
Momentum in ML, Explained Visually and Intuitively!
(a popular ML interview question)

Skill layer for Agents is here!
First tools, then memory...
...and now there’s another key layer for Agents.
Tools help Agents connect to the external world, and memory helps them remember, but they still can’t learn from experience.
Karpathy talked about it in the recent podcast.
He said that one key gap in building Agents today is that:
“They don’t have continual learning. You can’t just tell them something and they’ll remember it.”
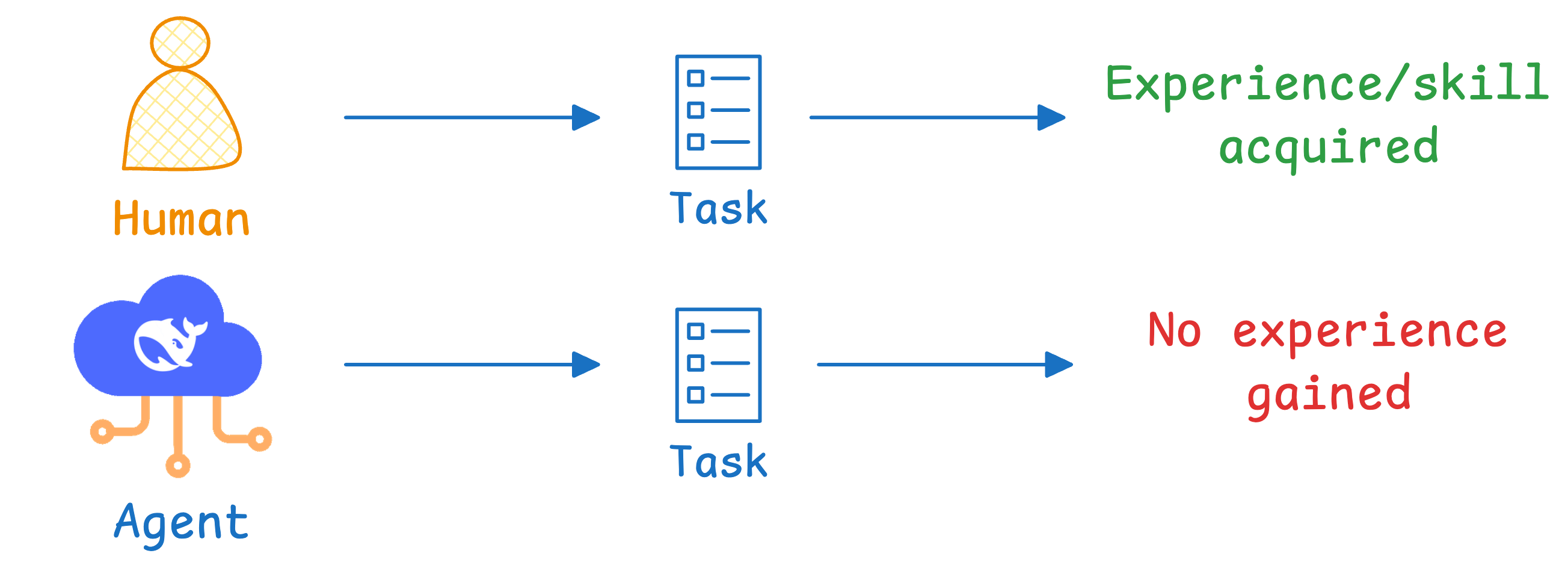
This isn’t about storing facts in memory, but rather about building intuition.
For instance, when a human masters programming, they don’t just memorize syntax.
Instead, they develop heuristics, learn edge cases, understand context, and build genuine expertise/skills through repeated interaction.
But current agents typically start from scratch every time.
Karpathy mentioned one possible path forward, which is to provide Agents with some kind of “distillation phase” that takes what happened during interactions, analyzes it, generates synthetic examples, and updates their understanding via RL.
This is similar to how humans consolidate experiences into learning.
Composio is actually building the infrastructure to solve this and provide a shared learning layer for Agents to evolve.
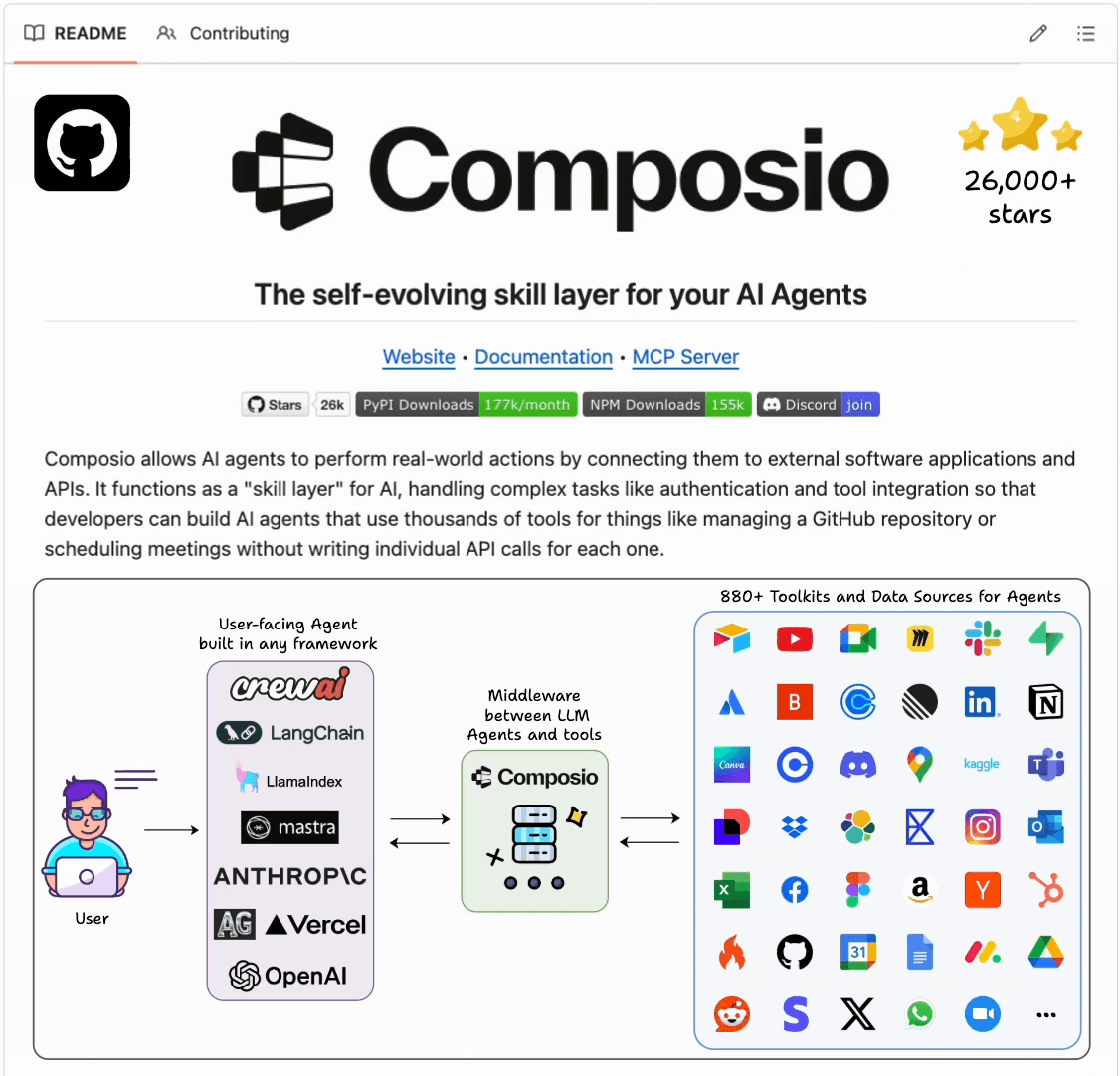
Think of it as the “skill layer” that gives Agents an interface to interact with over 10k tools while building practical knowledge from those interactions.
So when one agent learns how to handle specific API edge cases, that knowledge becomes available to every other agent via Composio’s collective AI learning layer, resulting in Agents that don’t just automate but rather develop real intuition.
This is what Karpathy meant by continual learning, where Agents don’t just memorize, but accumulate skills as they interact.
You can find the Composio GitHub repo here →
We’ll cover this in more detail in a hands-on demo soon!
Momentum in ML, explained visually and intuitively!
As we progress towards building larger and larger models, every bit of possible optimization becomes crucial.
And there are various ways to speed up model training, like:
Leverage distributed training using frameworks like PySpark MLLib.
Use better Hyperparameter Optimization, like Bayesian Optimization, which we discussed here: Bayesian Optimization for Hyperparameter Tuning.
or the 15 different techniques we covered here: 15 Ways to Optimize Neural Network Training (With Implementation).
Momentum is another reliable and effective technique.
Here’s an intuitive guide that explains its effectiveness.
Issues with Gradient Descent
In gradient descent, every parameter update solely depends on the current gradient.

