
Most LLM-powered evals are BROKEN!
+ a popular ML interview question.

Most LLM-powered evals are BROKEN!
Typical LLM-powered evals can easily mislead you to believe that one model is better than the other, primarily due to the way they are set up.
For instance, techniques like G-Eval assume you’re scoring one output at a time in isolation, without understanding the alternative.
So when prompt A scores 0.72 and prompt B scores 0.74, you still don’t know which one’s actually better.
This is unlike scoring, say, classical ML models, where metrics like accuracy, F1, or RMSE give a clear and objective measure of performance.
There’s no room for subjectivity, and the results are grounded in hard numbers, not opinions.
LLM Arena-as-a-Judge is a new technique that addresses this issue with LLM evals.
In a gist, instead of assigning scores, you just run A vs. B comparisons and pick the better output.
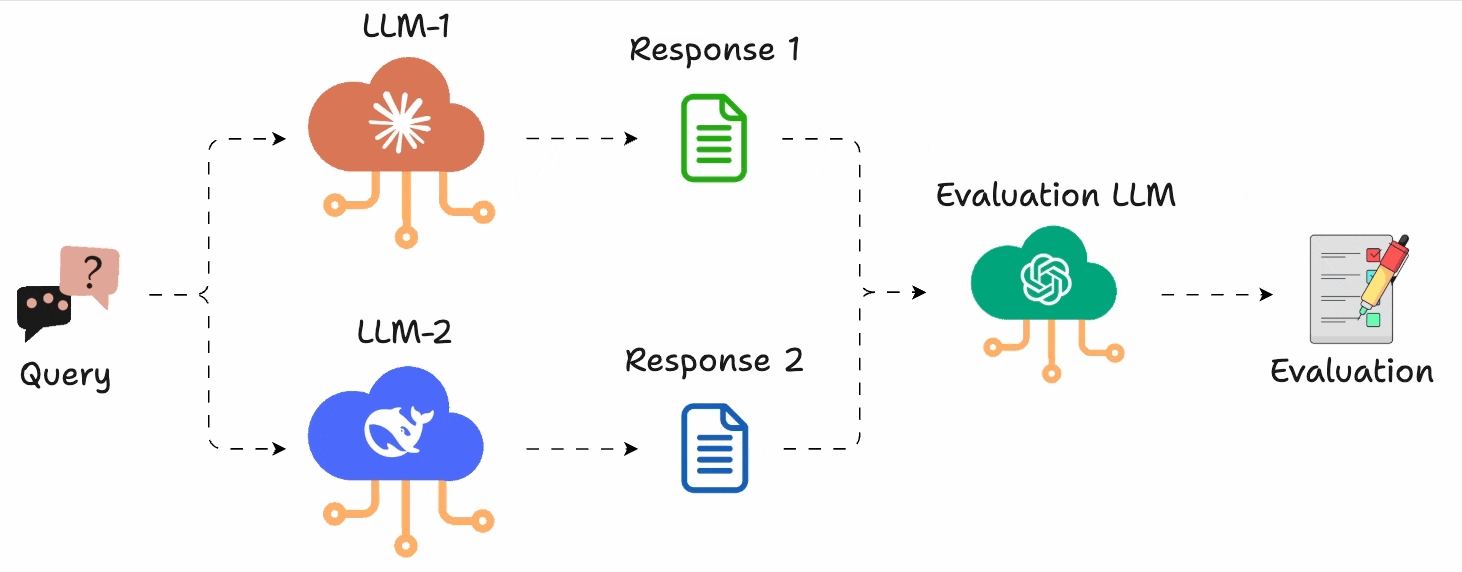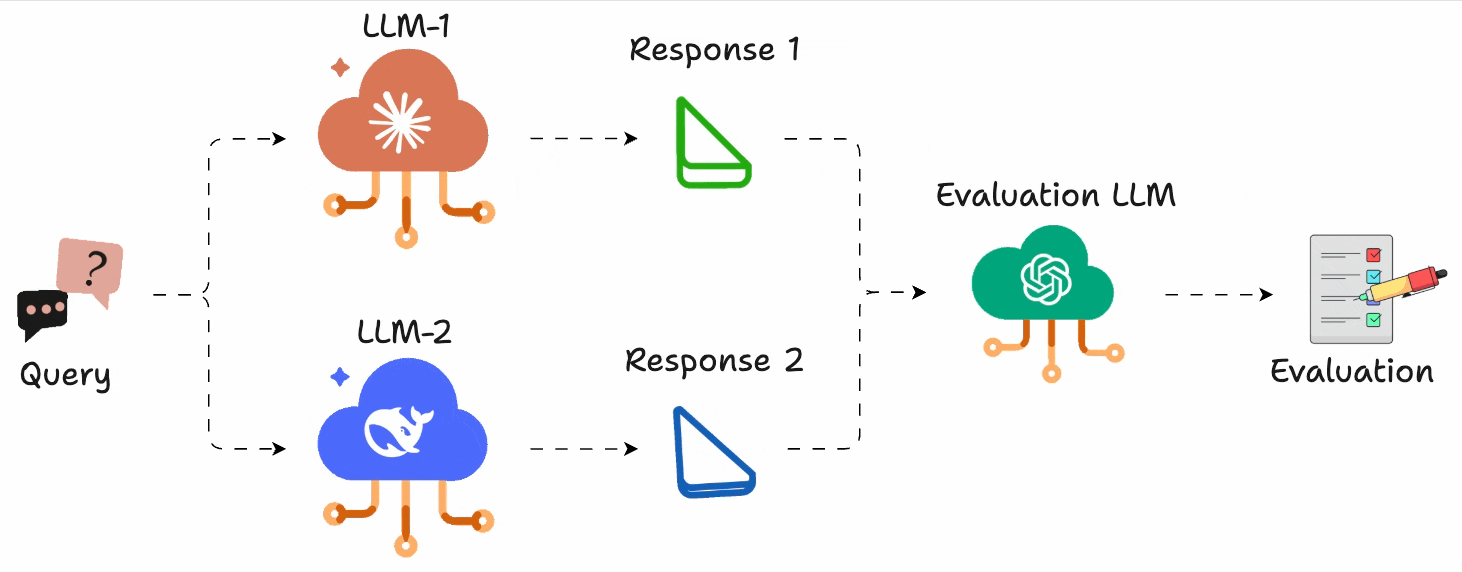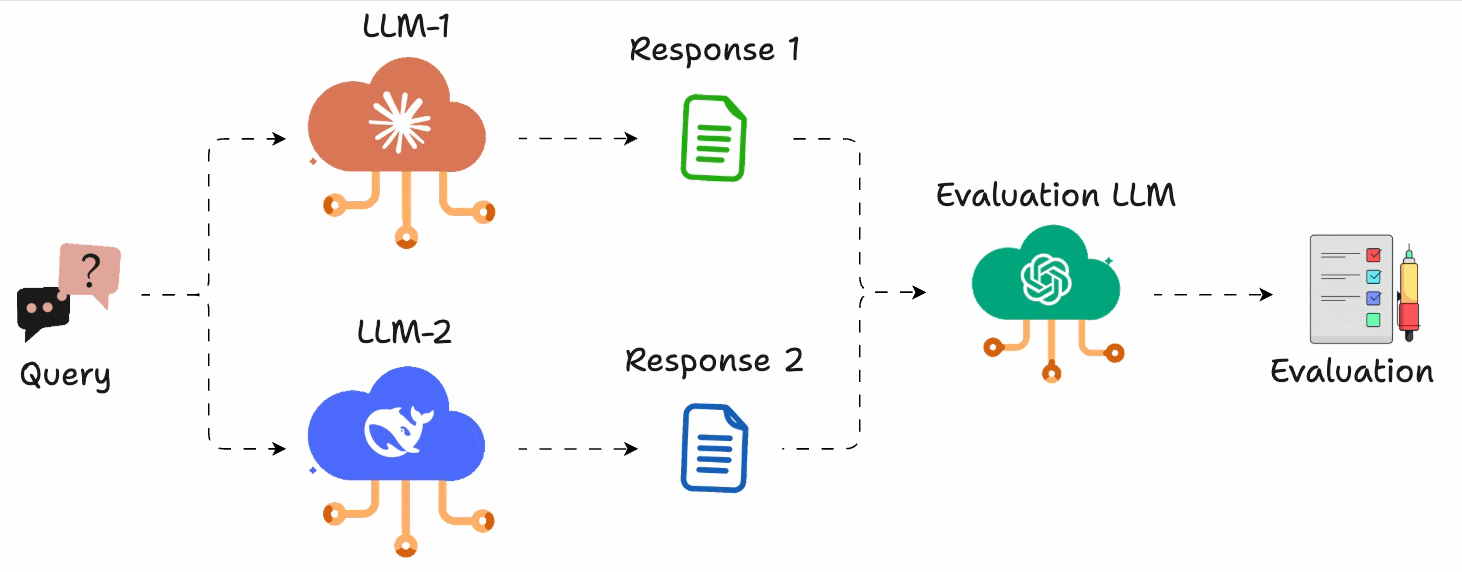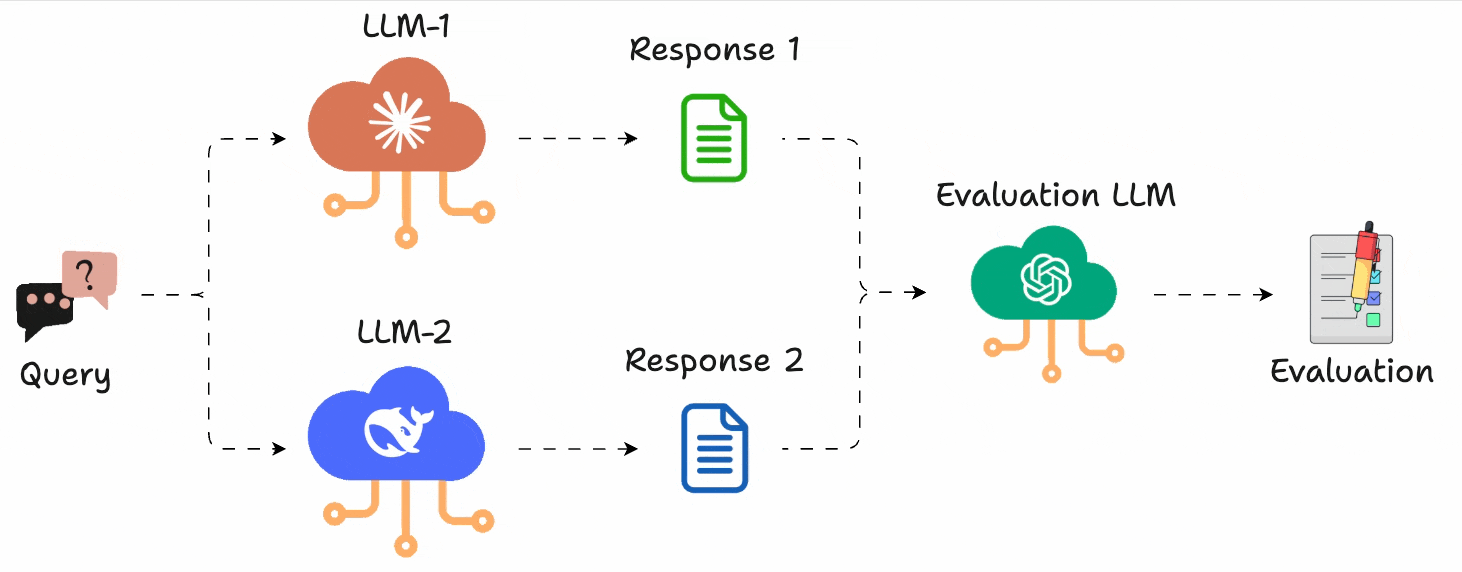
Just like G-Eeval, you can define what “better” means (e.g., more helpful, more concise, more polite), and use any LLM to act as the judge.
LLM Arena-as-a-Judge is actually implemented in DeepEval (open-source with 12k stars), and you can use it in just three steps:

Create an ArenaTestCase with a list of “contestants” and their respective LLM interactions.
Next, define your criteria for comparison using the Arena G-Eval metric, which incorporates the G-Eval algorithm for a comparison use case.
Finally, run the evaluation and print the scores.
This gives you an accurate head-to-head comparison.
Note that LLM Arena-as-a-Judge can either be referenceless (like shown in the snippet below) or reference-based. If needed, you can specify an expected output as well for the given input test case and specify that in the evaluation parameters.
Why DeepEval?
It’s 100% open-source with 12k+ stars and implements everything you need to define metrics, create test cases, and run evals like:
component-level evals
multi-turn evals
LLM Arena-as-a-judge, etc.
Moreover, tracing LLM apps is as simple as adding one Python decorator.
