
MiniMax M2.7: The self-refactoring Agent architecture
AI that improves without retraining!

Run NVIDIA’s latest 120B model on Lightning AI

NVIDIA Nemotron 3 Super is live on Lightning AI, and you can run it today without setting up a single server.
Nemotron 3 Super is a hybrid MoE reasoning model with open weights.
That means teams can keep full control, without any vendor lock-in.
You can claim your 30M free tokens per month without any credit card →.
Thanks to Lightning AI for partnering today!
MiniMax M2.7: The self-refactoring Agent architecture
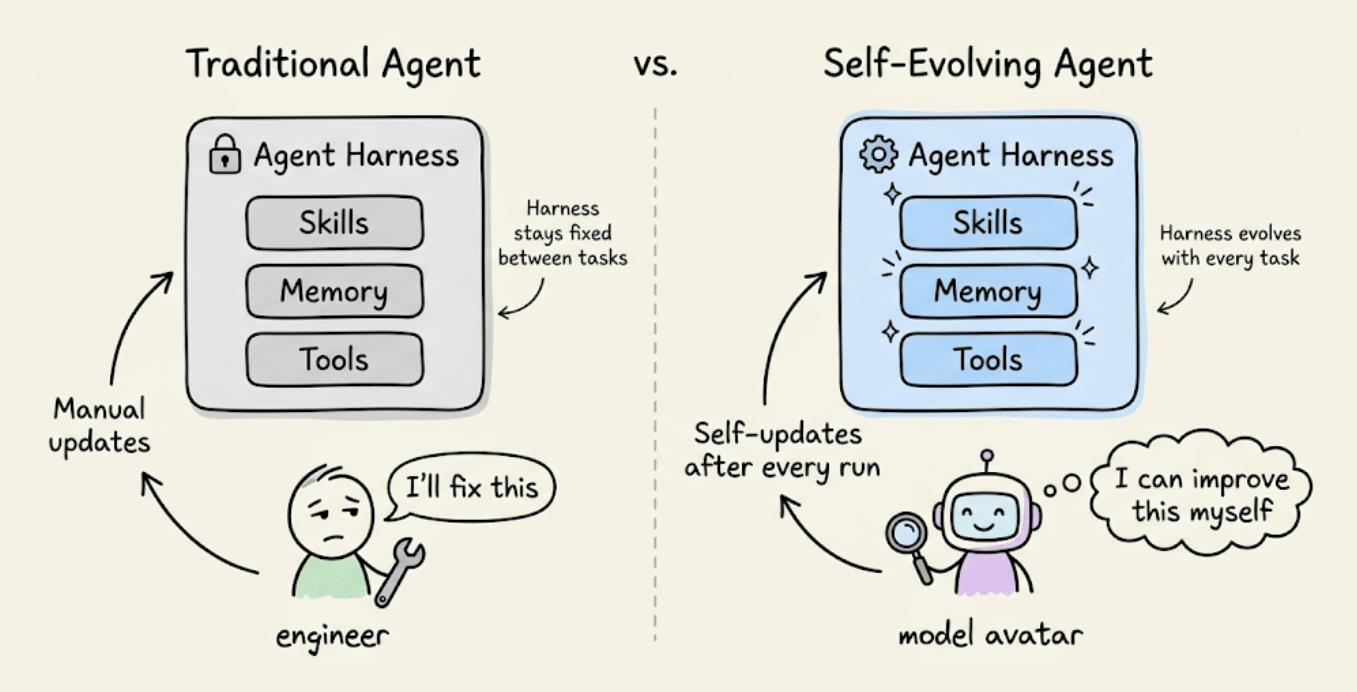
Most AI models today are deployed as static artifacts.
Devs train them, ship them, and they operate inside a fixed environment: a set of skills, tools, memory, and workflow rules called an “agent harness.”
If something is slow or brittle, a human engineer steps in and fixes the scaffold. The model itself never touches it.
MiniMax’s M2.7 treats its harness as something it can rewrite autonomously.
How M2.7 rewrites its own scaffold
Every AI agent operates inside a scaffold that defines the tools it can call, the skills it can invoke, the memory it retains, and the workflow rules it follows.
M2.7 closes the human-in-the-loop bottleneck by running a self-optimization cycle. Here, the model runs a task, analyzes where things broke, plans changes to its own scaffold (skills, memory, workflow rules), applies those changes, evaluates the results against a benchmark, and decides whether to keep or revert.
