
Model Compression: An Overlooked ML Technique That Deserves Much More Attention
A step towards real-world utility of ML model.

Imagine you intend to train an ML model that will also be deployed to production.
To begin, you may spend hours:
Meticulously creating relevant features,
Tuning hyperparameters,
Training the best-performing model.
But, all this is just a tiny part of this entire process.
Much of your engineering effort, however, will go into making the model production-friendly.
Because typically, the model that gets shipped is NEVER solely determined by performance — a misconception that many have.

Instead, we also consider several operational and feasibility metrics, such as:
Inference Latency: Time taken by the model to return a prediction.
Model size: The memory occupied by the model.
Ease of scalability, etc.
For instance, consider the table below. It compares the accuracy and size of a large neural network with its pruned (or reduced/compressed) versions:

Looking at the above results, don’t you strongly prefer deploying the model that is 72% smaller, but is still (almost) as accurate as the large model?
I am sure you do!
It makes no sense to deploy the large model when one of its largely pruned versions performs equally well.
The techniques that help us achieve this are called model compression techniques.

These techniques allow us to reduce both the latency and size of the original model, which directly helps in:
Lowering computation costs.
Reducing model footprint.
Improving user experience due to low latency…
…all of which are critical metrics for businesses.
Four widely popular model compression techniques are:

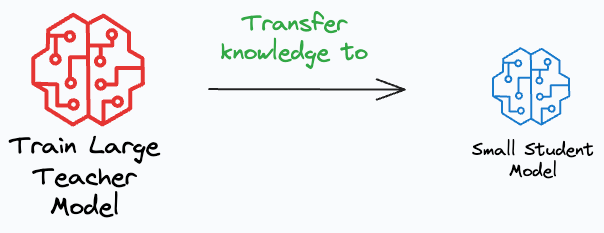
Knowledge distillation: Train a large model (teacher) and transfer its knowledge to a smaller model (student).
Model Pruning: Remove irrelevant edges and nodes from a network. Three popular types of pruning:
Zero pruning
Activation pruning (the table we discussed above depicts the results of activation pruning).
Redundancy pruning

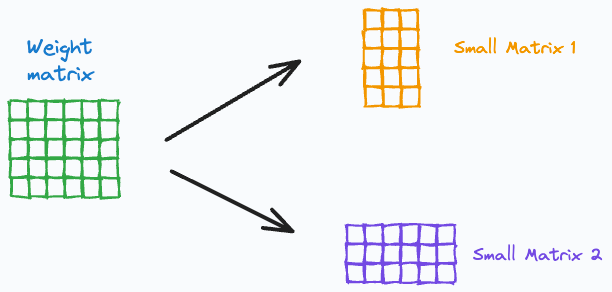
Low-rank factorization: Decompose weight matrices into smaller “low-rank” matrices.
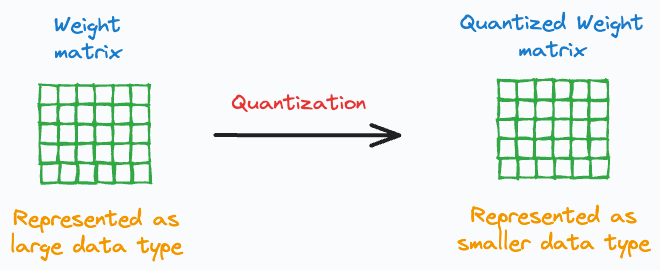
Quantization: Reduce the model’s memory usage by using lower-bit representation to store parameters.
While the above techniques are pretty effective, there are many questions to ask here:
How do these techniques work end-to-end?
How do we define “knowledge?”
How do we transfer knowledge from one model to another?
Which edges and neurons should be pruned in a network?
How do we determine the pruning criteria?
How do we decompose a weight matrix into smaller matrices?
How does having multiple matrices improve performance?
Which data type should we downcast our weight matrices to? How to decide this?
And most importantly, how to implement them in our projects?
Can you answer these questions?
If not, then this is precisely what we discussed in a recent machine learning: Model Compression: A Critical Step Towards Efficient Machine Learning.

In my opinion, for years, the primary objective in model development has been to achieve the best performance metrics.
I vividly remember when I first transitioned to industry, I witnessed that the focus radically shifted from raw accuracy to considerations such as efficiency, speed, and resource consumption.
While my complex models excelled in research and competition settings, they were not entirely suitable for real-world deployment due to scalability, maintenance, and latency concerns.
Learning about model compression techniques was possibly one of the best skills I cultivated at that time to address these business concerns.
👉 Interested folks can read it here: Model Compression: A Critical Step Towards Efficient Machine Learning.
I am confident you will learn a lot of practical skills from this 20-min deep dive :)
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
Thanks for reading!
Thanks for sharing!! Very informative
Insightful