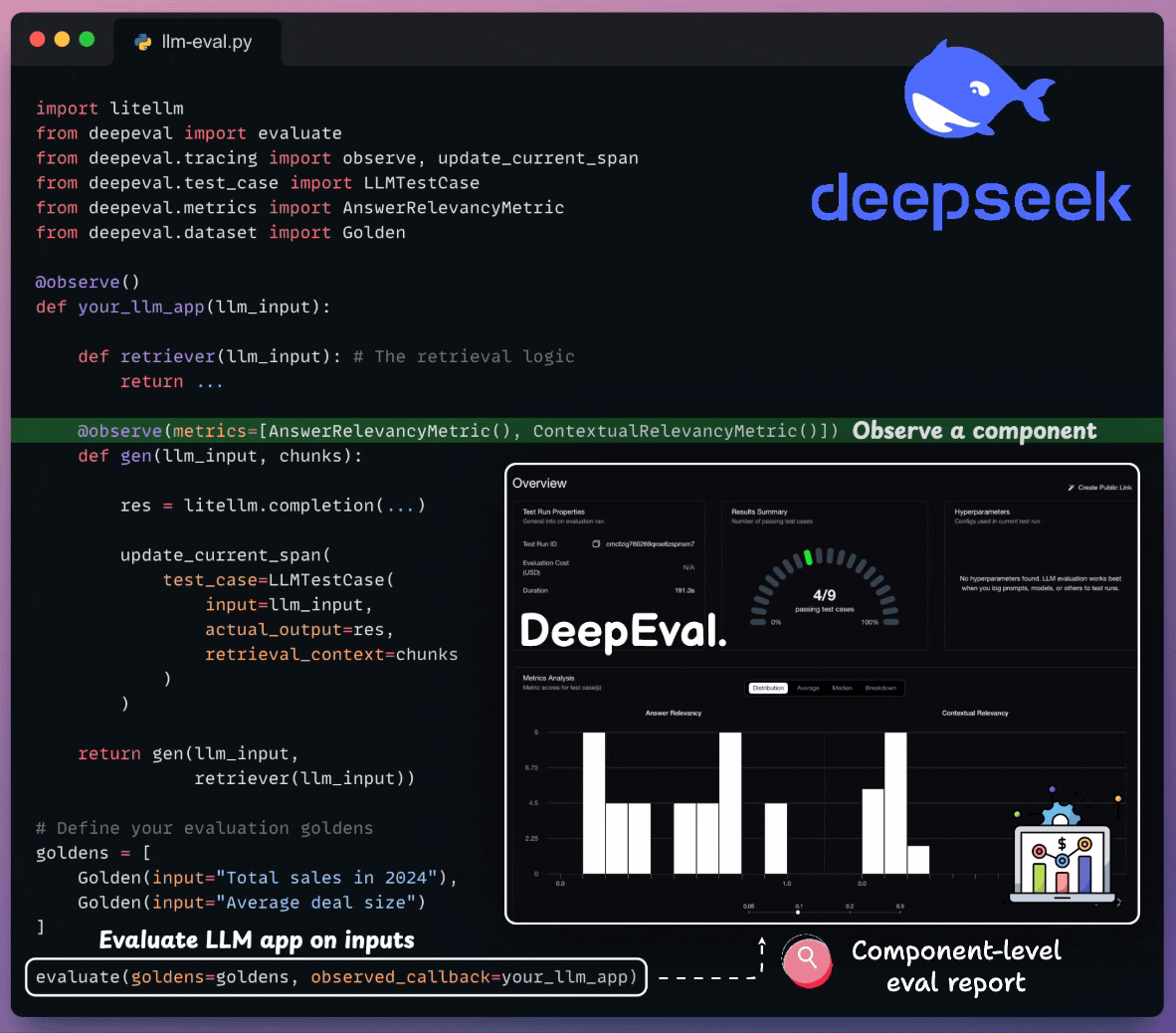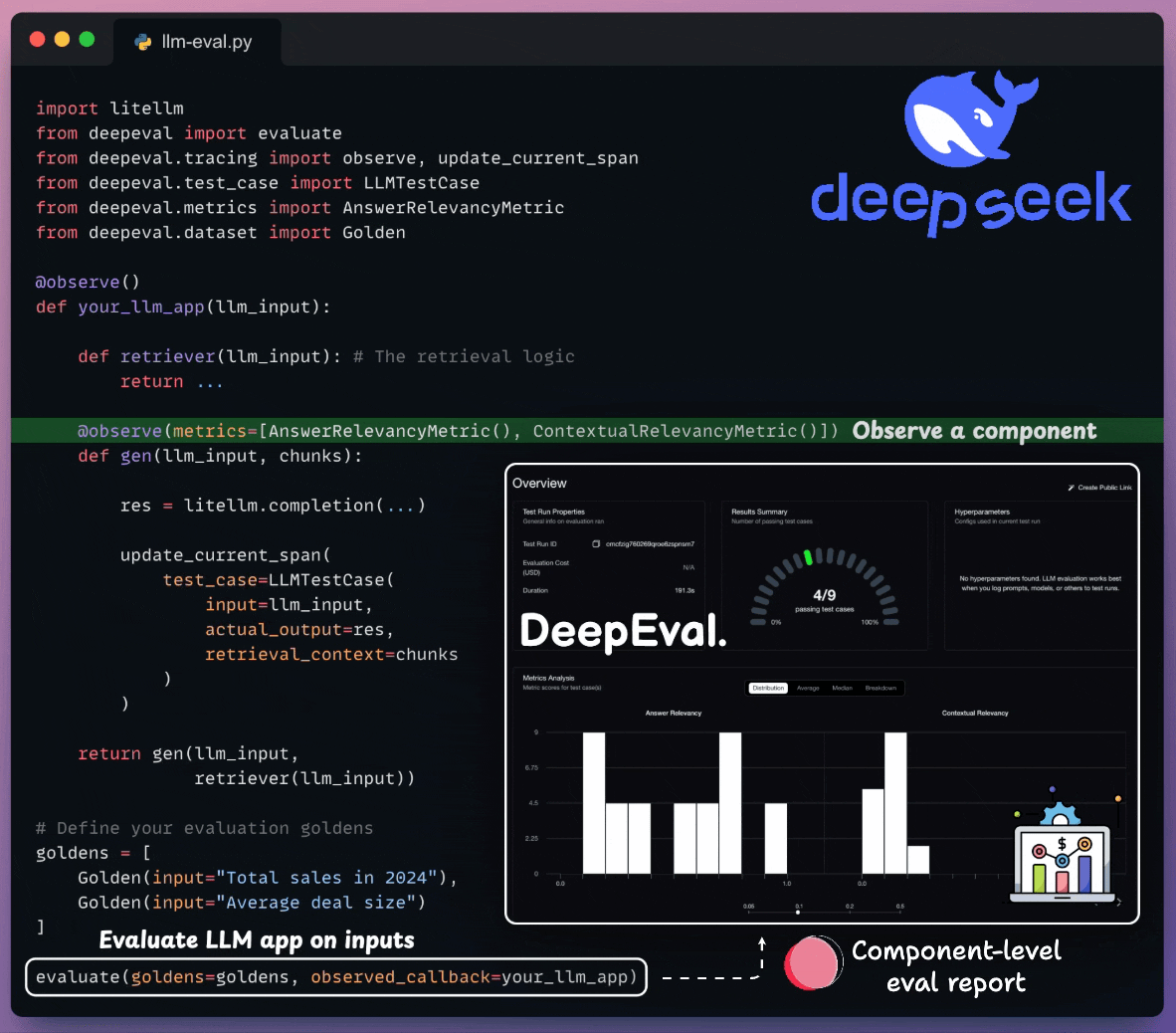