
NVIDIA's Latest Update Can Make Your Pandas Workflow 150x Faster
...without any code changes.

As the dataset grows, it becomes increasingly challenging to use Pandas for data analysis.
This is because:
Pandas always adheres to single-core computation.
Pandas creates bulky DataFrames.

While many libraries do address these limitations, most of them can never make use of GPUs for immense speedups.
Addressing this, NVIDIA brought in one of the biggest updates recently.
The new RAPIDS cuDF library allows Pandas users to supercharge their Pandas workflow with GPUs.
How to use it?
Within a GPU runtime, do the following :
Load the extension:
%load_ext cudf.pandasImport Pandas:
import pandas as pdDone! Use Pandas’ methods as you usually would.
Just loading the extension provides immense speedups. This is evident from the gif below.
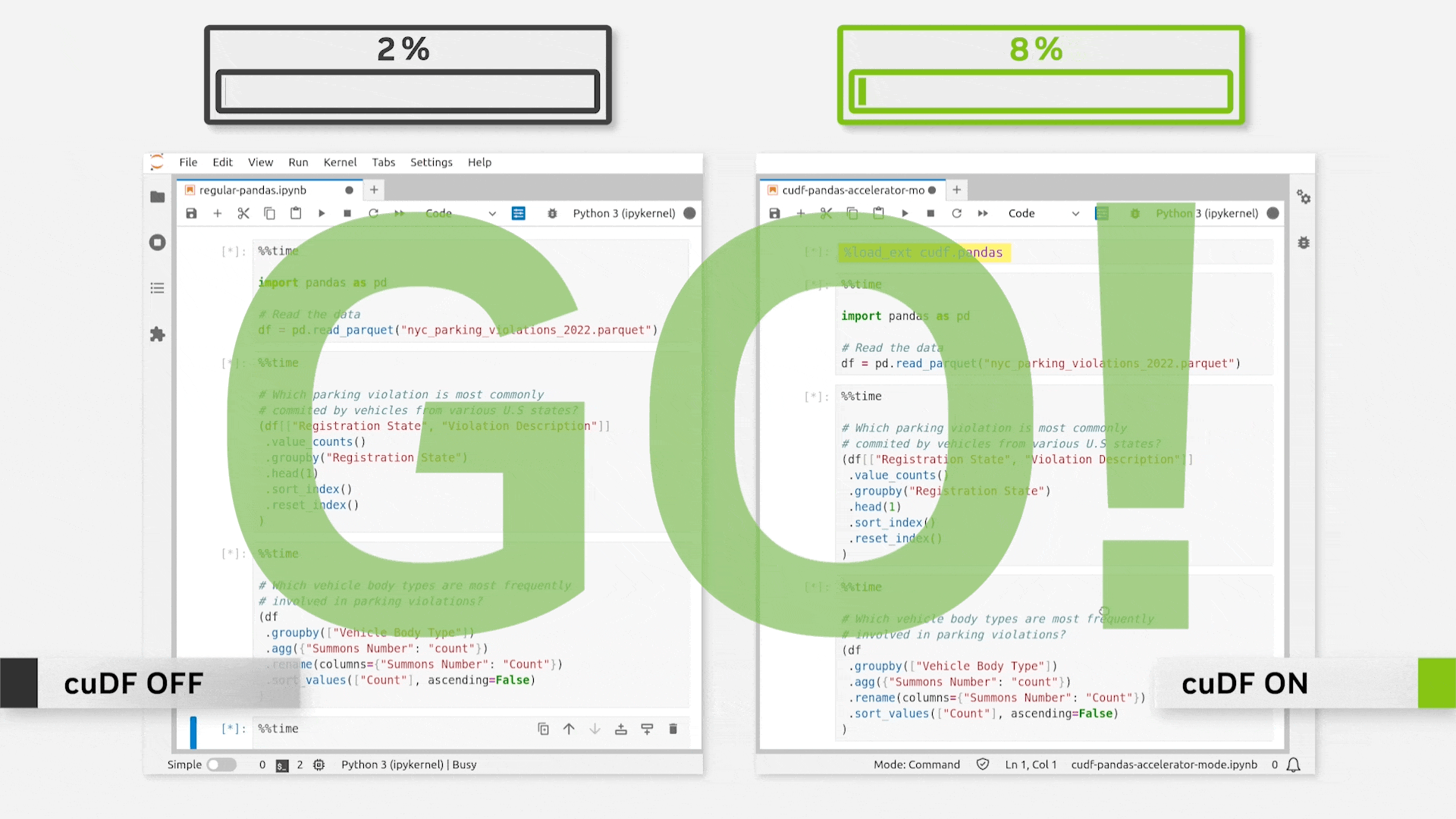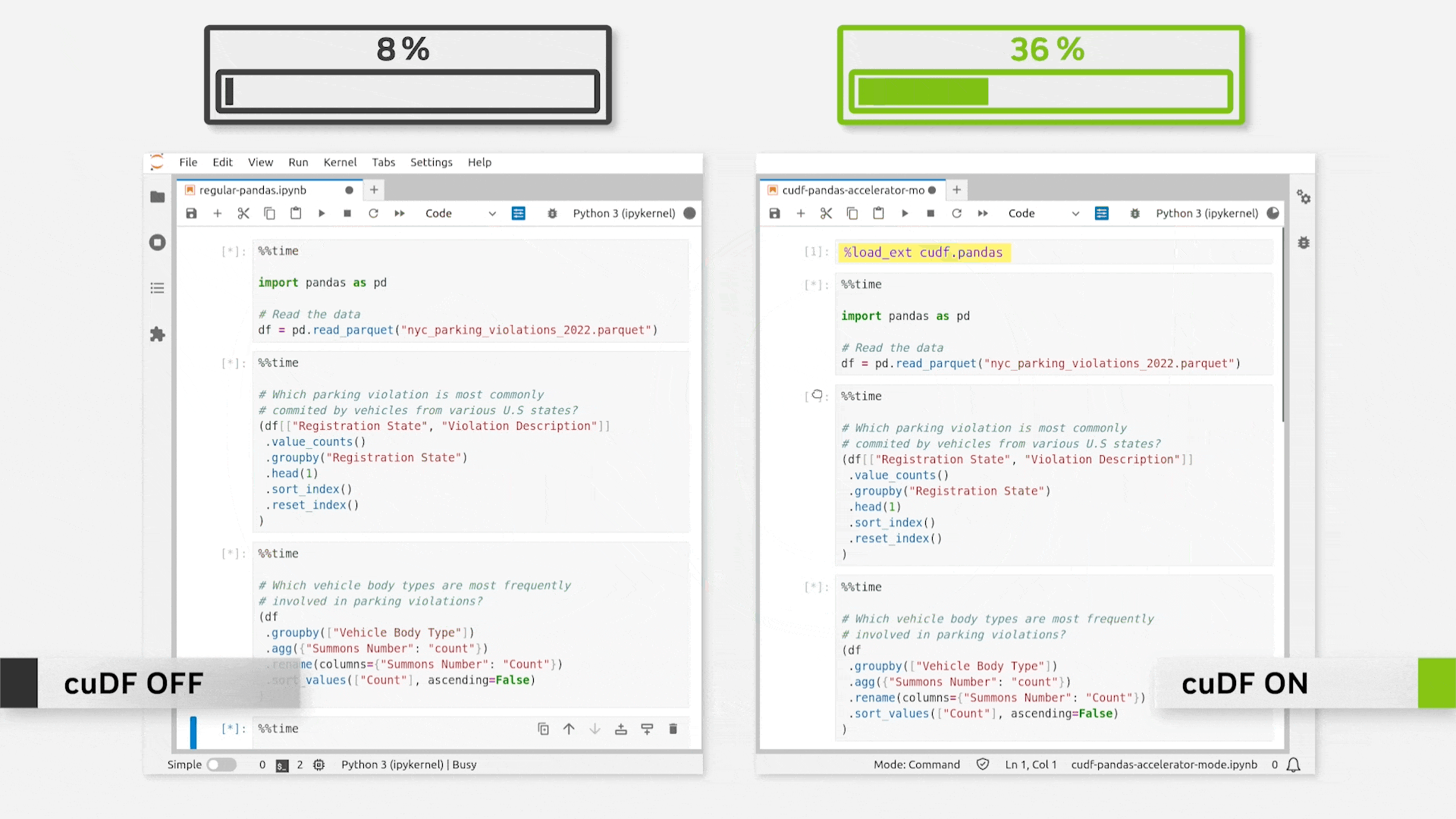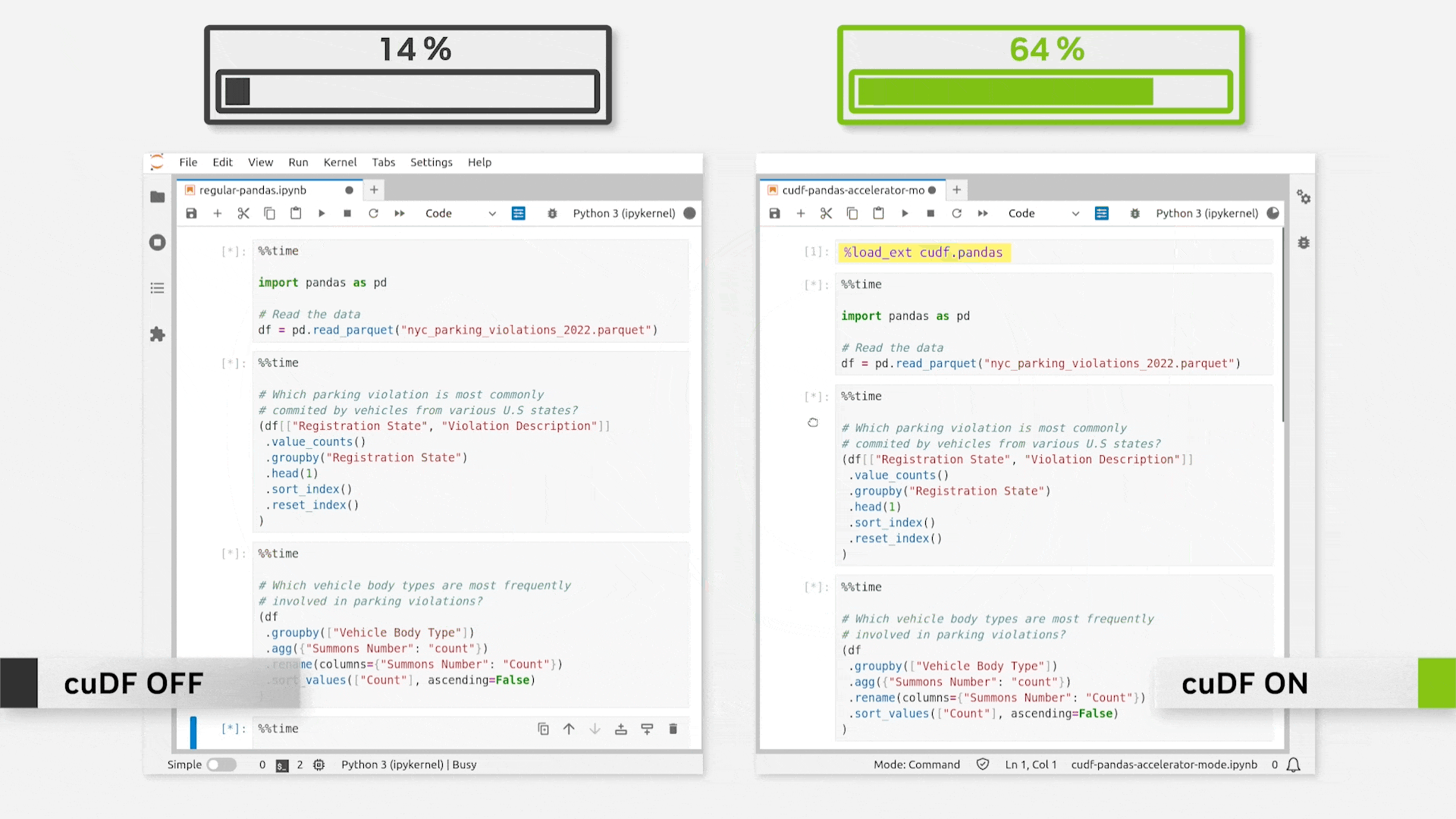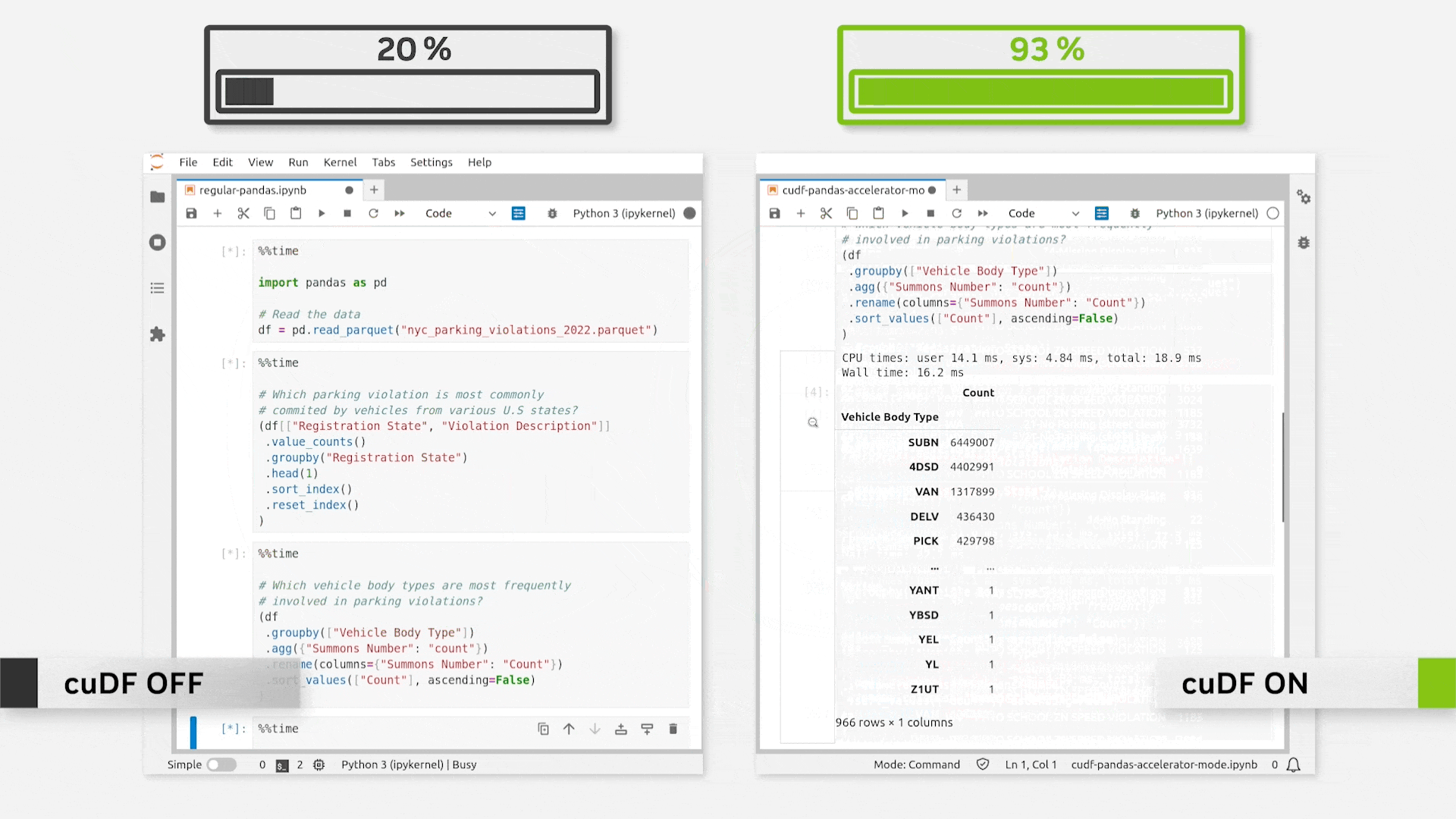
As per NVIDIA’s official release, this can be as fast as 150x.
In my personal experimentation, however, I mostly observed it to range between 50-70x, which is still pretty good.
The good thing is that the extension accelerates most Pandas’ methods.
Yet, if needed, it can automatically fall back to the CPU.
How does it work?
Whenever cudf.pandas is enabled, the import pandas as pd statement does not import the original Pandas library which we use all the time.
Instead, it imports another library that contains GPU-accelerated implementations of all Pandas methods.
This is evident from the image below:

This alternative implementation preserves the entire syntax of Pandas. So if you know Pandas, you already know how to use cuDF’s Pandas.
Isn’t that cool?
You can find the code here: Google Colab.
👉 Over to you: What are some other ways to accelerate Pandas operations in general?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning
You Cannot Build Large Data Projects Until You Learn Data Version Control!
Why Bagging is So Ridiculously Effective At Variance Reduction?
Sklearn Models are Not Deployment Friendly! Supercharge Them With Tensor Computations.
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit
Gaussian Mixture Models (GMMs): The Flexible Twin of KMeans.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Does this apply to any computer (I have an m1 Mac for example) or just users with a Nvidia graphics card?
Hey Avi, my computer showed ModuleNotFound error. How can I download CUDA Toolkit?