
Probability and Likelihood Are Not Meant To Be Used Interchangeably
Here's the difference.


In data science and statistics, folks often use “probability” and “likelihood” interchangeably.
However, Likelihood and probability DO NOT convey the same meaning.
And the misunderstanding is somewhat understandable, given that they carry similar meanings in our regular language.
While writing today’s newsletter, I searched for their meaning in the Cambridge Dictionary.
Here’s what it says:
Probability: the level of possibility of something happening or being true/ (Source)
Likelihood: the chance that something will happen. (Source)
It amused me that “likelihood” is the only synonym of “probability”.

Anyway.
In my opinion, it is crucial to understand that probability and Likelihood convey very different meanings in data science and statistics.
Let’s understand!
Probability is used in contexts where you wish to know the possibility/odds of an event.
For instance, what is the:
Probability of obtaining an even number in a die roll?
Probability of drawing an ace of diamonds from a deck?
and so on…
When translated to ML, probability can be thought of as:
What is the probability that a transaction is fraud?
What is the probability that an image depicts a cat?
and so on…

Essentially, many classification models, like logistic regression or a neural network, etc., assign the probability of a specific label to an input.
When calculating probability, the model's parameters are known. Also, we assume that they are trustworthy.
For instance, to determine the probability of a head in a coin toss, we assume and trust that it is a fair coin.
Likelihood, on the other hand, is about explaining events that have already occurred.
Unlike probability (where parameters are known and assumed to be trustworthy)...
Likelihood helps us determine if we can trust the parameters in a model based on the observed data.
Here’s how we use it in the context of data science and machine learning.
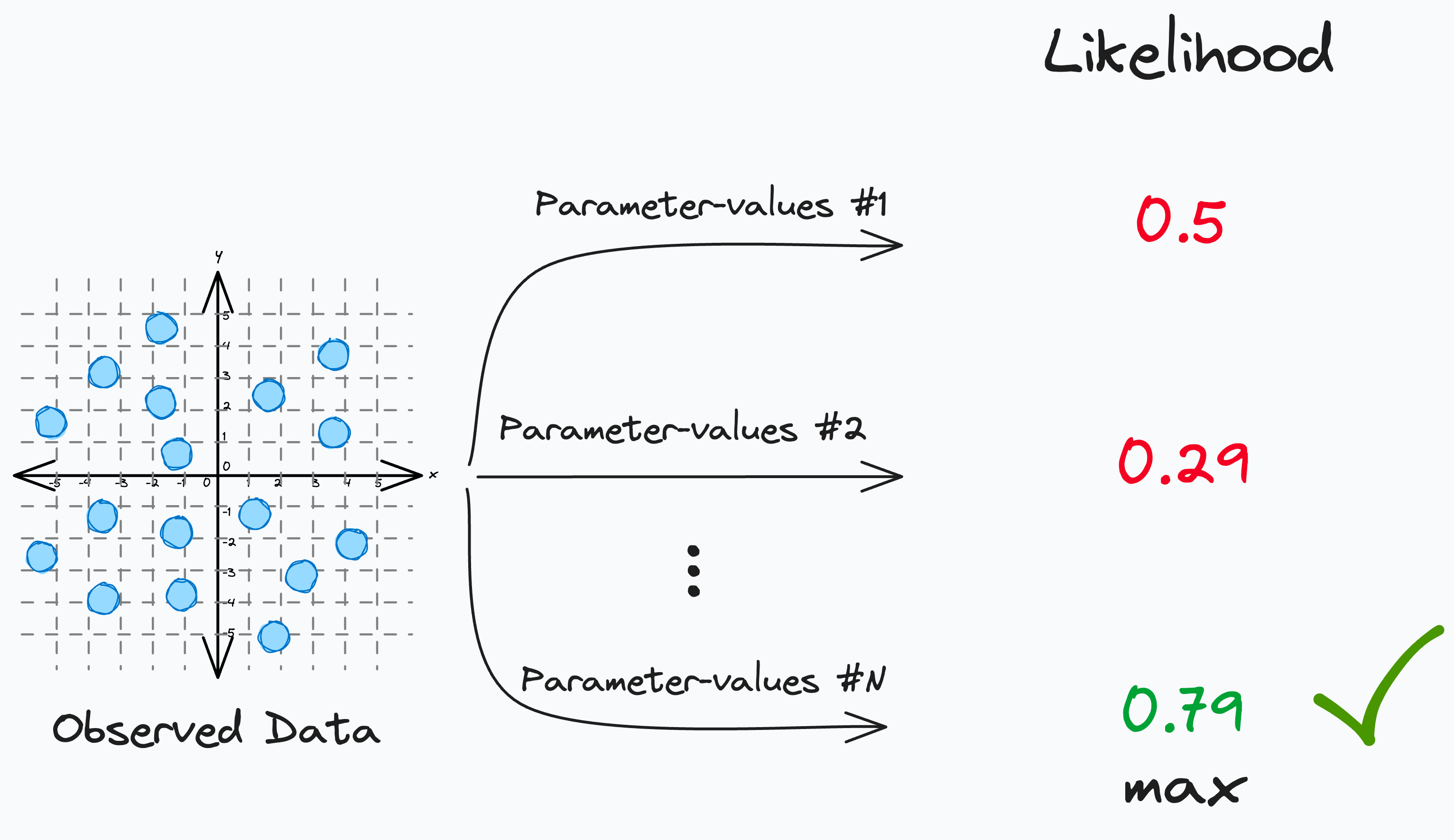
Assume you have collected some 2D data and wish to fit a straight line with two parameters — slope (m) and intercept (c).
Here, Likelihood is defined as the support provided by a data point for some particular parameter values in your model.

Here, you will ask questions like:
If I model this data with the parameters:
m=2andc=1, what is the Likelihood of observing the data?m=3andc=2, what is the Likelihood of observing the data?and so on…
The above formulation popularly translates into the maximum likelihood estimation (MLE).
In maximum likelihood estimation, you have some observed data and you are trying to determine the specific set of parameters (θ) that maximize the Likelihood of observing the data.
Using the term “likelihood” is like:
I have a possible explanation for my data. (In the above illustration, “explanation” can be thought of as the parameters you are trying to determine)
How well my explanation explains what I’ve already observed? This is precisely quantified using Likelihood.
For instance:
Observation: The outcomes of 10 coin tosses are “HHHHHHHTHH”.
Explanation: I think it is a fair coin (p=0.5).
What is the Likelihood that my explanation is true based on the observed data?
To summarize…
It is immensely important to understand that in data science and statistics, Likelihood and probability DO NOT convey the same meaning.
As explained above, they are pretty different.
In Probability:
We determine the possibility of an event.
We know the parameters associated with the event and assume them to be trustworthy.
In Likelihood:
We have some observations.
We have an explanation (or parameters).
Likelihood helps us quantify whether the explanation is trustworthy.
Hope that helped!
👉 Over to you: I would love to hear your explanation of probability and Likelihood. Feel free to share :)
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights. The button is located towards the bottom of this email.
👉 Read what others are saying about this post on LinkedIn and Twitter.
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Find the code for my tips here: GitHub.
I like to explore, experiment and write about data science concepts and tools. You can read my articles on Medium. Also, you can connect with me on LinkedIn and Twitter.
Great explanation 👏👏
For me, in probability the event(data) is varies and the condition(distribution) is fixed, While in likelihood is the opposite event is fixed and condition is varies.
Can you please explain likelihood with a live example.