
Phases of ML Modeling
... that every ML engineer should know

Most ML systems don’t jump straight to deep learning. They evolve.
A practical way to think about this evolution is in phases, starting from the simplest possible solution and gradually increasing complexity only when it’s justified. Because unnecessary complexity = low utility.
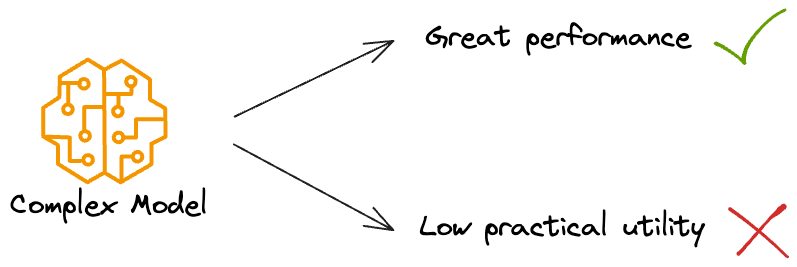
A staged approach reduces risk, improves debuggability, and aligns naturally with MLOps best practices.
Now let’s walk through the different phases of ML model development:
Phase 1: before ML (heuristics and rules)
If you’re solving a problem for the first time, resist the urge to start with a model. Begin with a non-ML baseline: a rule, a heuristic, or a simple deterministic strategy.
For example, in a movie recommendation system, a phase-1 solution could be as simple as recommending the top-10 most popular movies to every user.
This might sound naive, but such heuristics are often surprisingly strong.
These baselines are fast to build, easy to reason about, and set a minimum performance bar. If a complex ML model cannot beat a naive heuristic, something is wrong, either ML isn’t adding value, or there’s a bug in the pipeline.
Here is a conceptual diagram summarizing the Phase 1:
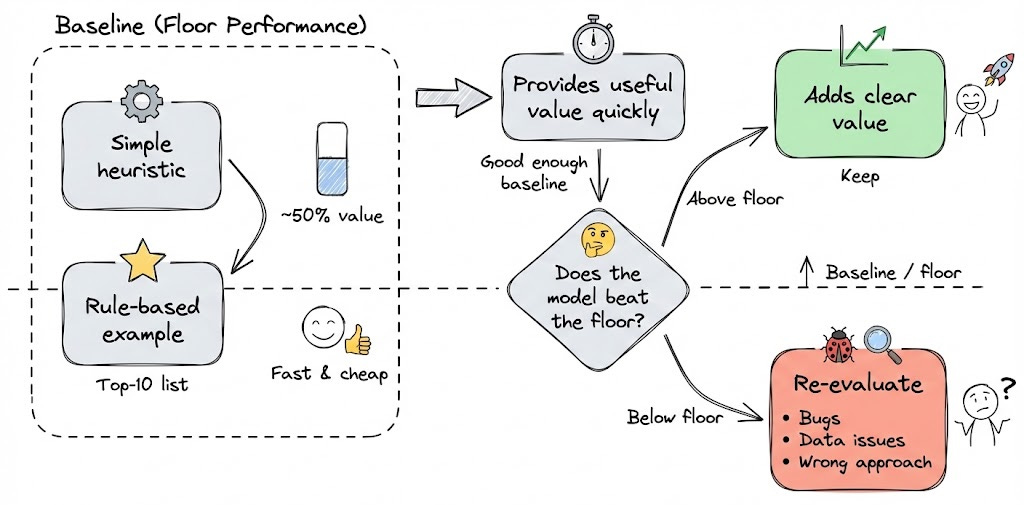
Conceptually, Phase 1 looks like a direct mapping from input to output using rules, without any learning component.
Phase 2: the simplest ML model
Once a heuristic baseline exists (or once it’s clear that heuristics aren’t enough), the next step is not a deep model.
It’s the simplest possible ML model.
Think logistic regression, a shallow decision tree, k-nearest neighbors, or a basic linear model; something easy to train, interpret, and deploy.
The goal here is not peak accuracy. This phase answers foundational questions:
Can we train on historical data and get sensible predictions?
Are the features informative?
Does the model generalize better than the heuristic?
This is where you validate the end-to-end ML pipeline: data ingestion, feature extraction, training, evaluation, and serving.
