
Proximal Policy Optimization in RL
The full RL nanodegree, covered with implementation.

The strategy layer most AI engineers never see
95% of enterprise AI projects fail to deliver, and the technology is rarely the problem.
Governance gaps, an inability to justify ROI to finance, and deployment patterns that weren’t built for regulated environments are where things break down.
The AI Strategy Blueprint distills seven years of Fortune 500 and government AI deployments into a book practitioners can actually follow:

The 10-20-70 rule for AI investment
Governance frameworks that accelerate adoption
ROI methods that hold up under CFO scrutiny
Deployment patterns for regulated and air-gapped environments
A maturity roadmap from crawl to scale
Case studies from deployments that shipped
Through our partnership with Iternal Technologies, DailyDoseofDS readers can claim the full book for FREE (PDF or Kindle).
The offer is only valid for the next 72 hours.
Grab your free copy here before time ends →
Deep dive on proximal policy optimization (PPO) in RL
Part 8 of the Reinforcement Learning course is available now.
It covers PPO, the algorithm that laid the foundation for everything we are seeing right now in LLM alignment and modern RL. RLHF for ChatGPT was built on PPO.
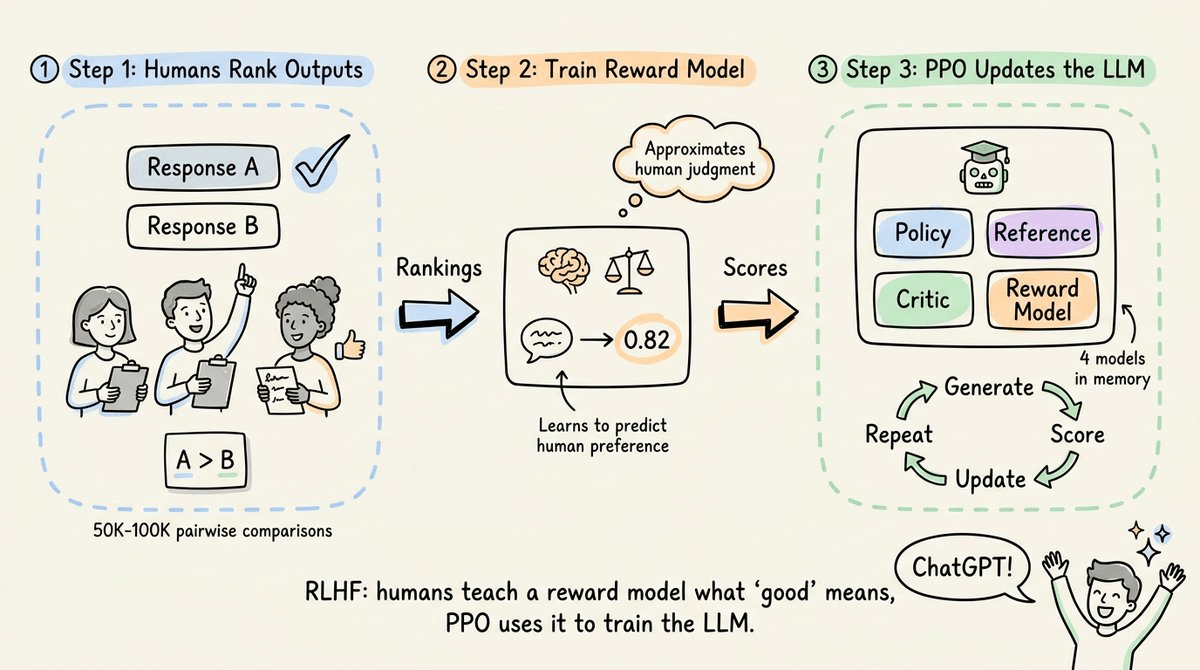
GRPO, DPO, and every major alternative that followed were designed in direct response to it.
