
Model Tuning Must Not Extensively Rely on Grid Search and Random Search
...and here's what to try instead.

Hyperparameter tuning is a tedious and time-consuming task in training ML models.
Typically, we use two common approaches for this:
Grid search
Random search
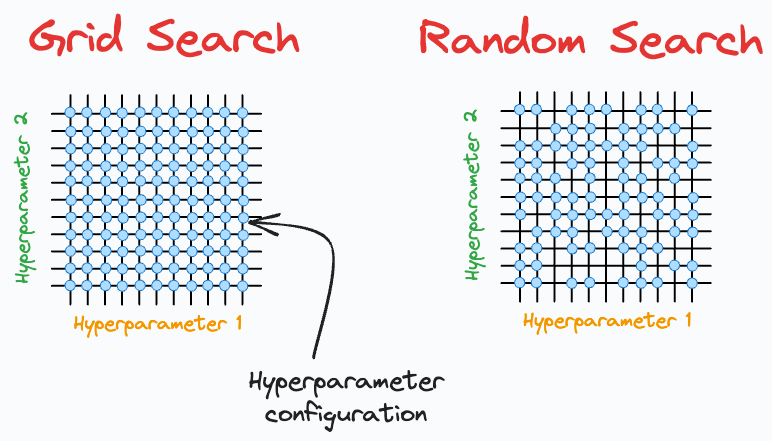
But they have many limitations.
For instance:
Grid search performs an exhaustive search over all combinations. This is computationally expensive.
Grid search and random search are restricted to the specified hyperparameter range. Yet, the ideal hyperparameter may exist outside that range.

They can ONLY perform discrete searches, even if the hyperparameter is continuous.

To this end, Bayesian Optimization is a highly underappreciated yet immensely powerful approach for tuning hyperparameters.
It uses Bayesian statistics to estimate the distribution of the best hyperparameters.
Here’s how it differs from Grid search and Random Search:
Both Grid search and Random Search evaluate every hyperparameter configuration independently. Thus, they iteratively explore all hyperparameter configurations to find the most optimal one.
However, Bayesian Optimization takes informed steps based on the results of the previous hyperparameter configurations.
This lets it confidently discard non-optimal configurations. Consequently, the model converges to an optimal set of hyperparameters much faster.
The efficacy of Bayesian Optimization is evident from the image below.
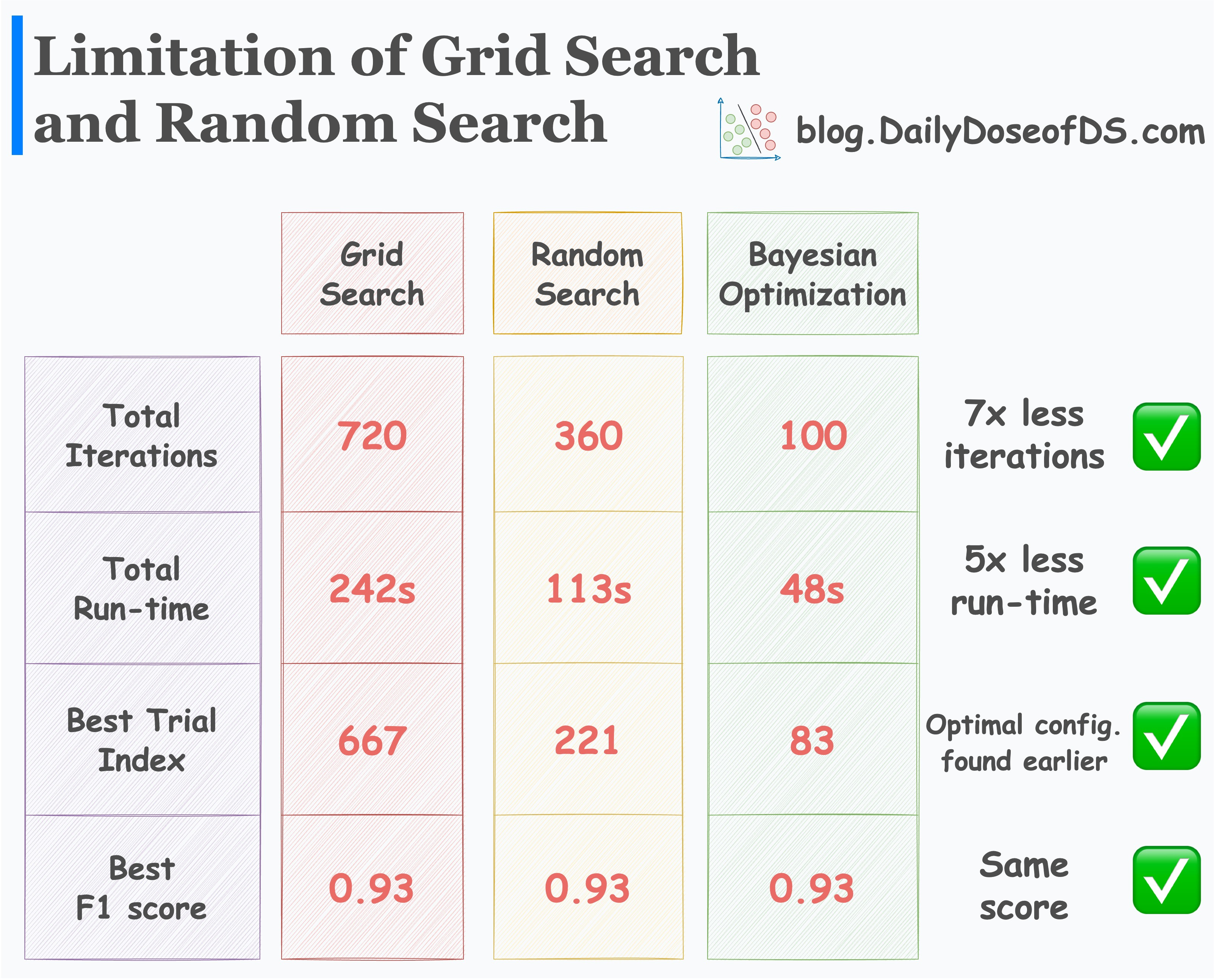
Bayesian optimization leads the model to the same F1 score but:
it takes 7x fewer iterations
it executes 5x faster
it reaches the optimal configuration earlier
Pretty cool, isn’t it?
If you are curious about Bayesian Optimization, I wrote a full deep dive on Bayesian optimization, which you can read here: Bayesian Optimization for Hyperparameter Tuning.

The idea behind Bayesian optimization appeared to be extremely compelling to me when I first learned it a few years back.
Learning about this optimized hyperparameter tuning and utilizing it has been extremely helpful to me in building large ML models quickly.
Thus, learning about Bayesian optimization will be immensely valuable if you envision doing the same.
Assuming you have never had any experience with Bayesian optimation before, the article covers:
Issues with traditional hyperparameter tuning approaches.
What is the motivation for Bayesian optimization?
How does Bayesian optimization work?
The intuition behind Bayesian optimization.
Results from the research paper that proposed Bayesian optimization for hyperparameter tuning.
A hands-on Bayesian optimization experiment.
Comparing Bayesian optimization with grid search and random search.
Analyzing the results of Bayesian optimization.
Best practices for using Bayesian optimization.
👉 Interested folks can read it here: Bayesian Optimization for Hyperparameter Tuning.
Hope you will learn something new today :)
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Very insightful , thanks for sharing
Bayesian stats is taking machine learning
to another level in most aspects. Excellent article.