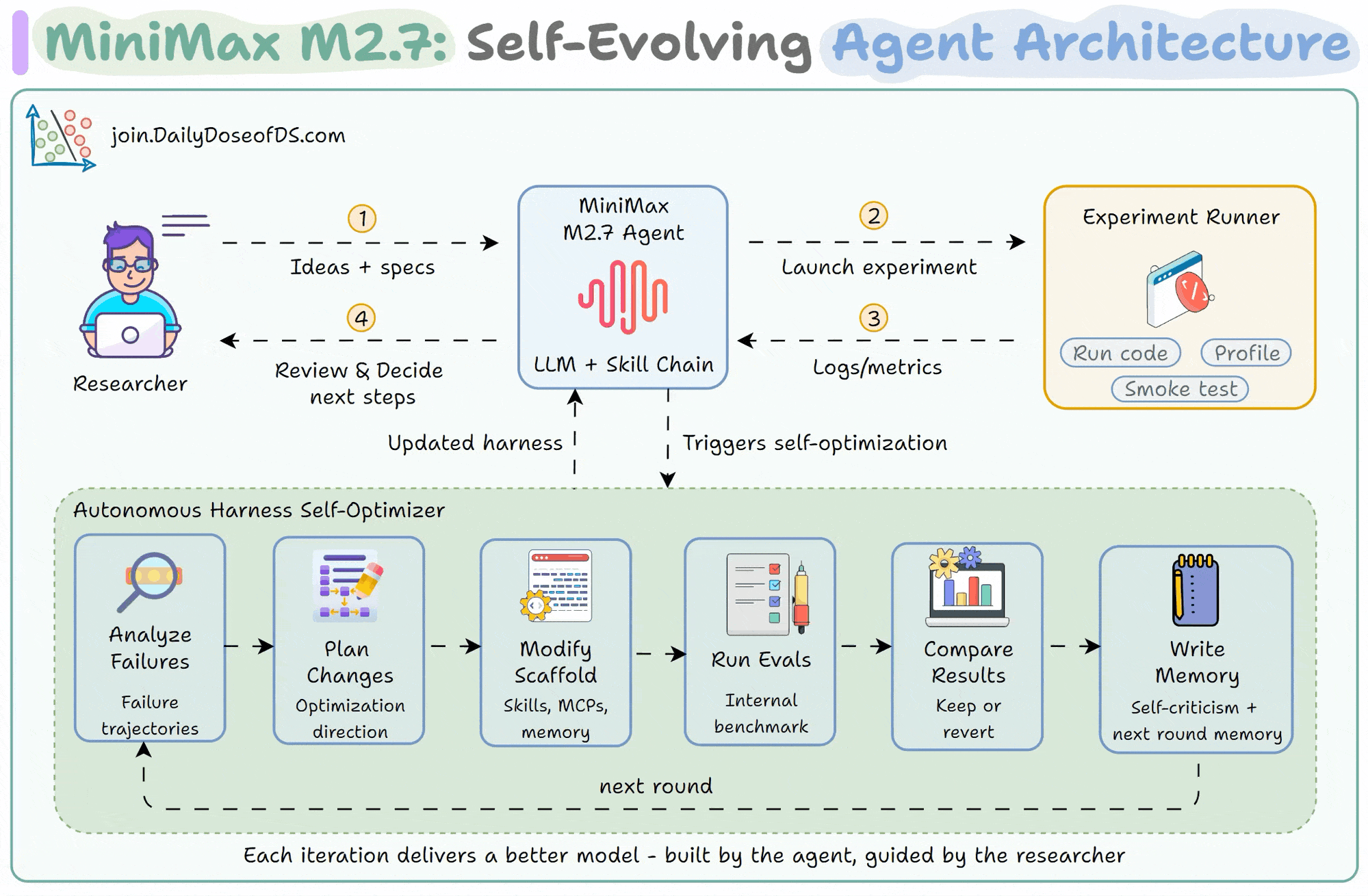
It then writes self-criticism into memory so the next iteration starts with accumulated lessons.
MiniMax ran this loop for over 100 rounds internally. Over those rounds, M2.7 discovered optimizations on its own that no human had instructed.
