
Model Deployment in MLOps Lifecycle
...covered from a system design perspective.

Part 14 and Part 15 of the MLOps and LLMOps crash course are now available, where we continue our discussion on the deployment phase, specifically a full hands-on deep dive on AWS (Amazon Web Services).
Modern machine learning systems don’t deliver value until their models are reliably deployed and monitored in production.
Hence, in this and the next few chapters, we’ll discuss how to package, deploy, serve, and monitor the models in a robust manner.
In these two chapters, we’ll cover:
Understanding AWS and its ecosystem.
Understanding the EKS (Elastic Kubernetes Service).
Understanding EC2 (Elastic Compute Cloud) and how EC2 integrates with EKS for node provisioning.
Other related AWS services
The EKS lifecycle (Cluster creation, node registration, deploying workloads, scaling, and updates)
Design and operational considerations
Hands-on demo: deploying an ML model on EKS
Just like all our past series on MCP, RAG, and AI Agents, this series is both foundational and implementation-heavy, walking you through everything that a real-world ML system entails:
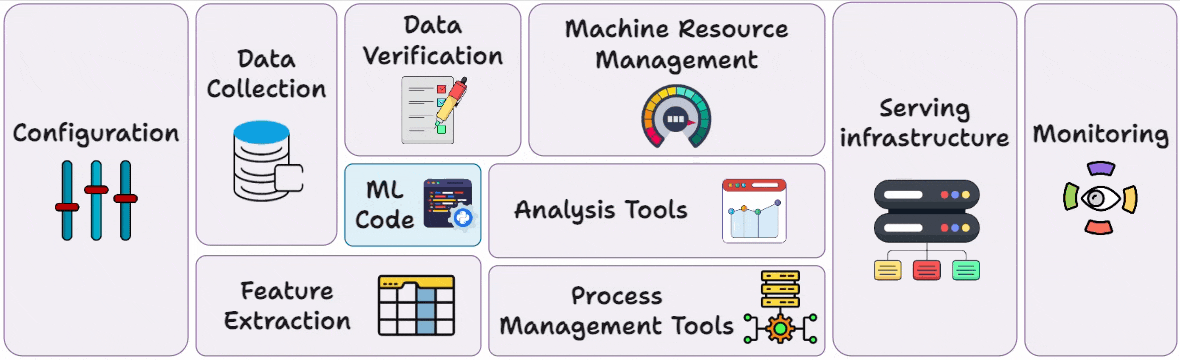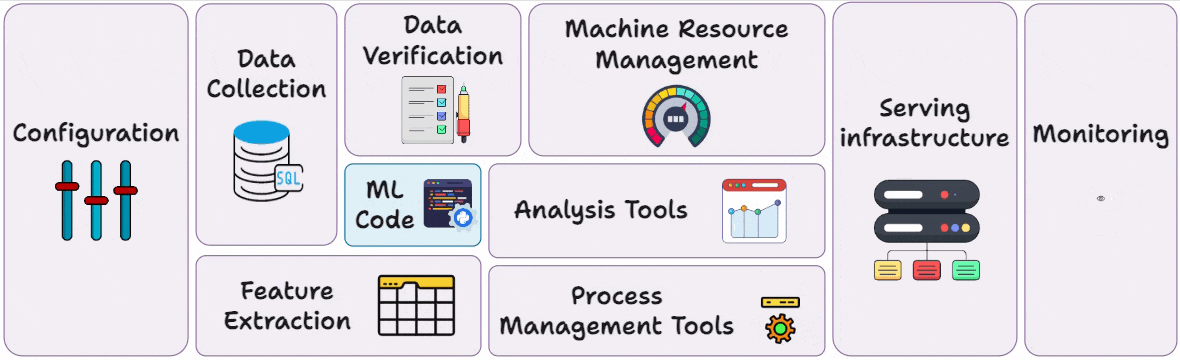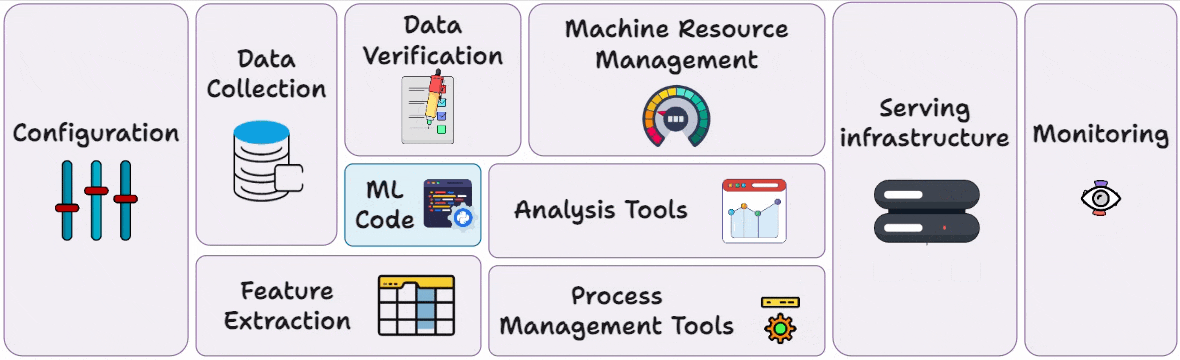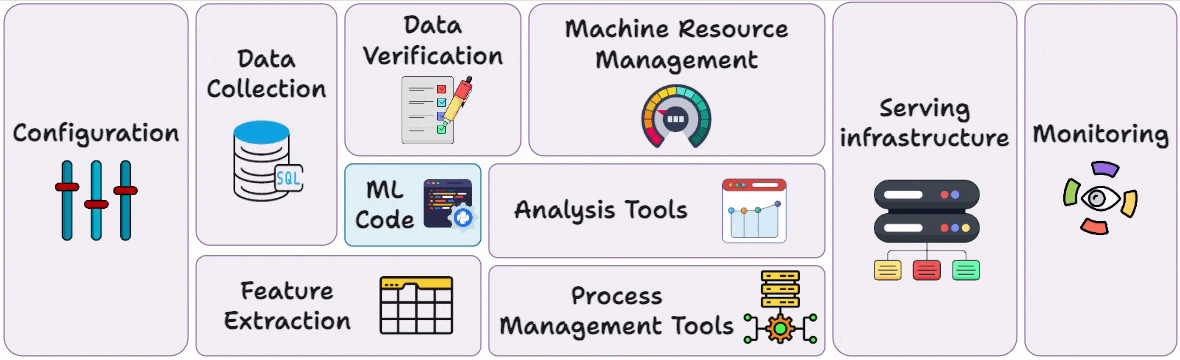
Part 3 covered reproducibility and versioning for ML systems →
Part 4 also covered reproducibility and versioning for ML systems →
Part 7 covered Spark, and orchestration + workflow management →
Part 8 covered the modeling phase of the MLOps lifecycle from a system perspective →
Part 9 covered fine-tuning and model compression/optimization →
Part 10 expanded on the model compression discussed in Part 9 →
Part 11 covered the deployment phase of the MLOps lifecycle →
This MLOps and LLMOps crash course provides a thorough explanation and systems-level thinking to build AI models for production settings.
Just like the MCP crash course, each chapter will clearly explain necessary concepts, provide examples, diagrams, and implementations.
Thanks for reading!