
MLOps and LLMOps Case Studies
How Booking.com, Uber, Stripe, and more actually think about ML and AI systems in production.

With 32 chapters across MLOps and LLMOps course, we have covered everything from fundamentals to fine-tuning to inference optimization to serving.
We have our final chapter now, and it is one of the most valuable ones.
Read the final chapter of the MLOps/LLMOps course here →
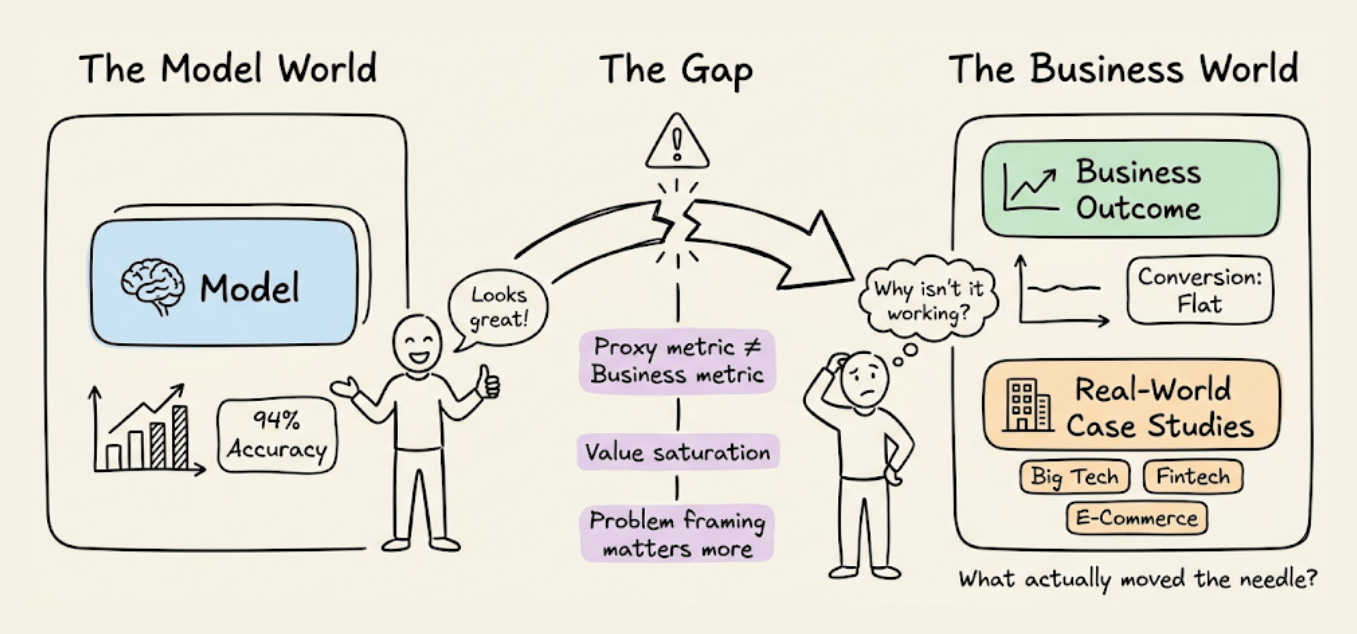
This chapter is different from the rest. It shows you how companies like Booking.com, Uber, Stripe, Doordash, and many across big tech, fintech, banking, and e-commerce actually think about ML and AI systems in production.
These are real case studies with real constraints, real failures, and the decisions that shaped how these systems were built.
One example: Booking.com deployed 150+ production models and found that improving model accuracy often did not improve business outcomes at all.
The reasons why are worth understanding deeply to better approach ML projects.
Read the final chapter of the MLOps/LLMOps course here →
Why care?
When an ML system breaks in production, it is rarely due to the model architecture. Instead, it’s a silent distribution shift, stale embeddings in the feature store, label leakage the eval pipeline did not catch, or KV caches sized for 512 tokens when production prompts routinely hit 4,000+.
