
Monitoring and Observability in MLOps Lifecycle
The full MLOps blueprint.

Part 16 of the MLOps and LLMOps crash course is now available, where we move to the monitoring phase of MLOps and understand the fundamentals of monitoring and observability (with code).
MLOps and LLMOps crash course Part 16 →
Deployment often marks not the end of a journey, but the beginning of a new and complex phase, often referred to as the “day two” problem.
In this setting, the model’s performance can no longer be taken for granted; maintaining its accuracy, reliability, and business value requires continuous attention.
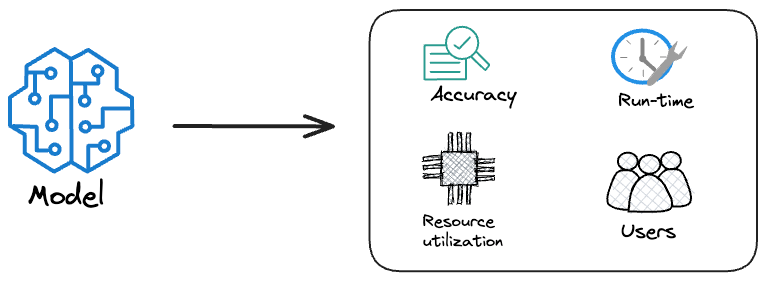
Hence, in this and the next few chapters, we’ll discuss everything you need to know about Monitoring and Observability in production:
Why do models degrade?
Understanding model degradation
Techniques to detect drift
Logging and observability for ML systems
Hands-on guide on drift detection, logging, and result collection
Just like all our past series on MCP, RAG, and AI Agents, this series is both foundational and implementation-heavy, walking you through everything that a real-world ML system entails:
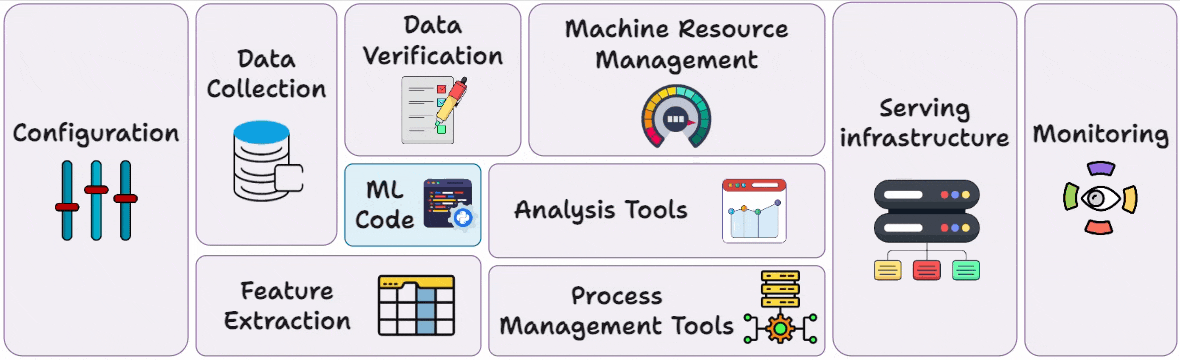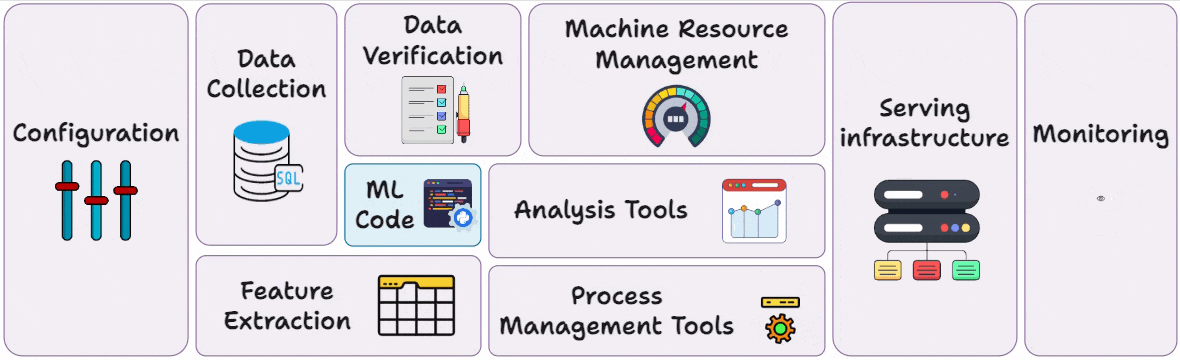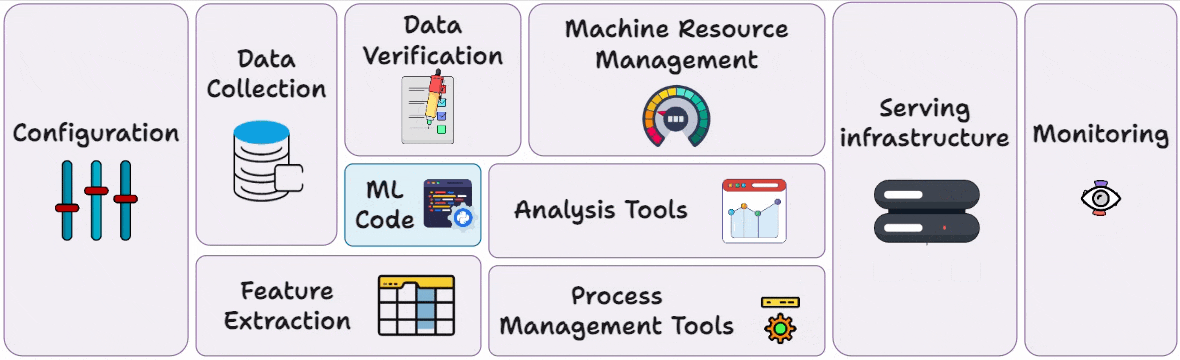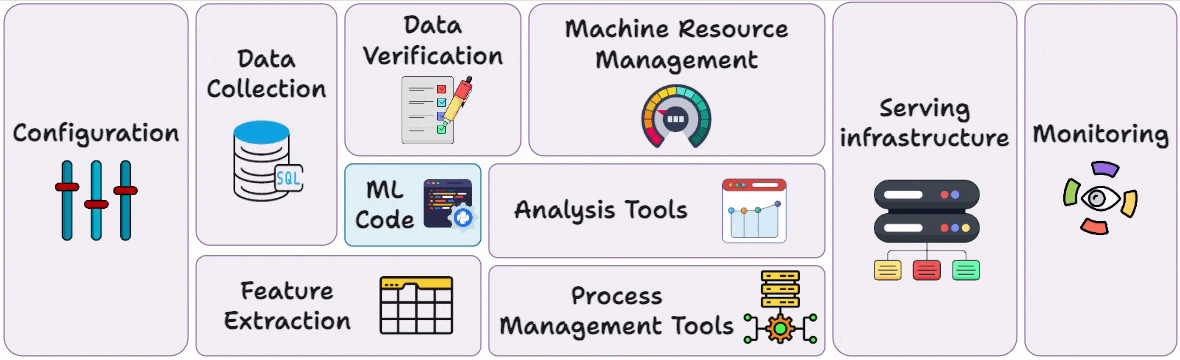
Part 3 covered reproducibility and versioning for ML systems →
Part 4 also covered reproducibility and versioning for ML systems →
Part 7 covered Spark, and orchestration + workflow management →
Part 8 covered the modeling phase of the MLOps lifecycle from a system perspective →
Part 9 covered fine-tuning and model compression/optimization →
Part 10 expanded on the model compression discussed in Part 9 →
Part 11 covered the deployment phase of the MLOps lifecycle →
This MLOps and LLMOps crash course provides a thorough explanation and systems-level thinking to build AI models for production settings.
Just like the MCP crash course, each chapter will clearly explain necessary concepts, provide examples, diagrams, and implementations.
Thanks for reading!
Thanks for writing this, it clarifies a lot. It makes sense, but how much resource overhead does this robust day two observability realy add for startups? Your explanations are always so practical.