This results in many unwanted oscillations during the optimization process.
To understand better, imagine this is the loss function contour plot with the optimal location marked:

The parameter update trajectory is depicted below:
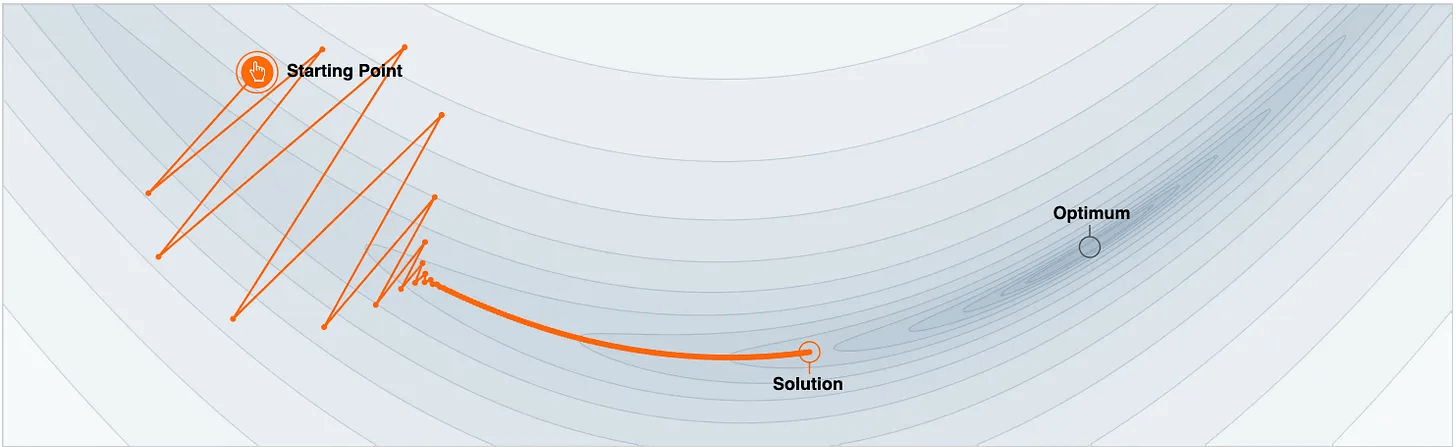
Notice two things here:
It unnecessarily oscillates vertically.
It ends up at the non-optimal solution after some epochs.
Ideally, the update process must have taken longer steps in the horizontal direction and smaller vertical steps because a movement in this direction is unnecessary:

Solution: Momentum
Momentum modifies the update rule of gradient descent by also considering a moving average of past gradients:

This handles the unnecessary vertical oscillations observed above.
More specifically, by using a moving average of past gradients, the oscillations in the vertical direction cancel out, and those in the horizontal direction push the parameters to the optimal point faster:

This smoothens the optimization trajectory and reduces unnecessary oscillations in parameter updates, as depicted below:
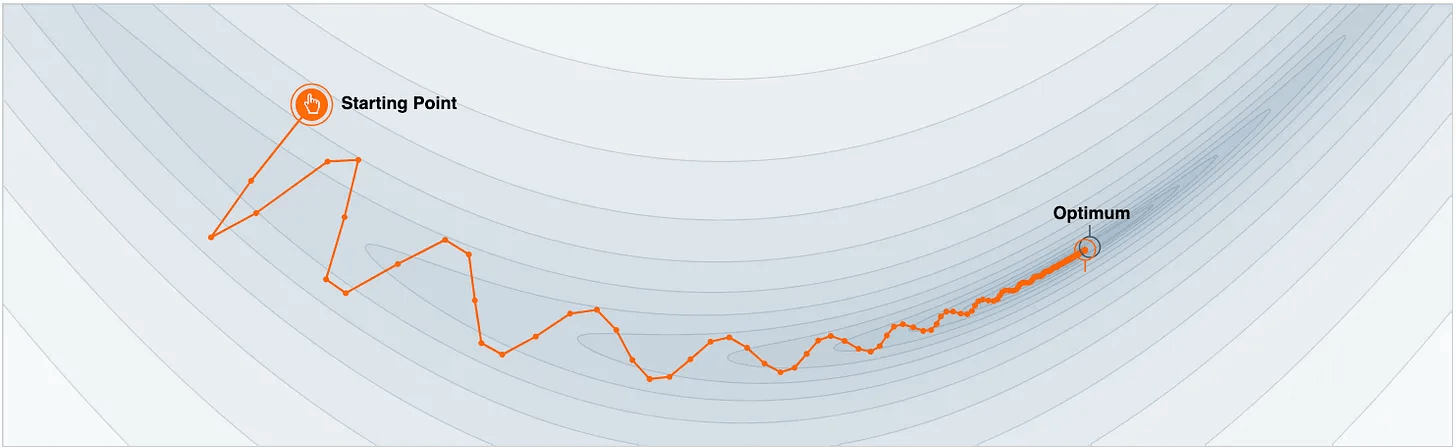
This is how Momentum works.
Of course, Momentum introduces another hyperparameter (Momentum rate) in the model, which should be tuned like any other hyperparameter:

