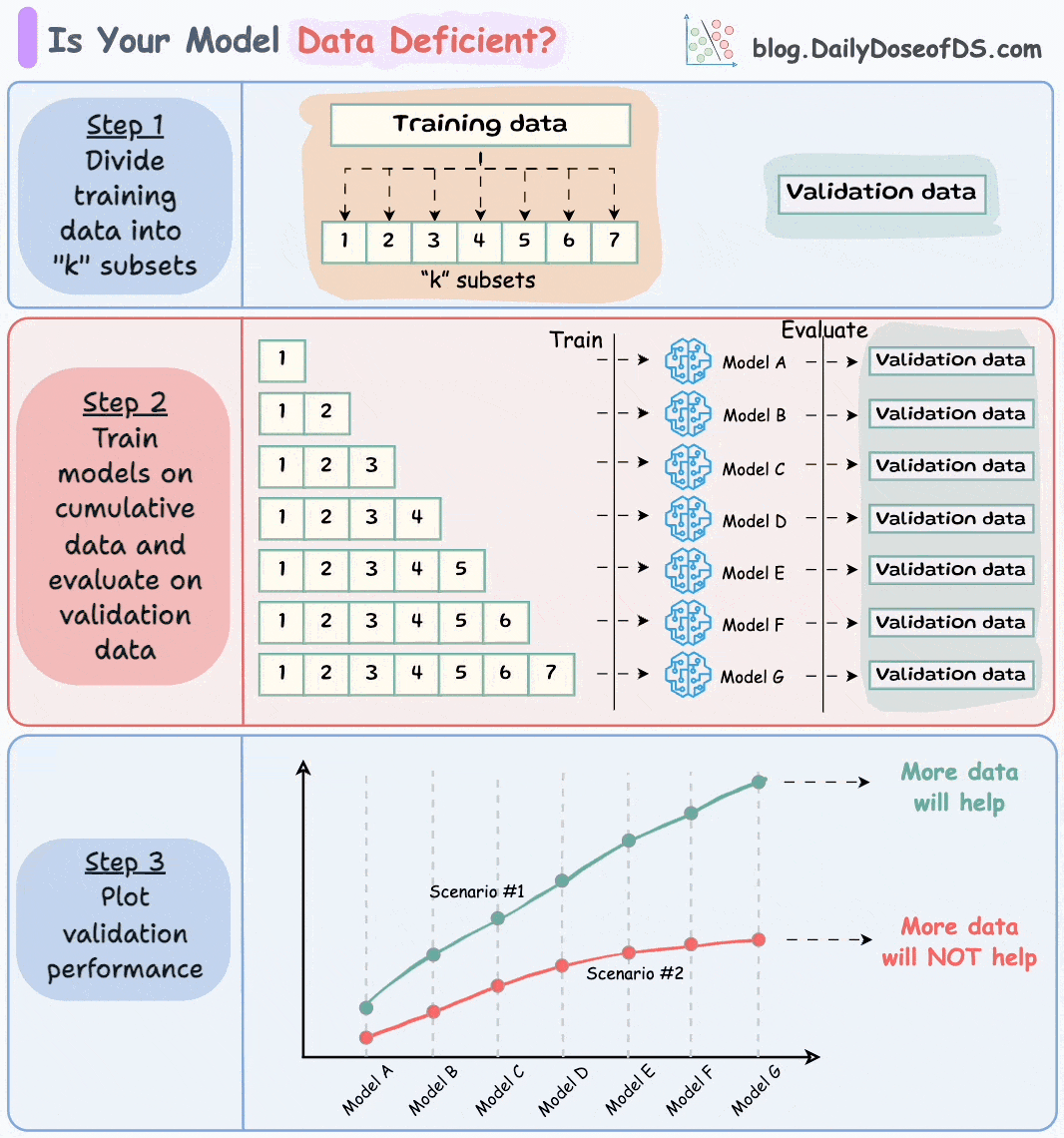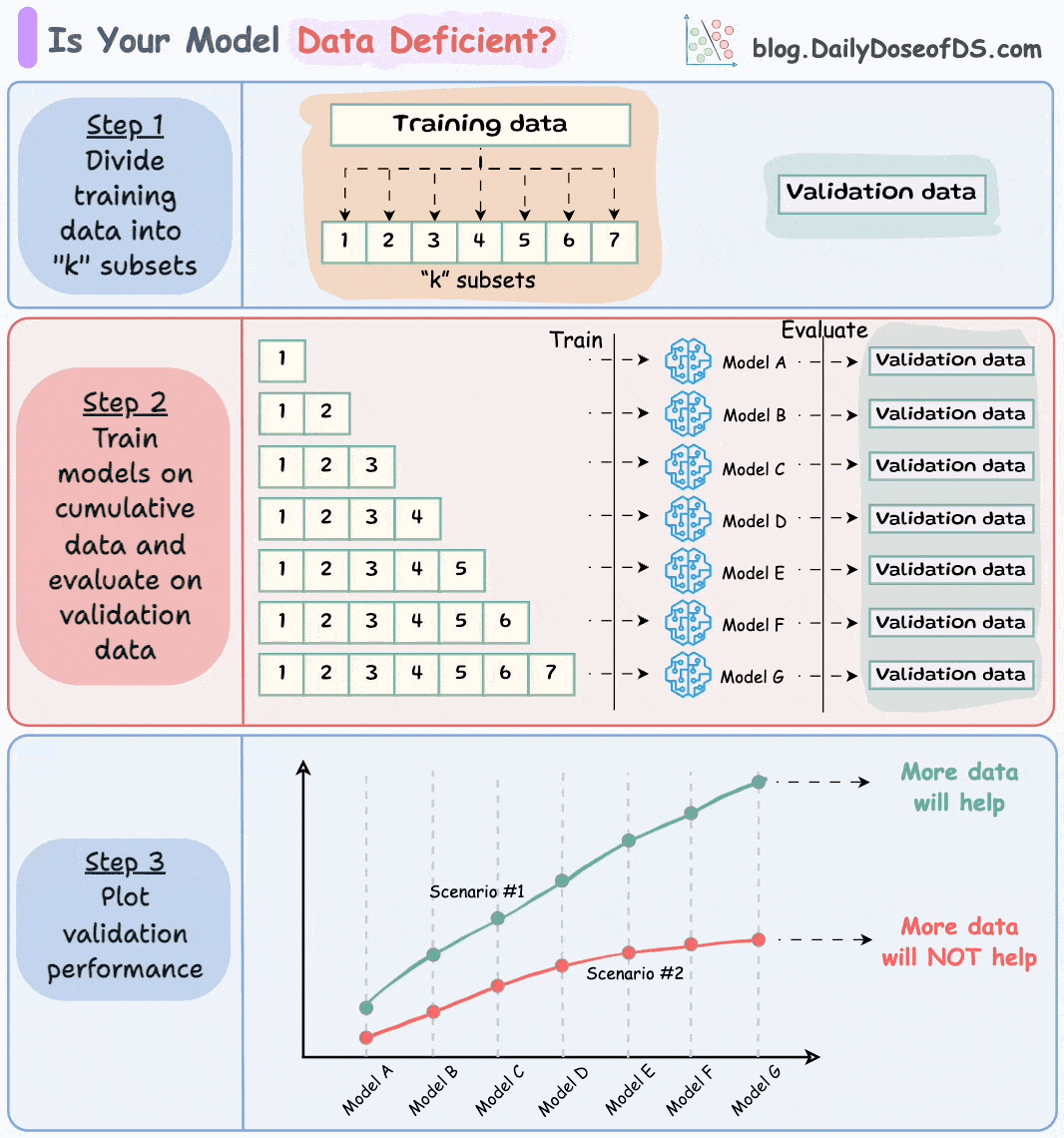
Divide the dataset into “k” equal parts. Usually, 7 to 12 parts are fine.
