
Prevent Data Leakage in ML Pipelines
...explained visually.

Scrape any website’s DNA with Firecrawl Branding Format v2
You can now extract complete brand DNA from any website, including color schemes, logos, frameworks, and more in one API call to Firecrawl.
Perfect for coding agents to clone or match existing site aesthetics.
Works with sites built on Wix, Framer, and other no-code builders
Fewer false positive logo extraction
Handles logos hidden in bg images
Try it out now on the playground or API today →
Thanks to Firecrawl for partnering today!
Prevent Data Leakage in ML Pipelines
Data leakage happens when your model accidentally gets access to information during training that it won't have during inference.
And the scary part is that it can be incredibly subtle.
Let us walk you through the most common ways it sneaks in.
Why is data leakage dangerous?
A leaked feature can make a model seem extremely accurate during training/validation, because it’s indirectly using the answer!
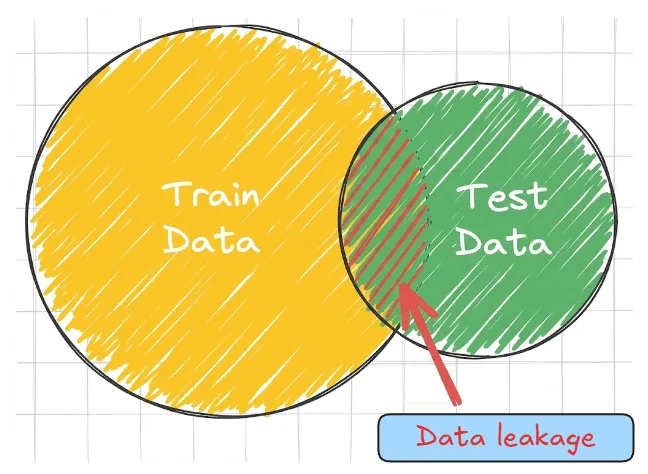
But when deployed, that info isn’t available, so the model fails unexpectedly.
Leakage can be subtle and is often discovered only after deployment, when the model behaves too well on historical data but poorly on new data.
Common causes of data leakage
Train/test contamination
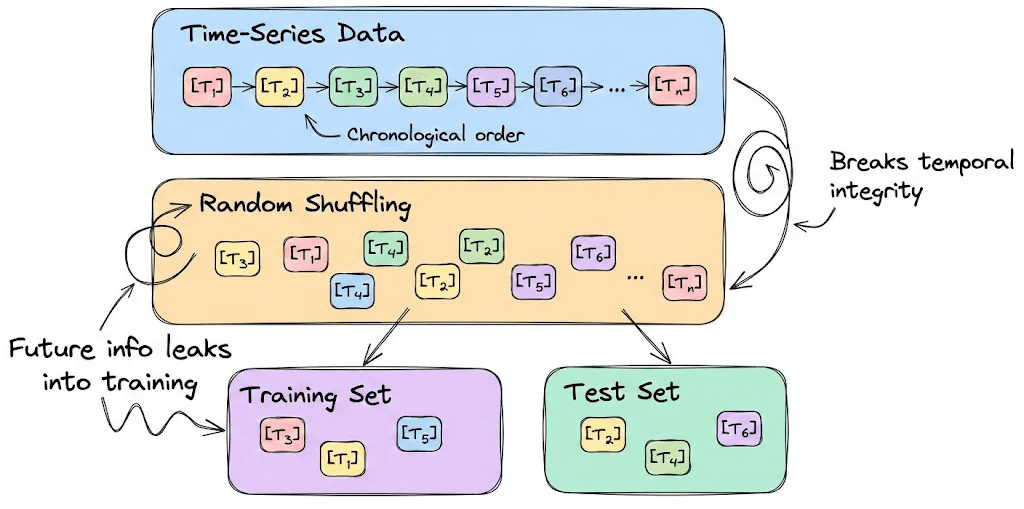
This is the most straightforward but pernicious case. Training data somehow bleeds into the test set. For example, random shuffling might break temporal integrity in time-series data, accidentally leaking future information into the model’s eyes.
Leaking through preprocessing
Do not scale or transform using the combined statistics of your dataset. This subtle form of leakage creeps in when the test data informs transformations like scaling.
For example, scaling features to 0-1 using the min and max of the entire dataset (including test) leaks knowledge of the test distribution into the train.
