
Platt Scaling for Model Calibration: A Visual Guide
A reliable method to calibrate binary classification models.

For binary classification models, Platt scaling is probably one of the first techniques I resort to if I need to calibrate it.
The below visual summarizes how it works:

Let’s understand what calibration is and how Platt scaling works.
We talked about model calibration in detail in a two-part deep dive below:
The problem
Say a government hospital wants to conduct a medical test on patients. Since the test is expensive, doctors want to ensure that the govt. funding is used optimally.
A reliable estimate from a model reflecting the chances of a patient having the disease can be helpful.
For instance, if the model predicts a 75% probability across some patients, then ideally, out of 100 patients, ~75 should actually have that disease.

This means the model is well calibrated — the confidence and accuracy resonate with each other.
However, many experiments have revealed that modern ML models are typically not well-calibrated.
For instance, consider the following plot which I shared in an earlier issue. It compares a LeNet (developed in 1998) with a ResNet (developed in 2016) on the CIFAR-100 dataset.

LeNet produced:
Accuracy = ~0.55
Average confidence = ~0.54
ResNet produced:
Accuracy = ~0.7
Average confidence = ~0.9
This shows that despite being more accurate, the ResNet model is overconfident in its predictions. While the model thinks it’s 90% confident in its predictions, in reality, it only turns out to be 70% accurate.
This must be fixed if you are reliant on probabilities for decision making.
Calibrating models solves this.
Platt scaling
For binary classification models, Platt scaling is probably one of the first techniques I resort to if I need to calibrate it. Here’s the visual again:
The primary goal is to find a logistic function that maps the raw scores (or logits) from a model to probabilities between 0 and 1.
Note: It is not always necessary to use logits. One may use the predicted probabilities as well if that leads to stable results.
Here’s a step-by-step breakdown of how it works:
Train a model (say, neural network) on the training dataset. This will produce a model that will likely be uncalibrated.
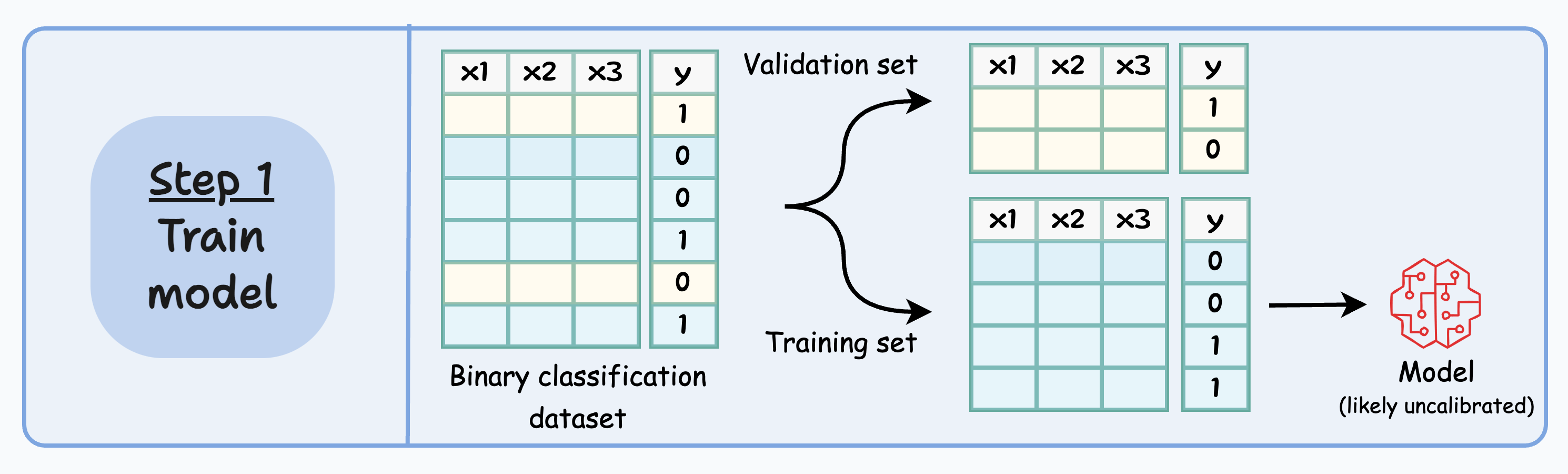
Pass the validation data through the above model and obtain logits (output before converting to probability using sigmoid):

Next, train a logistic regression model that predicts the actual outcome using the above logits. Done!

Now, to generate a calibrated prediction, obtain logit for a new instance using the first (uncalibrated) model. Pass the logit through the logistic regression model train in step 3 to obtain a calibrated probability:

Here’s a plot depicting its efficacy with SVMs. It shows the relationship between predicted and empirical probabilities for the original and calibrated models.

The ideal calibration line (a 45-degree line) indicates perfect calibration, where predicted probabilities match empirical probabilities exactly. From the above plot, it is clear that:
The SVM model (blue line) produces highly miscalibrated probabilities.
With Platt scaling, however, we get much better calibration (not entirely perfect though).
Simple, isn’t it?
That said, one common issue I have noticed with Platt scaling is that it can be sensitive to the amount of data available for calibration. More specifically, when the calibration set is quite small, Platt scaling may not produce reliable probability estimates.
If you want to go through the implementations and learn several other techniques for model calibration that you can utilize (for both binary and multi-class), we covered them in detail in a two-part deep dive below:
👉 Over to you: What is your go-to technique for calibrating binary classification models?
Are you overwhelmed with the amount of information in ML/DS?
Every week, I publish no-fluff deep dives on topics that truly matter to your skills for ML/DS roles.

For instance:
Conformal Predictions: Build Confidence in Your ML Model’s Predictions
Quantization: Optimize ML Models to Run Them on Tiny Hardware
5 Must-Know Ways to Test ML Models in Production (Implementation Included)
8 Fatal (Yet Non-obvious) Pitfalls and Cautionary Measures in Data Science
Implementing Parallelized CUDA Programs From Scratch Using CUDA Programming
You Are Probably Building Inconsistent Classification Models Without Even Realizing
And many many more.
Join below to unlock all full articles:
SPONSOR US
Get your product in front of 85,000 data scientists and other tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.