
Model-Free Learning in RL
The full RL nanodegree, covered with implementation.

Part 4 of the RL series is here.
The previous chapters covered MDPs, value functions, Bellman equations, and DP. All of that assumes you have full access to the environment's transition probabilities.
This chapter removes that assumption and covers how agents learn purely from interacting with the environment.
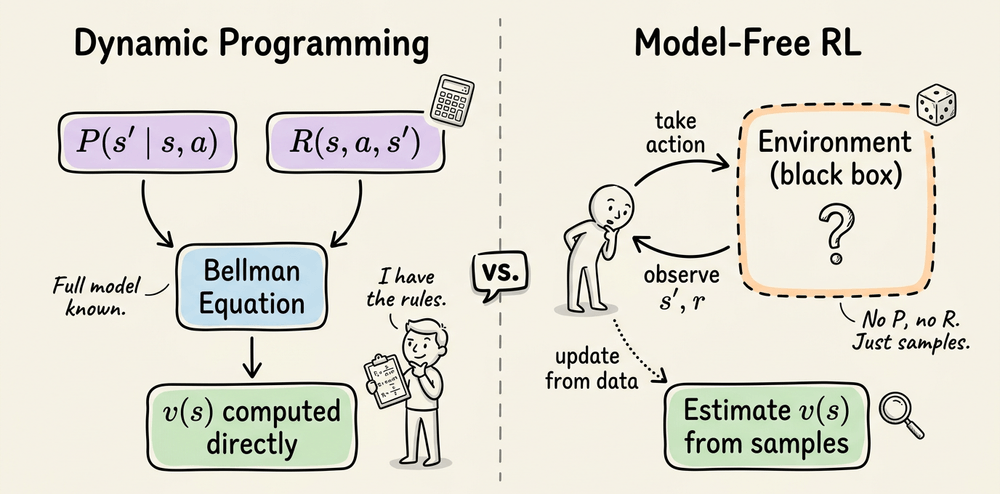
It covers:
It covers Monte Carlo prediction and control
The structural limits of MC that motivated temporal-difference learning
The intersection of MC and DP and the bias-variance tradeoff between the two,
SARSA, Q-learning, and maximization bias
And a complete SARSA vs. Q-learning experiment on the Cliff Walking gridworld with code and analysis.
Everything is covered from scratch, so no RL background is required.
You can read Part 4 of the course here →
Why care?
Supervised learning handles prediction. There are inputs and labels, and the model learns the mapping.
But a growing share of the most important problems in AI right now are not prediction problems.
They are sequential decision problems.
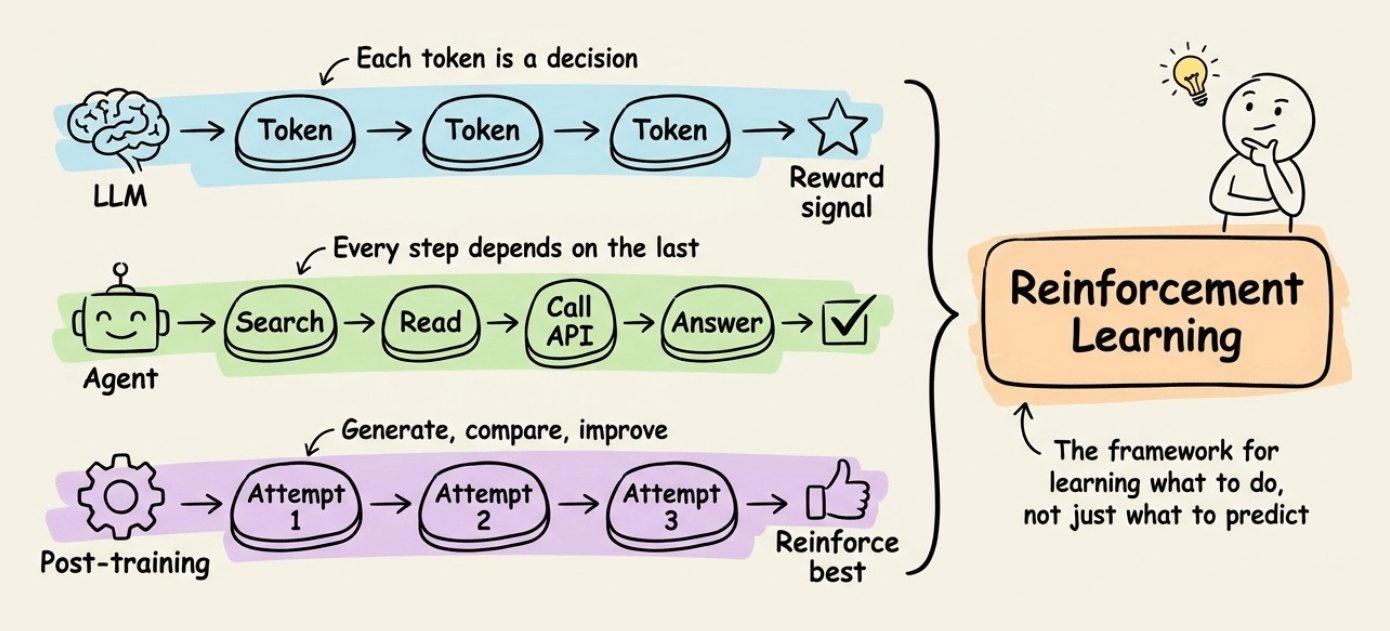
An LLM deciding which token to generate next based on a reward signal is making sequential decisions.
An agent that searches documents, calls APIs, and composes a multi-step answer is making sequential decisions.
A post-training pipeline that uses GRPO to teach a model to reason by generating multiple attempts and reinforcing the better ones is orchestrating sequential decisions.
RL is the ML paradigm designed for this, and it gives us the mathematical framework for learning what to do, not just what to predict, in settings where actions have consequences that unfold over time.
That is why it keeps showing up at the center of every major AI development. It is the right abstraction for the problems the field is increasingly trying to solve.
This series builds that understanding from the ground up, concept by concept, with math where it matters and hands-on code you can run.
👉 Over to you: What topics would you like us to cover in this RL series?
Thanks for reading!