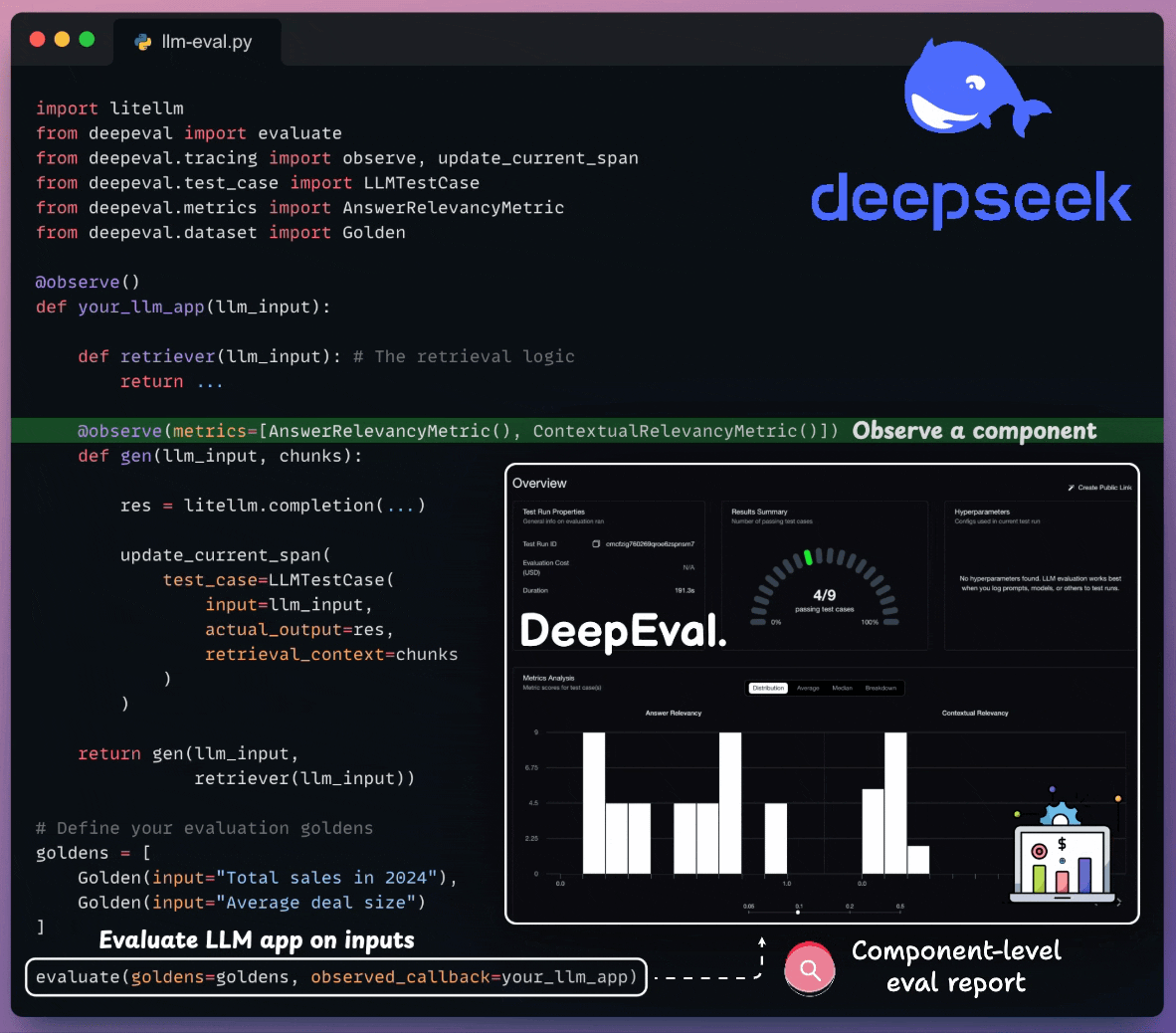