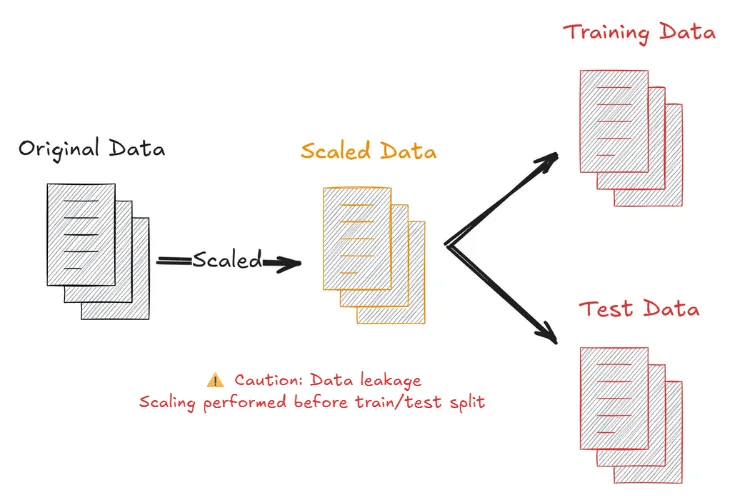
To prevent this type of leakage, always fit preprocessing only on the training set, then apply it to the validation/test sets.
Using target-derived features
This is a common mistake in feature engineering. For instance, say you’re predicting whether a user will churn next month, and you accidentally include a feature like “number of logins in next month,” which obviously references the outcome.
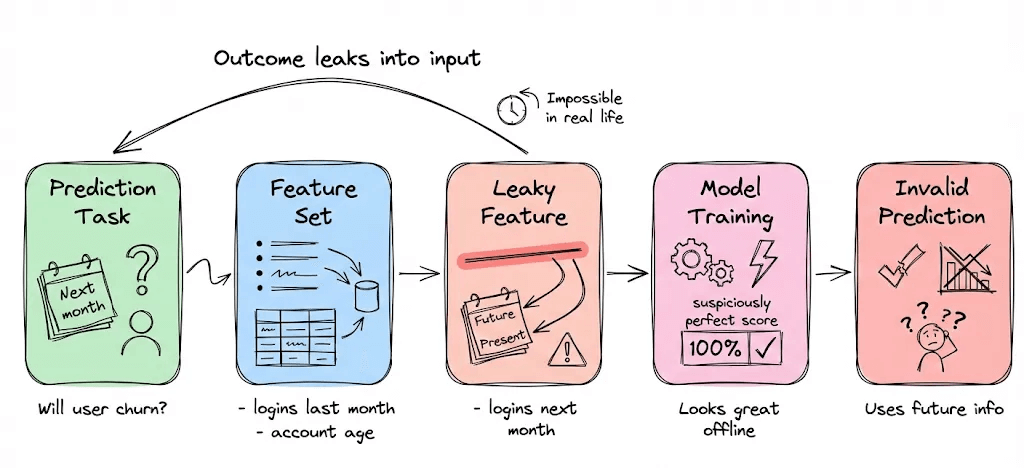
Sometimes this happens less obviously: e.g., you include a summary that was computed including the target period.
How to prevent this? Think carefully. Any feature that wouldn’t be available at prediction time (or that uses information from the future relative to prediction) is a leakage risk.
How to prevent leakage
Holdout validation
Always assess your models on a truly independent dataset. Steep drops in performance from training to evaluation signal potential leakage.

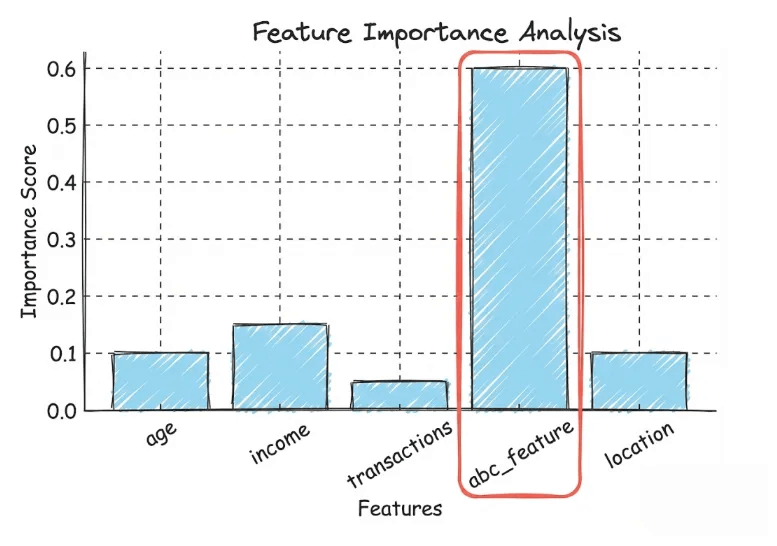
Feature importance analysis
Calculating feature importance reveals suspicious features masquerading as informative only due to leakage. If a particular feature is overwhelmingly important, inspect it; could it be leaking info?