Train models cumulatively on the above subsets and measure the performance on the validation set:

Train a model on the first subset only.
Train a model on the first two subsets only.
And so on…
Plotting the validation performance will produce one of these two lines:
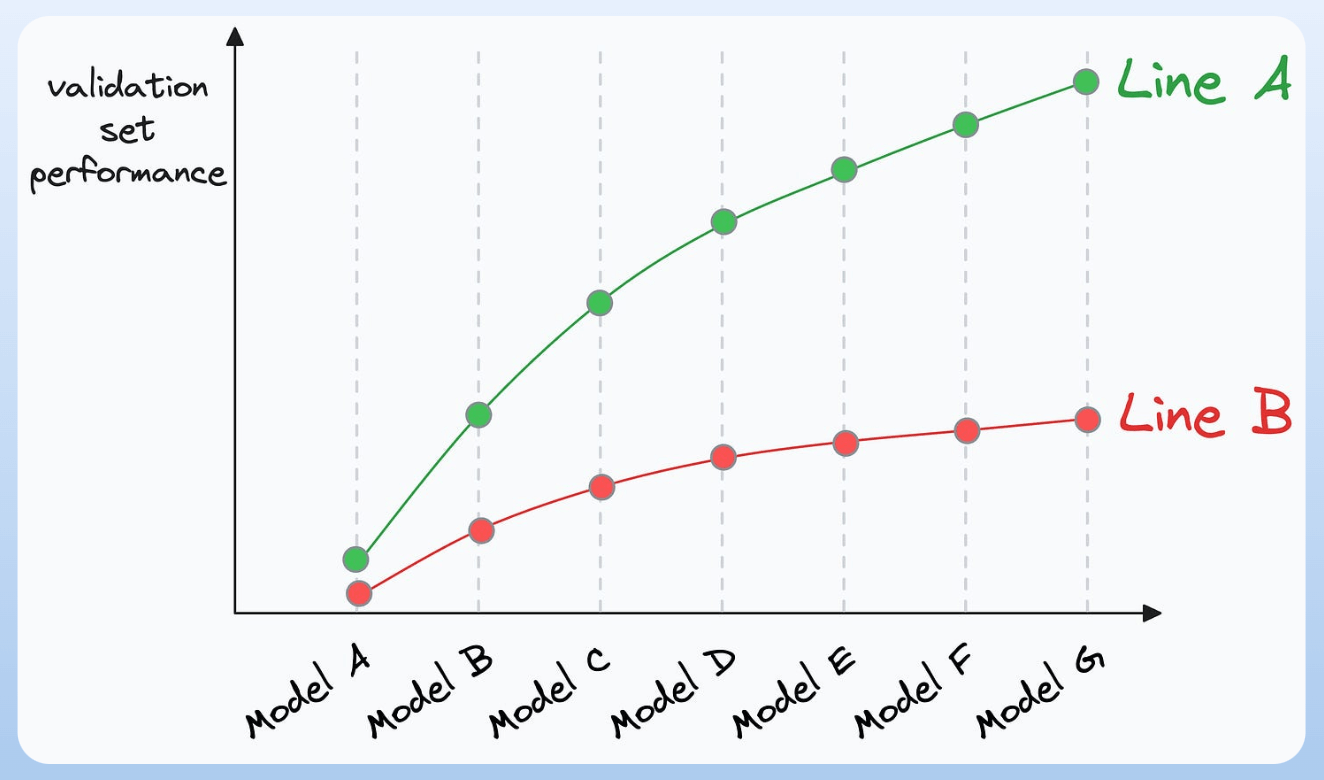
Line A conveys that adding more data will likely increase the model’s performance.
Line B conveys that the model’s performance has already saturated. Adding more data will most likely not result in any considerable gains.
This way, you can ascertain whether gathering data will help.
Thanks for reading!