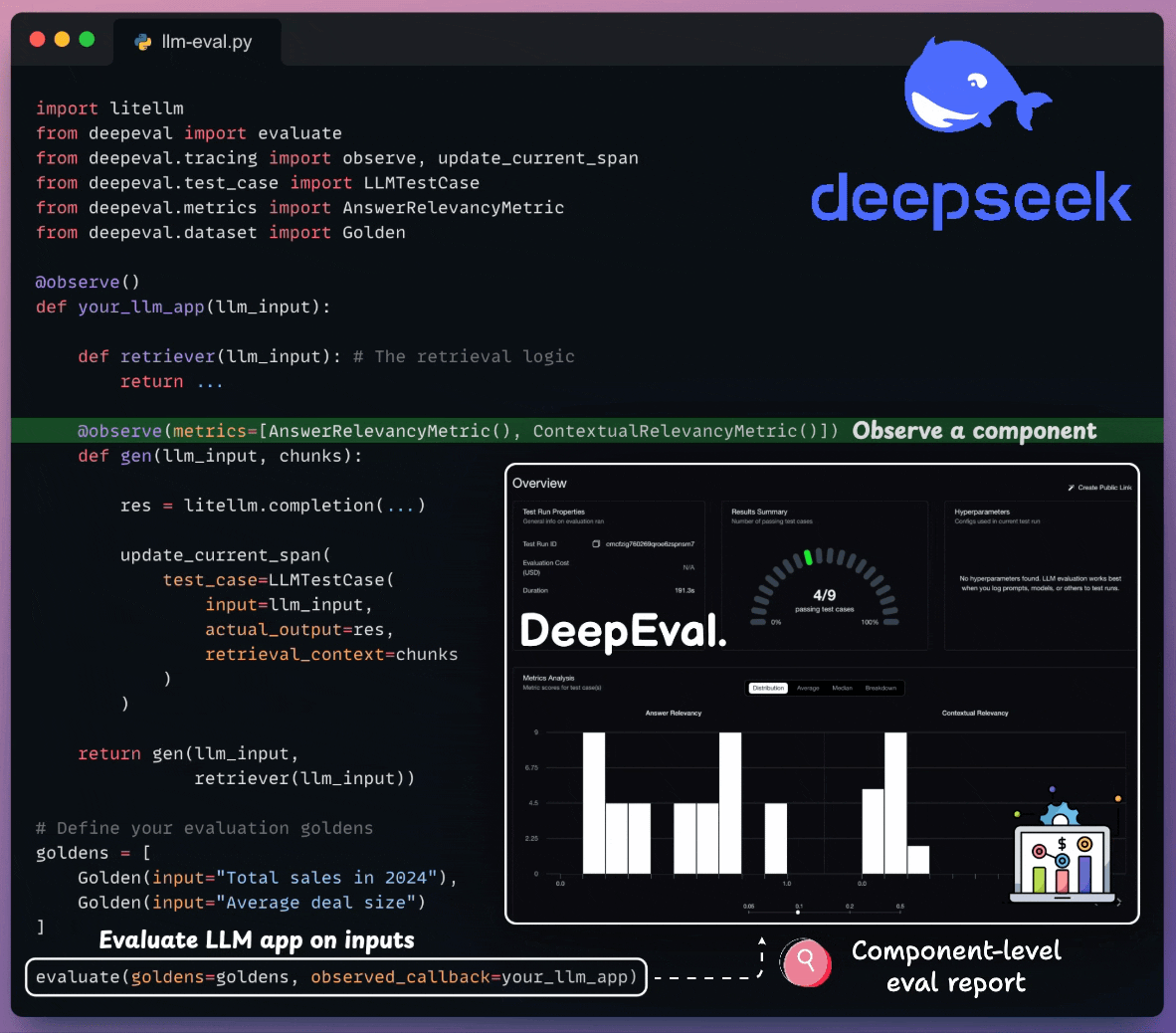
And you can run everything 100% locally.