Setting a large Momentum rate will significantly expedite the gradient update in the horizontal direction, leading to overshooting the minima:
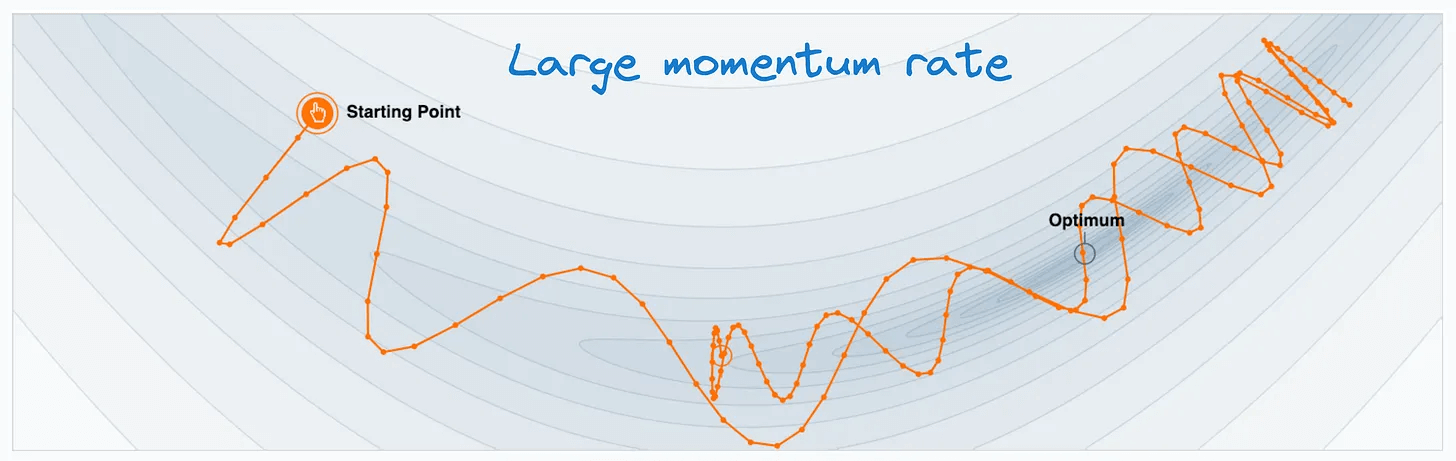
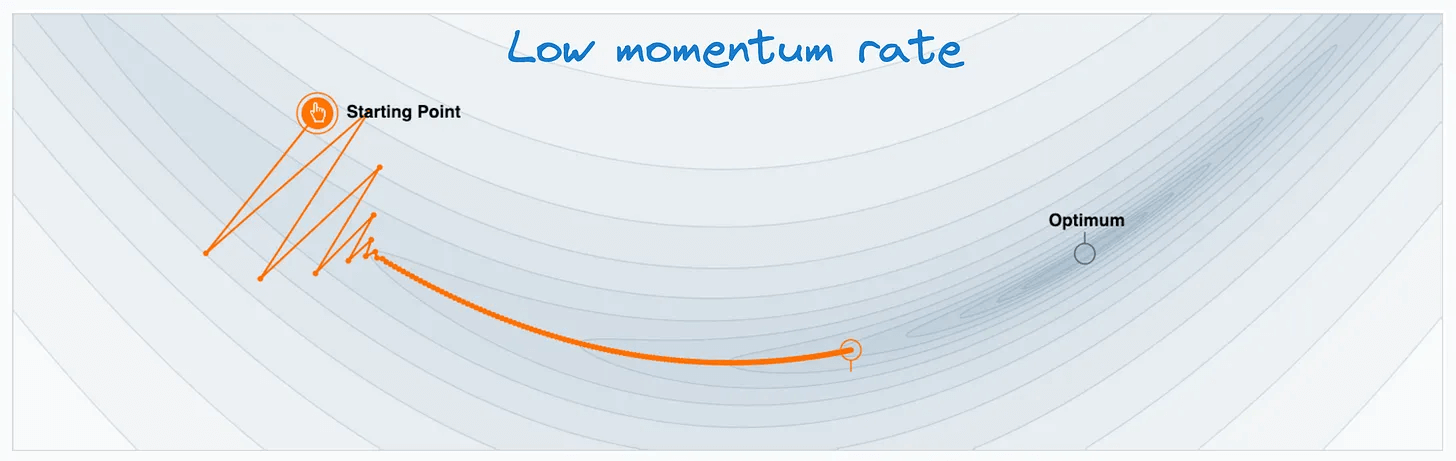
Setting a small Momentum rate will slow down the optimal gradient update, defeating the whole purpose of Momentum.
👉 Over to you: What are some other reliable ways to speed up machine learning model training?
We covered 15 different techniques here: 15 Ways to Optimize Neural Network Training (With Implementation).
If you want to have a more hands-on experience with Momentum, check out this tool: Momentum Tool.
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.