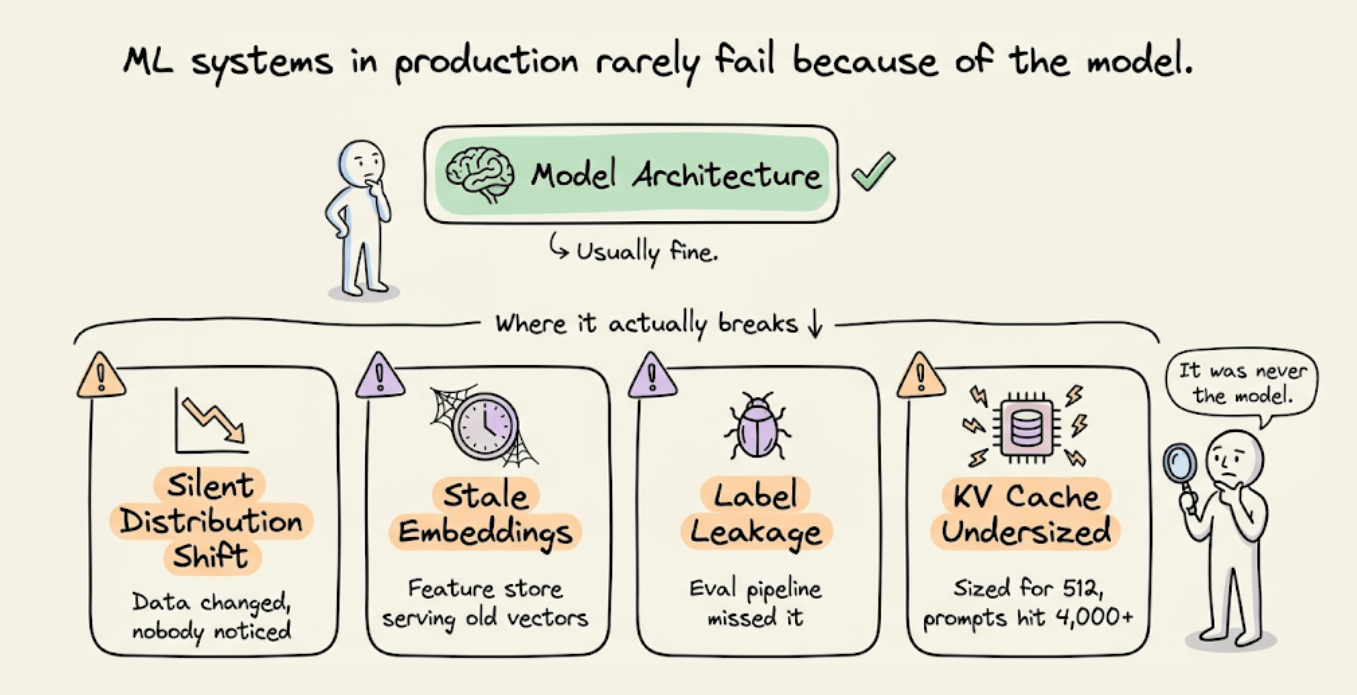
The interesting engineering lives in these operational layers when building reproducible pipelines, data versioning, CI/CD for model deployment, drift monitoring with Evidently and Prometheus, context engineering for LLMs, inference optimization via PagedAttention and continuous batching, serving topology decisions that directly shape cost and latency at scale.
MLOps and LLMOps are the disciplines that bring structure to all of this.
They take the entire surface area around a model, from how training data is tracked and validated, to how inference is optimized and served, to how evaluation catches regressions before users do, and turn it into something repeatable, observable, and maintainable.
The MLOps course (18 parts) covers the full lifecycle of traditional ML in production: reproducibility and versioning with W&B, data and pipeline engineering including sampling, feature stores, and distributed processing, model development and optimization through hyperparameter tuning, pruning, compression, and quantization, deployment via containerization, Kubernetes, AWS, and EKS, monitoring and observability with Evidently, Prometheus, and Grafana, and CI/CD workflows.