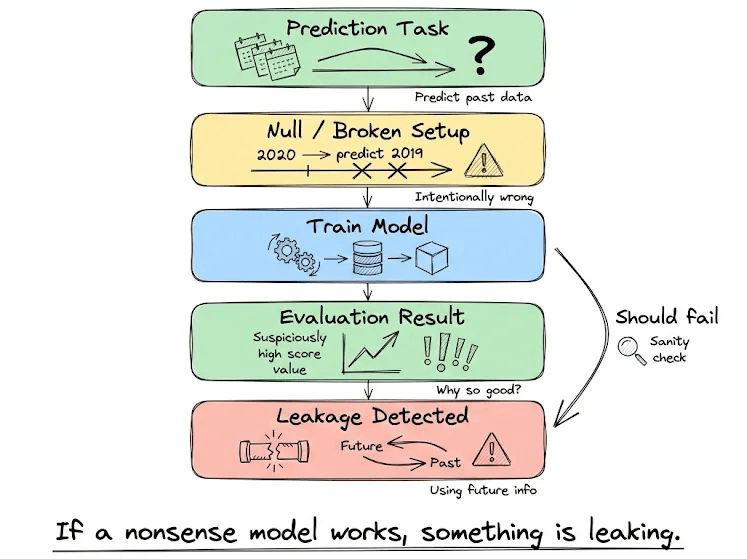
Null model testing
In deliberately nonsensical setups (e.g., predicting 2019 with a 2020 model), leakage causes even ill-formed models to perform inexplicably well.
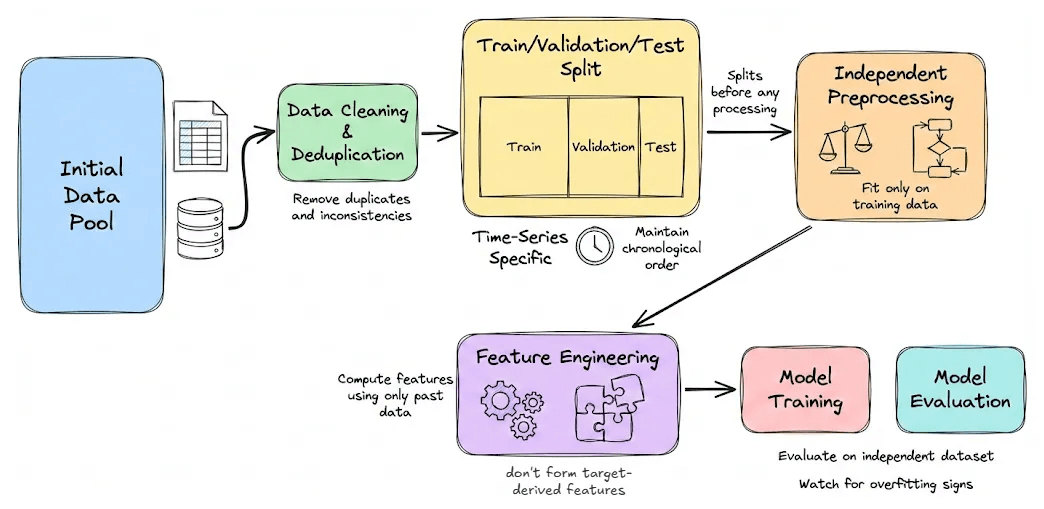
A leak-safe approach
Perform train/validation/test splits before peeking or processing.
Use stats from only the training data for things like scaling and encoding.
In time-dependent data, keep the chronological order for validation.
Understanding leaks and vigilantly safeguarding against them ensures your ML pipeline runs smoothly and reliably in the real world.
If you want to learn more about these real-world ML practices and start your journey with MLOps, we have already covered MLOps from an engineering perspective in our 18-part crash course.
It covers foundations, ML system lifecycle, reproducibility, versioning, data and pipeline engineering, model compression, deployment, Docker and Kubernetes, cloud fundamentals, virtualization, a deep dive into AWS EKS, monitoring, and CI/CD in production.
Start with MLOps Part 1 here →
Thanks for reading!