Here’s the GitHub repo → (don’t forget to star)
You can learn more about LLM Arena-as-a-Judge in the docs here →
[Interview question] How to decide if a new model can replace an older model in production
You’re in an ML Engineer interview at Amazon.
The interviewer asks:
“You’ve trained a new recommendation model.
How do you make sure it’s ready to replace the old one?”
You reply: “I’ll compare metrics on validation and test sets.”
Interview over.
Here’s what you missed:
The issue is that, despite rigorously testing an ML model locally (on validation and test sets), it could be a terrible idea to instantly replace the previous model with the new model.

This is because it is difficult to replicate the exact production environment and conditions locally, and justify success with val/test accuracies.
A more reliable strategy is to test the model in production (yes, on real-world incoming data).
While this might sound risky, ML teams do it all the time, and it isn’t that complicated.
Note:
> Legacy model: The existing model.
> Candidate model: The new model.
Here are four common ways to do it:
We covered one more technique (Multi-armed bandits deployments) and the implementation of all five techniques here: 5 Must-Know Ways to Test ML Models in Production (Implementation Included).
1️⃣ A/B testing
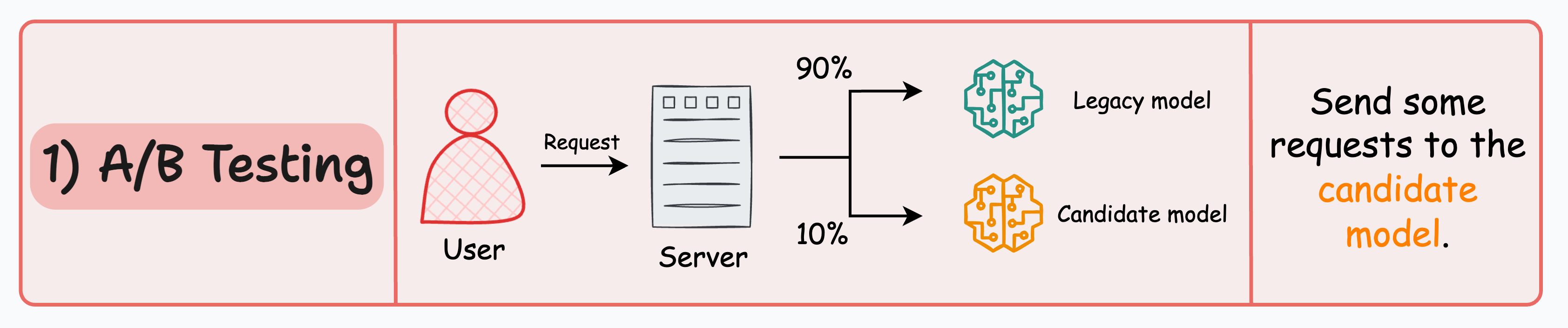
Distribute the incoming requests non-uniformly between the legacy model and the candidate model. This limits the exposure of the candidate model to avoid any potential risks.
So, say, 10% requests go to the candidate model, and the rest are still served by the legacy model.
2️⃣ Canary testing
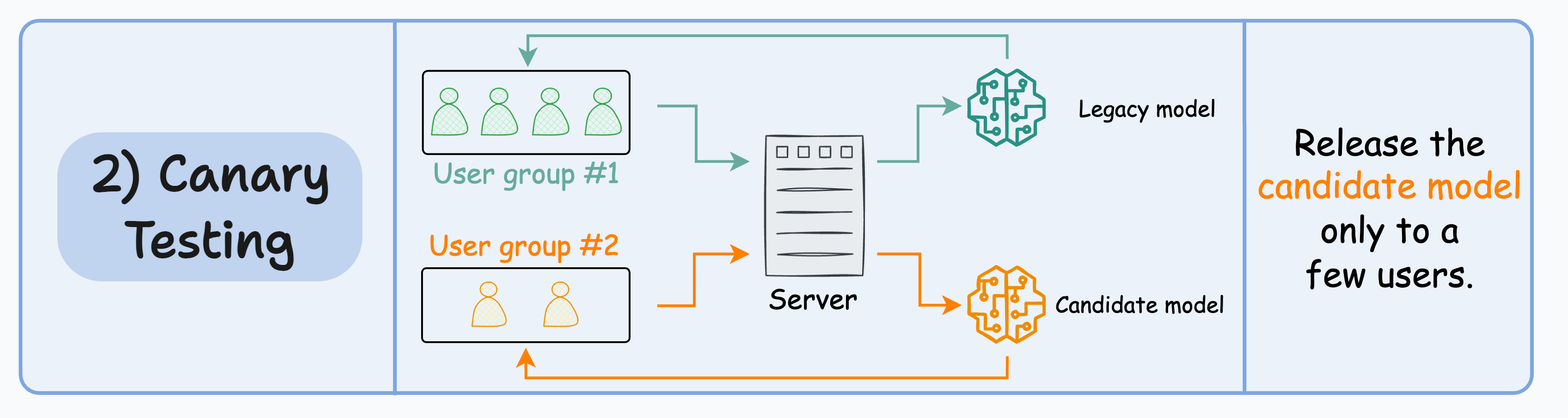
A/B testing typically affects all users since it randomly distributes “traffic” to either model (irrespective of the user).