For instance:
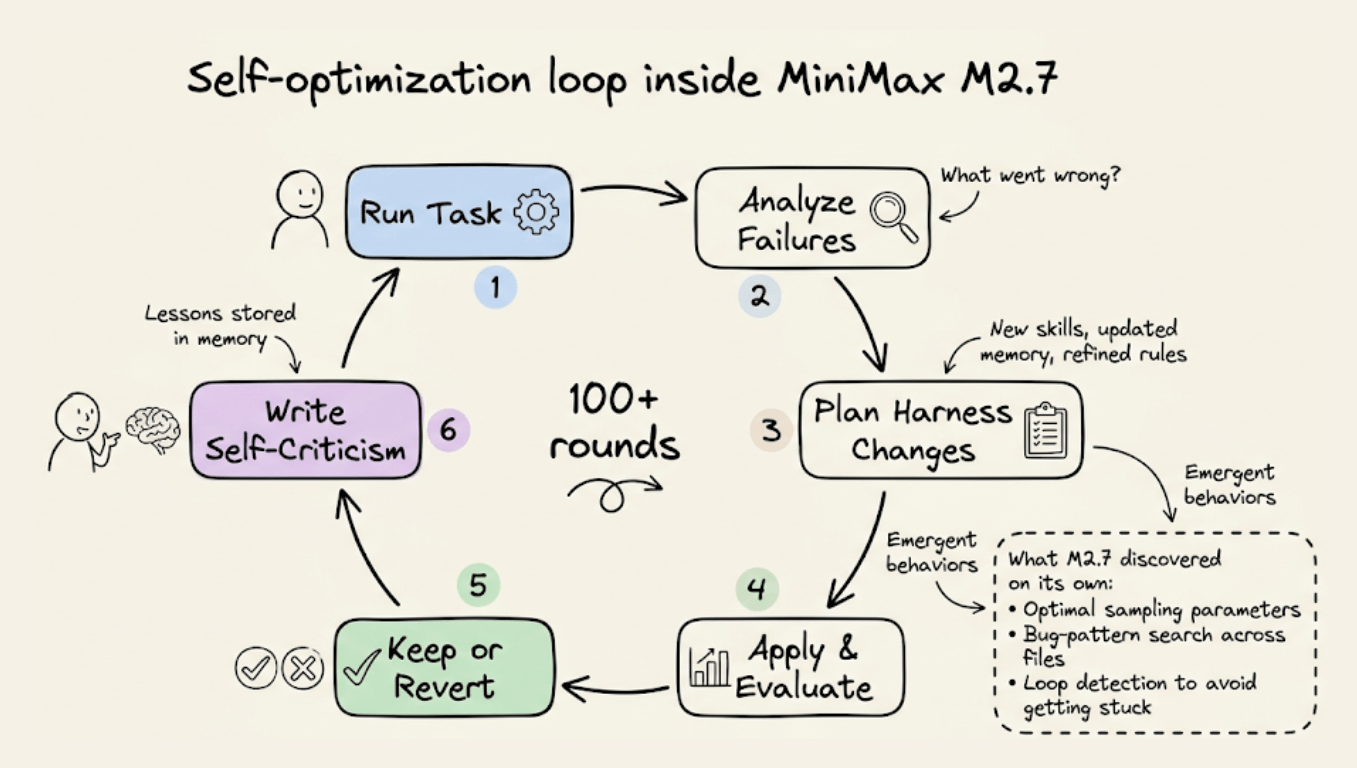
It systematically searched for optimal sampling parameters (temperature, frequency penalty, presence penalty)
It wrote workflow-specific guidelines for itself, like automatically checking for the same bug pattern in other files after a fix.
It added loop detection to avoid getting stuck in repetitive failure cycles.
This gave it a 30% performance improvement on internal evaluation sets, without any retraining.
The controlled test: MLE Bench Lite
MiniMax also tested this in a more controlled setting.
They ran M2.7 through 22 ML competitions from OpenAI’s MLE Bench Lite, each on a single A30 GPU.
The harness used three core components: short-term memory, self-feedback, and self-optimization.
After each iteration, the agent wrote a memory file describing what happened, performed self-criticism, and fed those insights into the next round.
With every round, the ML models M2.7 trained achieved higher medal rates. The best run earned 9 gold medals, 5 silver, and 1 bronze. The average medal rate across all three runs was 66.6%, tying with Gemini 3.1 and trailing only Opus 4.6 (75.7%) and GPT-5.4 (71.2%).
Importance of this approach
The weights in M2.7 never change during the self-optimization loop. What changes is the system around them, like better skills, better memory, and better workflow rules.
That distinction matters because it means the improvement loop can run continuously, in production, without any retraining cycle.
The broader signal is that model performance increasingly depends on the harness, not just the weights. And if the model can improve its own harness, the ceiling keeps moving upward without a single gradient update.
You can read more about MiniMax M2.7 in the official blog post →
👉 Over to you: Do you think self-evolving harnesses will become standard for agent deployments, or is this still too early for production?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.