You can read Part 8 of the course here →
It covers:
Why large policy updates can cause irreversible collapse
How trust regions keep updates safe
The clipped surrogate objective
How the full PPO algorithm works
The KL-penalty variant used in LLM alignment like PPO
Practical diagnostics for spotting unhealthy training runs
A from-scratch implementation trained on LunarLander
How PPO connects to RLHF for language models
Everything is covered from scratch, so no RL background is required.
You can read Part 8 of the course here →
Why care?
PPO is the algorithm that started the current era of LLM alignment.
When OpenAI first aligned language models with human preferences, the RL algorithm underneath was PPO.
Every major alternative that came after was designed with PPO as the reference point.
DPO was introduced specifically to avoid the complexity of running PPO’s RL loop.
GRPO modified the advantage estimation to remove the need for a learned critic.
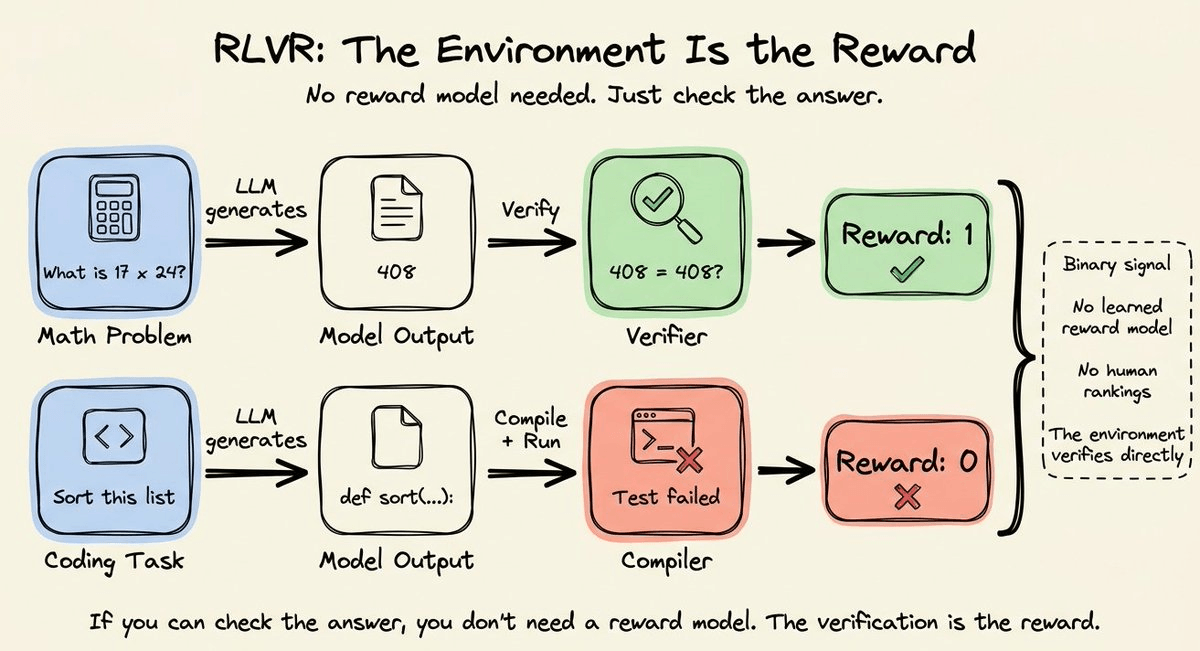
Constitutional AI restructured the reward signal but kept the same trust-region optimization underneath.
You cannot fully understand any of these methods without understanding the algorithm they are all responding to.
Beyond language models, PPO remains the go-to algorithm across robotics, game-playing, and agentic systems.
It earned that position by being simple enough to implement in a few hundred lines of PyTorch and robust enough to handle a remarkably wide range of problems with minimal tuning.
This chapter is also the convergence point of the series. Every idea we have covered so far (value functions, policy gradients, actor-critic, GAE) comes together here into one working system.
Here’s what we have covered so far:
Just like the MLOps course, each chapter will clearly explain necessary concepts, provide examples, diagrams, and implementations.
👉 Over to you: What topics would you like us to cover in this RL series?
Thanks for reading!