In canary testing, the candidate model is exposed to a small subset of users in production and gradually rolled out to more users if its metrics signal success.
3️⃣ Interleaved testing

This involves mixing the predictions of multiple models in the response.
For instance, in Amazon’s recommendation engine, some product recommendations can come from the legacy model, while some can be produced by the candidate model.
Alongside, we can log the downstream success metrics (click-rate, watch-time, reported-as-not-useful-recommendation, etc.) for comparison later.
4️⃣ Shadow testing
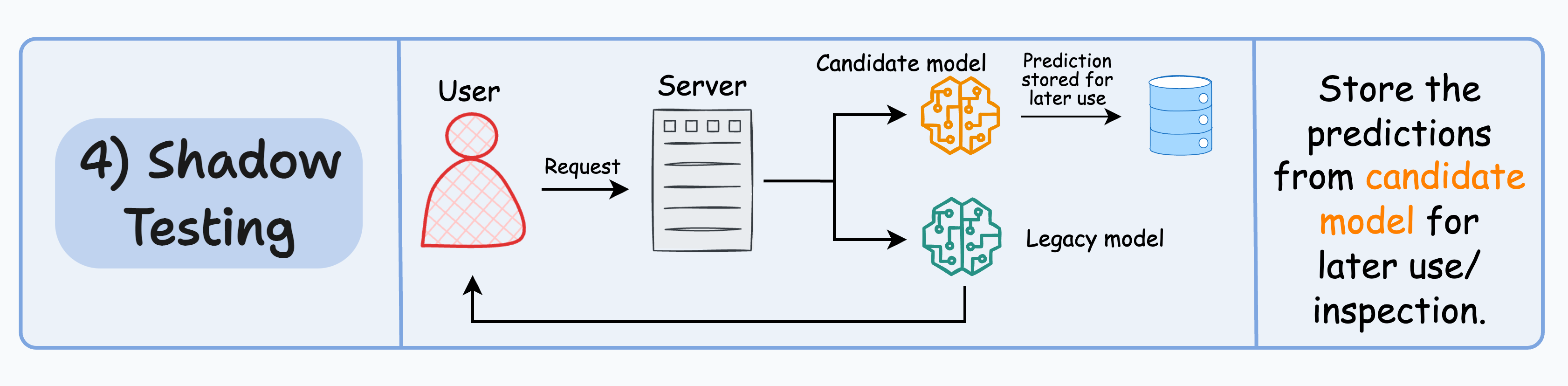
All of the above techniques affect some (or all) users.
Shadow testing (or dark launches) lets us test a new model in a production environment without affecting the user experience.
The candidate model is deployed alongside the existing legacy model and serves requests like the legacy model.
However, the output is not sent back to the user. Instead, the output is logged for later use to benchmark its performance against the legacy model.
We explicitly deploy the candidate model instead of testing offline because the exact production environment can be difficult to replicate offline.
Shadow testing offers risk-free testing of the candidate model in a production environment.
But one caveat is that you can’t measure user-facing metrics in shadow testing.
Since the candidate model’s predictions are never shown to users, you don’t get real engagement data, like clicks, watch time, or conversions.
And this is exactly how top ML teams at Netflix, Amazon, and Google roll out new models safely.
They never flip the switch all at once.
They test in production, observe, compare, and then promote the model to 100% traffic.
Of course, alongside all this, you would also measure latency, throughput, resource usage, and downstream success metrics.
A model that’s 2% more accurate but 3× slower isn’t desired from a user experience standpoint.
We covered one more technique (Multi-armed bandits deployments) and the implementation of all five techniques here: 5 Must-Know Ways to Test ML Models in Production (Implementation Included).
👉 Over to you: How do you test your models before replacing the old ones?
Thanks for reading!