
One-Hot Encoding Introduces a Serious Problem in The Dataset
Hint: This is NOT about sparse data representation.

One-hot encoding is probably one of the most common ways to encode categorical variables.

However, unknown to many, when we one-hot encode categorical data, we unknowingly introduce perfect multicollinearity.
Multicollinearity arises when two (or more) features are highly correlated OR two (or more) features can predict another feature:

In our case, as the sum of one-hot encoded features is always 1, it leads to perfect multicollinearity, and it can be problematic for models that don’t perform well under such conditions.

This problem is often called the Dummy Variable Trap.
Talking specifically about linear regression, for instance, it is bad because:
In some way, our data has a redundant feature.
Regression coefficients aren’t reliable in the presence of multicollinearity, etc.
That said, the solution is pretty simple.
Drop any arbitrary feature from the one-hot encoded features.
This instantly mitigates multicollinearity and breaks the linear relationship that existed before, as depicted below:

The above way of categorical data encoding is also known as dummy encoding, and it helps us eliminate the perfect multicollinearity introduced by one-hot encoding.
The visual below neatly summarizes this entire post:

Further reading
If you want to learn about more categorical data encoding techniques, here’s the visual from a recent post in this newsletter: 7 Must-know Techniques for Encoding Categorical Features.

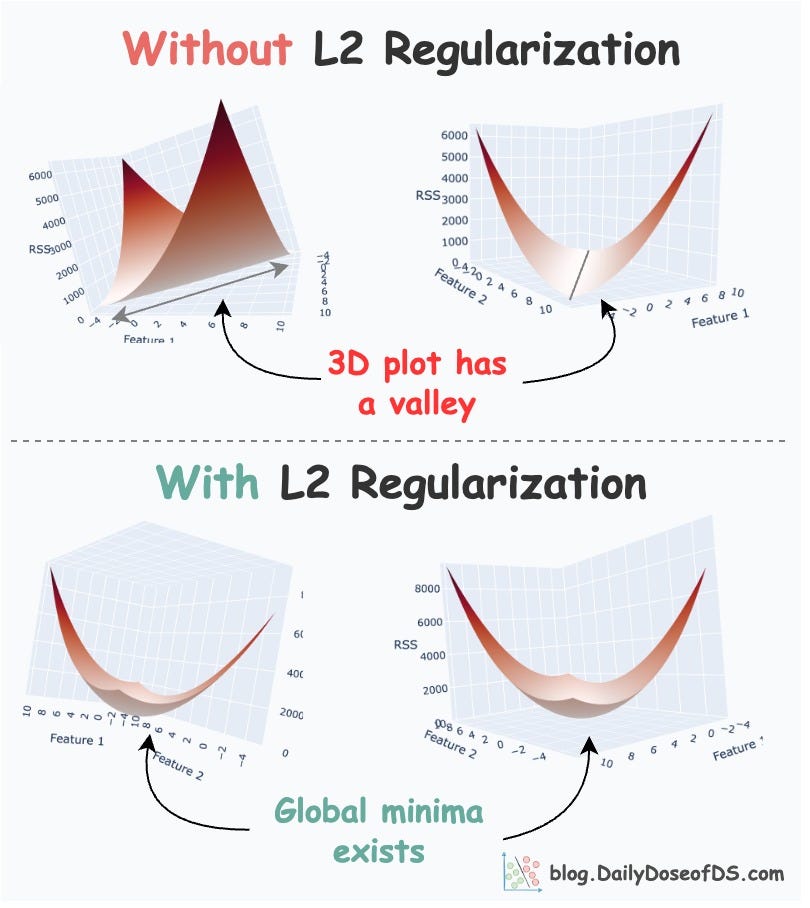
What’s more, do you know that L2 regularization is also a great remedy for multicollinearity. We covered this topic in another issue here: L2 Regularization is Much More Magical That Most People Think.
👉 Over to you: What are some other problems with one-hot encoding?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
How To (Immensely) Optimize Your Machine Learning Development and Operations with MLflow.
Don’t Stop at Pandas and Sklearn! Get Started with Spark DataFrames and Big Data ML using PySpark.
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
You Cannot Build Large Data Projects Until You Learn Data Version Control!
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Valuable gem ! Thanks Avi
Hi Avi, nice post. Could be this issue avoided with binary encoding?