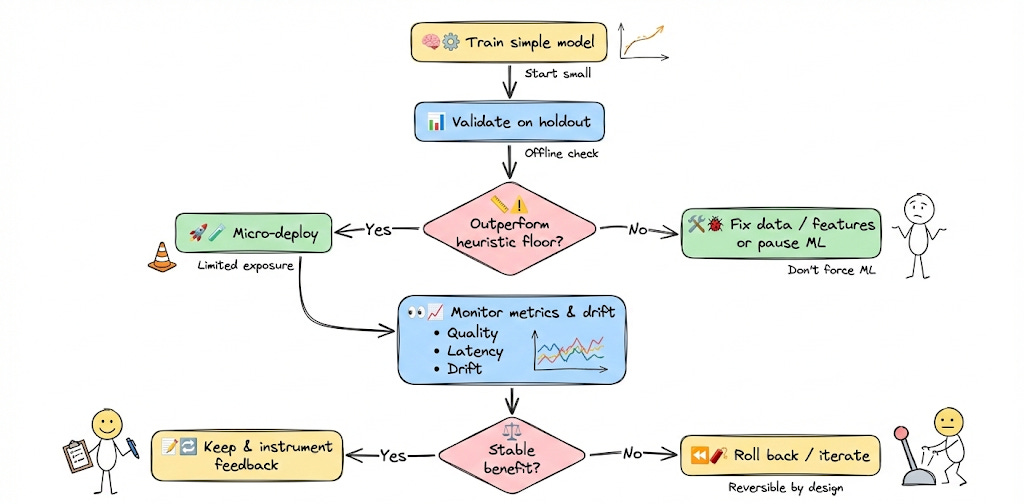
Conceptually, Phase 2 introduces learning, but keeps the model and serving logic minimal.
Phase 3: optimizing the simple model
Once the basic model works, there’s often significant performance left on the table, without changing the model class at all.
Phase 3 focuses on extracting as much value as possible from the existing approach.
Typical levers include:
Feature engineering: creating better representations of the input data.
Hyperparameter tuning: systematically searching for better configurations.
More data: expanding the dataset or improving data quality.
This phase is where returns on investment are often highest.
You’re working with models that are easy to understand, cheap to train, and simple to serve, while still achieving meaningful gains.
Many real-world ML systems stop here. A well-tuned logistic regression, gradient boosted tree, or modest ensemble can meet production requirements without the complexity of deep learning.
Here’s the entire thing summarized as a diagram:
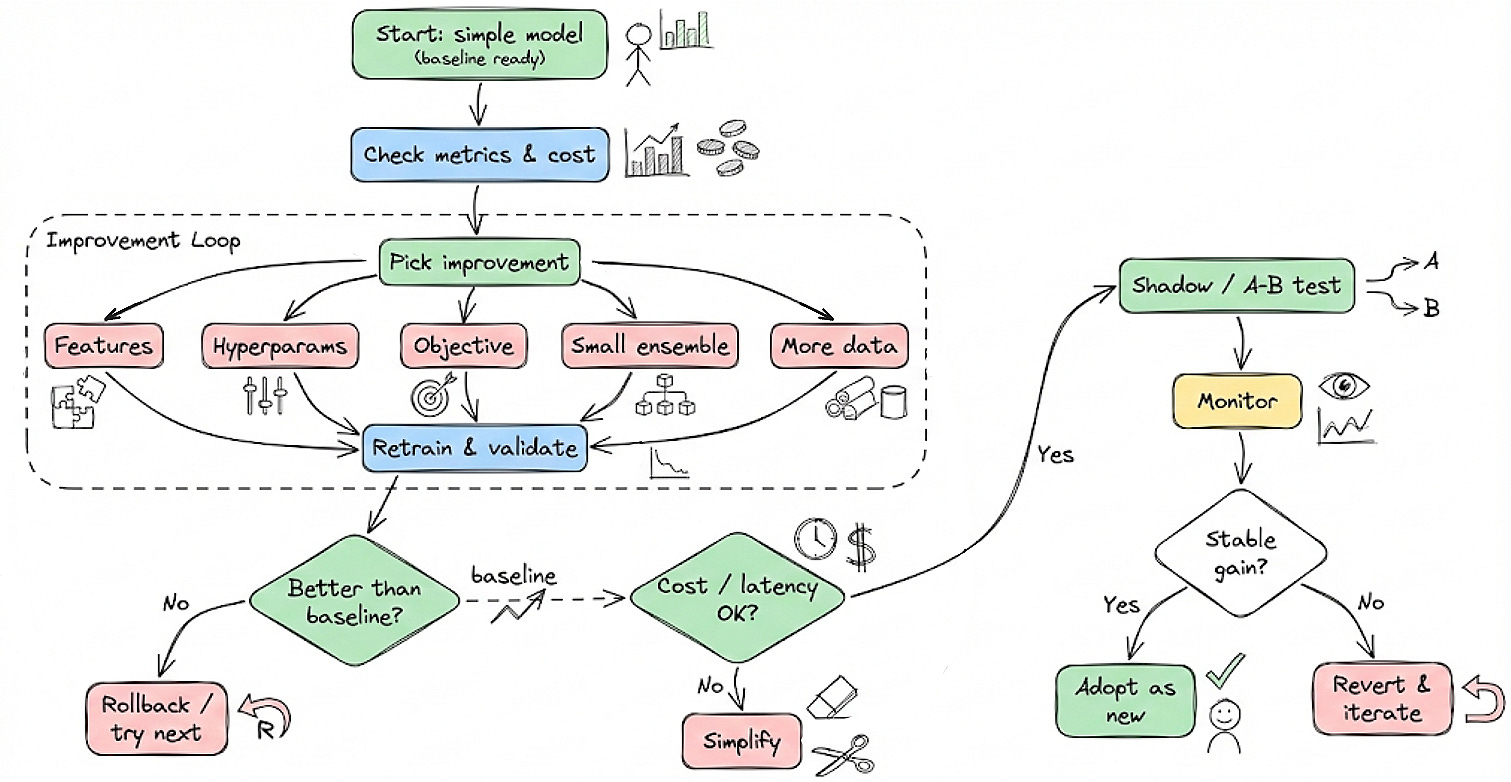
Hence, phase 3 overall, looks like a refinement loop around the same model family, not a shift in paradigm.