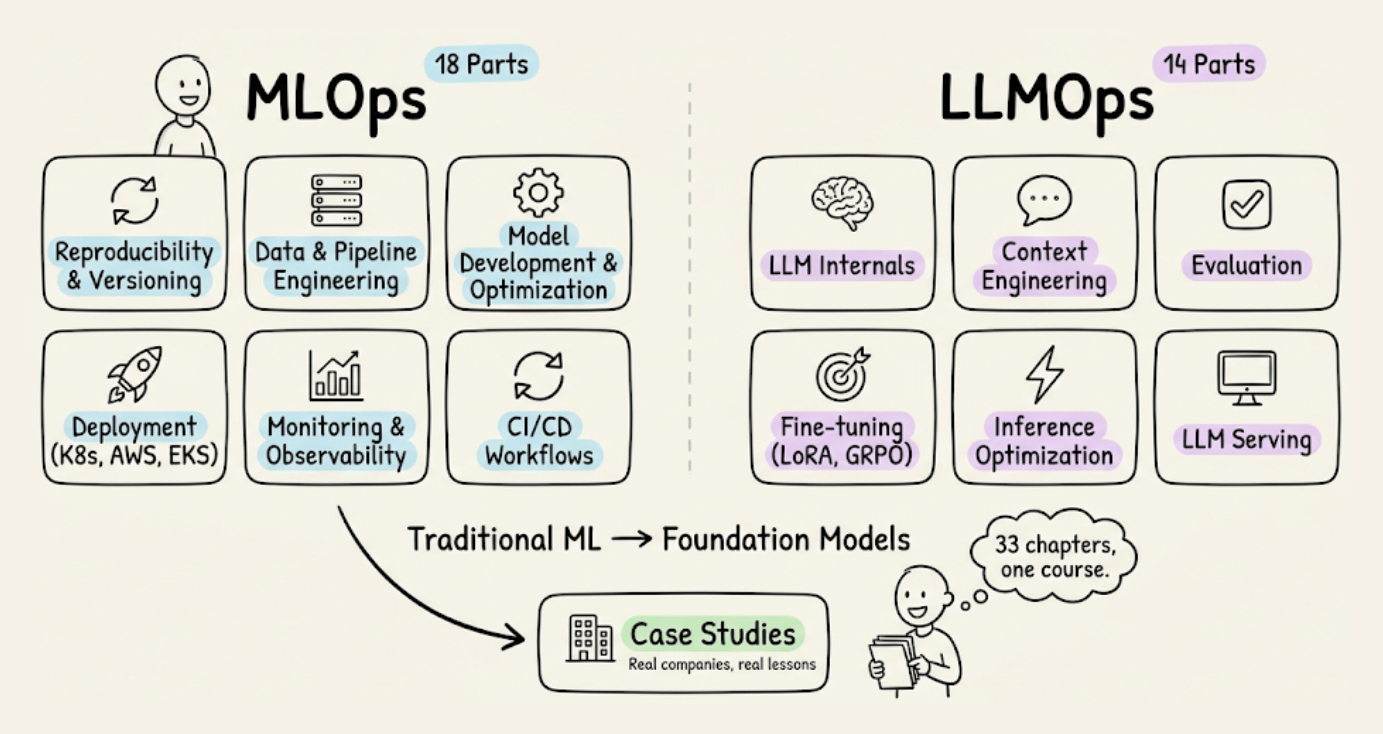
The LLMOps course (14 parts) transitions to the new set of challenges that come with foundation models: tokenization, embeddings, and attention internals, context engineering and prompt management, evaluation of open-ended generations including multi-turn and tool use, fine-tuning with LoRA, QLoRA, RLHF, DPO, and GRPO, inference optimization covering KV caching, PagedAttention, FlashAttention, and speculative decoding, and LLM serving concepts including self-hosted vs. API-based access and deployment topology.
You can start reading them here:
Thanks for reading!
Hey — I came across your writing and really liked how you think.
I’m exploring something similar from a different angle — writing about human behavior through a system design lens (like debugging internal patterns).
Just started publishing on Substack. If you ever get a moment to read, I’d genuinely value your perspective.
Also happy to support your work — feels like there’s an interesting overlap here.