Phase 4: complex models
Only after simpler approaches are exhausted should you move to fundamentally more complex models.
This includes deep neural networks, transformers, or large pretrained architectures, depending on the domain.
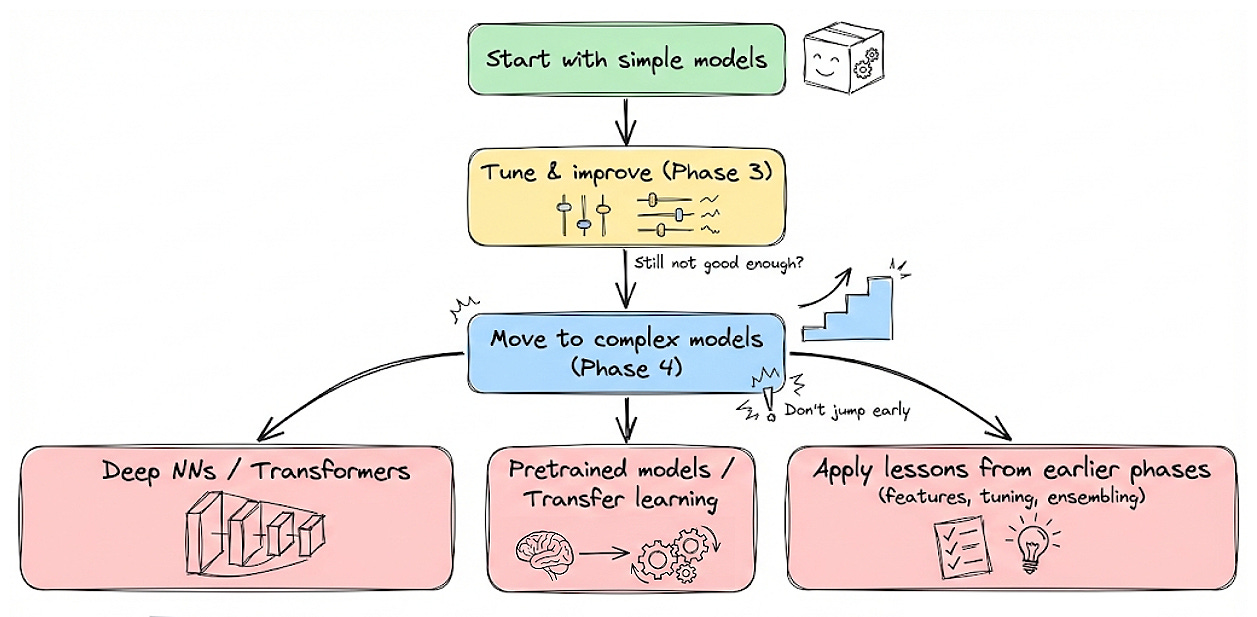
Complex models bring capacity, but also cost. The decision to enter Phase 4 should be evidence-driven.
Conceptually, Phase 4 introduces higher model expressiveness alongside increased engineering complexity.
A key point to keep in mind is, at every phase, the previous phase’s best model becomes the baseline.
This phased approach encourages incremental progress and disciplined decision-making.
If you want to learn more about these real-world ML practices and start your with MLOps, we have already covered MLOps from an engineering perspective in our 18-part crash course.
It covers foundations, ML system lifecycle, reproducibility, versioning, data and pipeline engineering, model compression, deployment, Docker and Kubernetes, cloud fundamentals, virtualization, deep dive into AWS EKS, monitoring and CI/CD in production.
Start with MLOps Part 1 here →
👉 Over to you: Which phase do most of your models actually live in today?
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.