
RAG, Agentic RAG, and AI Memory
...explained visually.

Everyone building AI agents keeps making the same database mistake!

Developers often give agents direct access to production databases, assuming rate limits and permissions will keep things safe.
In reality, agents explore at machine speed. They parallelize queries, create and drop indexes mid-flight, test migrations, roll them back, and unintentionally overload production systems that were built for cautious human workflows.
The fix is simple: databases that can fork instantly.
Tiger Data just released Agentic Postgres, a new database built for agent workflows. It lets agents spin up a full database fork in seconds, run destructive experiments safely, then delete the fork when done. No impact on production.
It also ships with a built-in MCP server that teaches agents real Postgres reasoning, hybrid search for retrieval, and memory APIs for persistent context.
We tested it with Claude Code, and the difference is clear.
You can try it yourself here →
Thanks to Tiger Data for partnering today!
RAG, Agentic RAG, and AI Memory
RAG was never the end goal.
Memory in AI agents is where everything is heading.
Let’s break down this evolution in the simplest way possible.
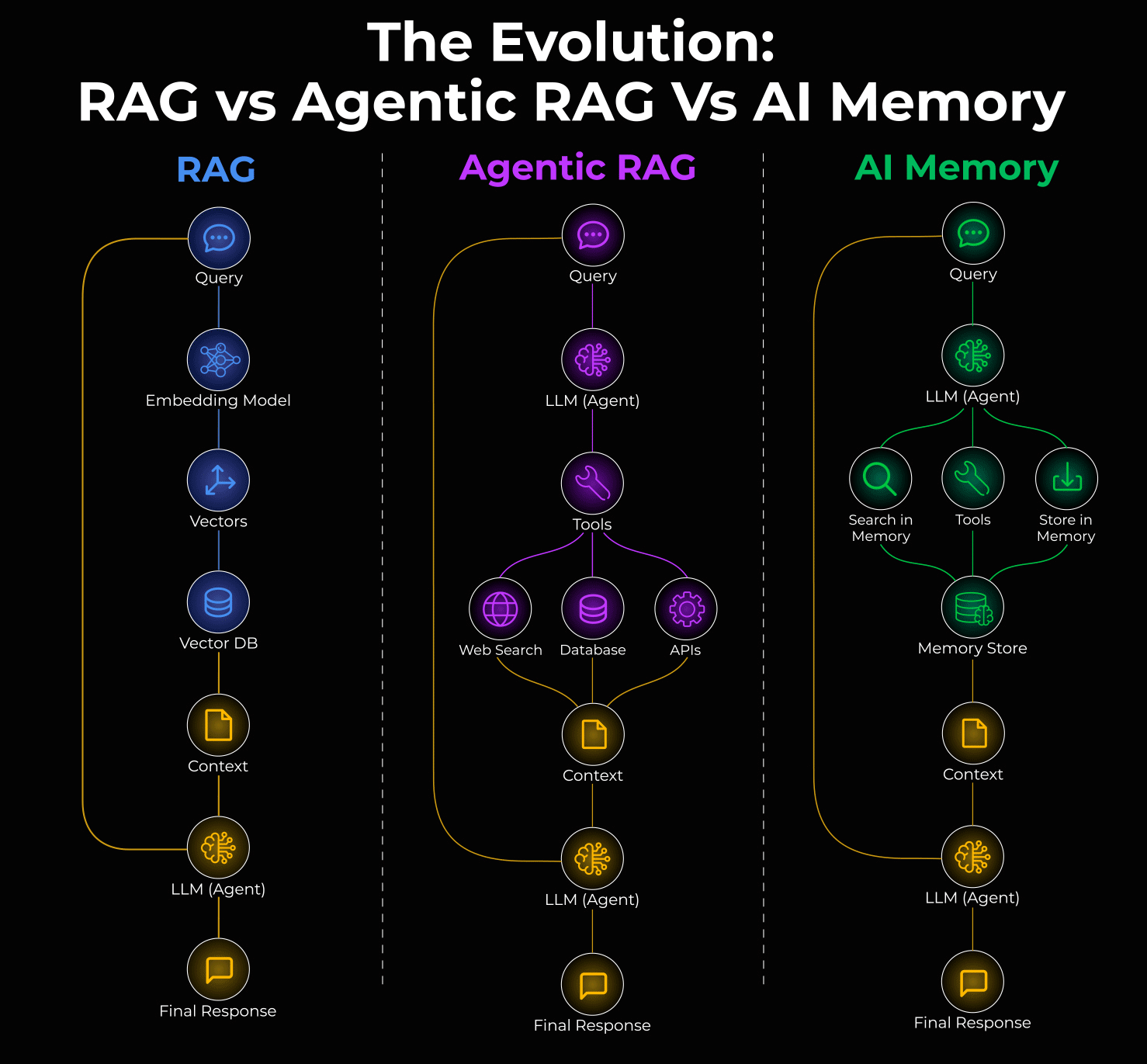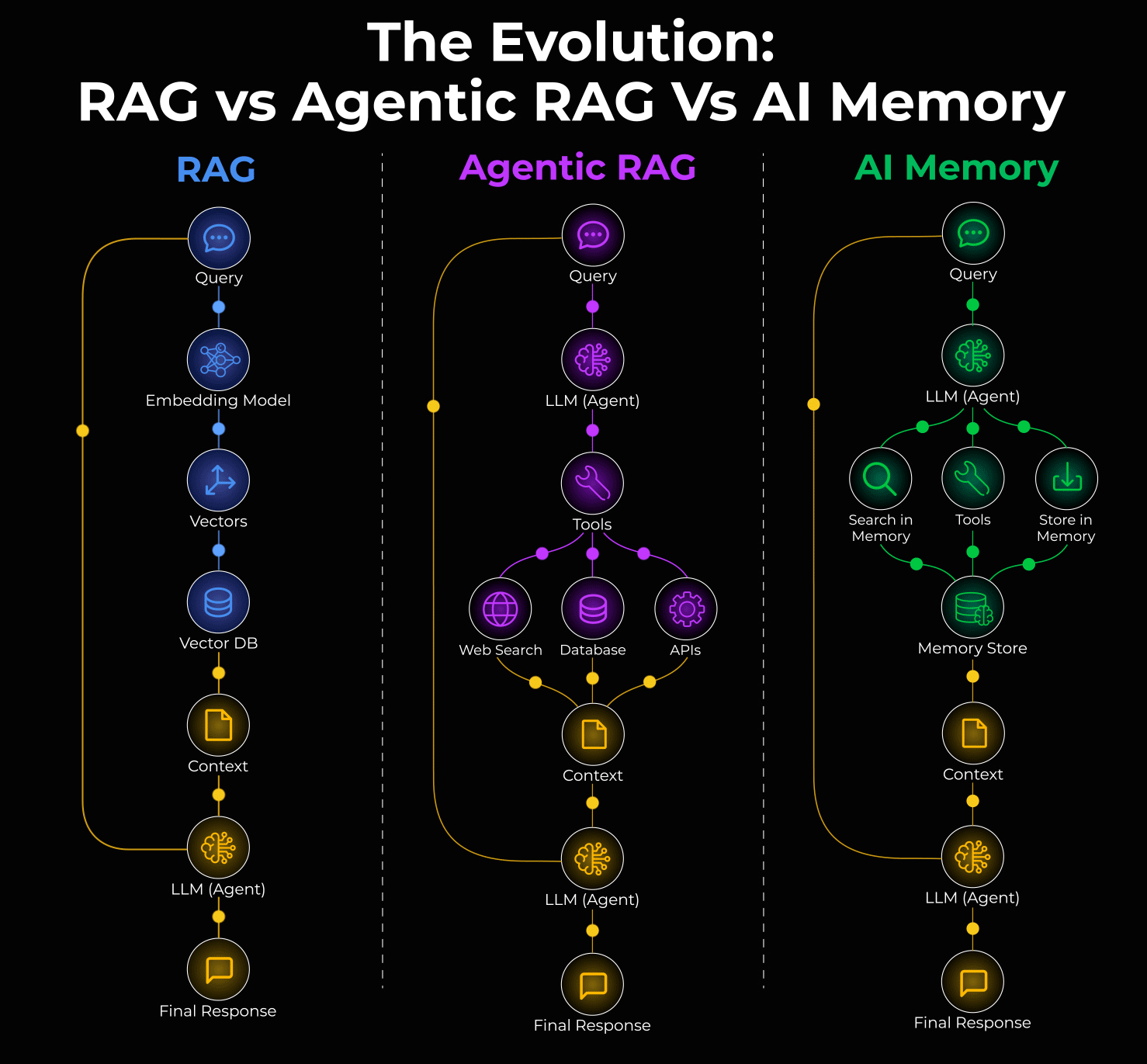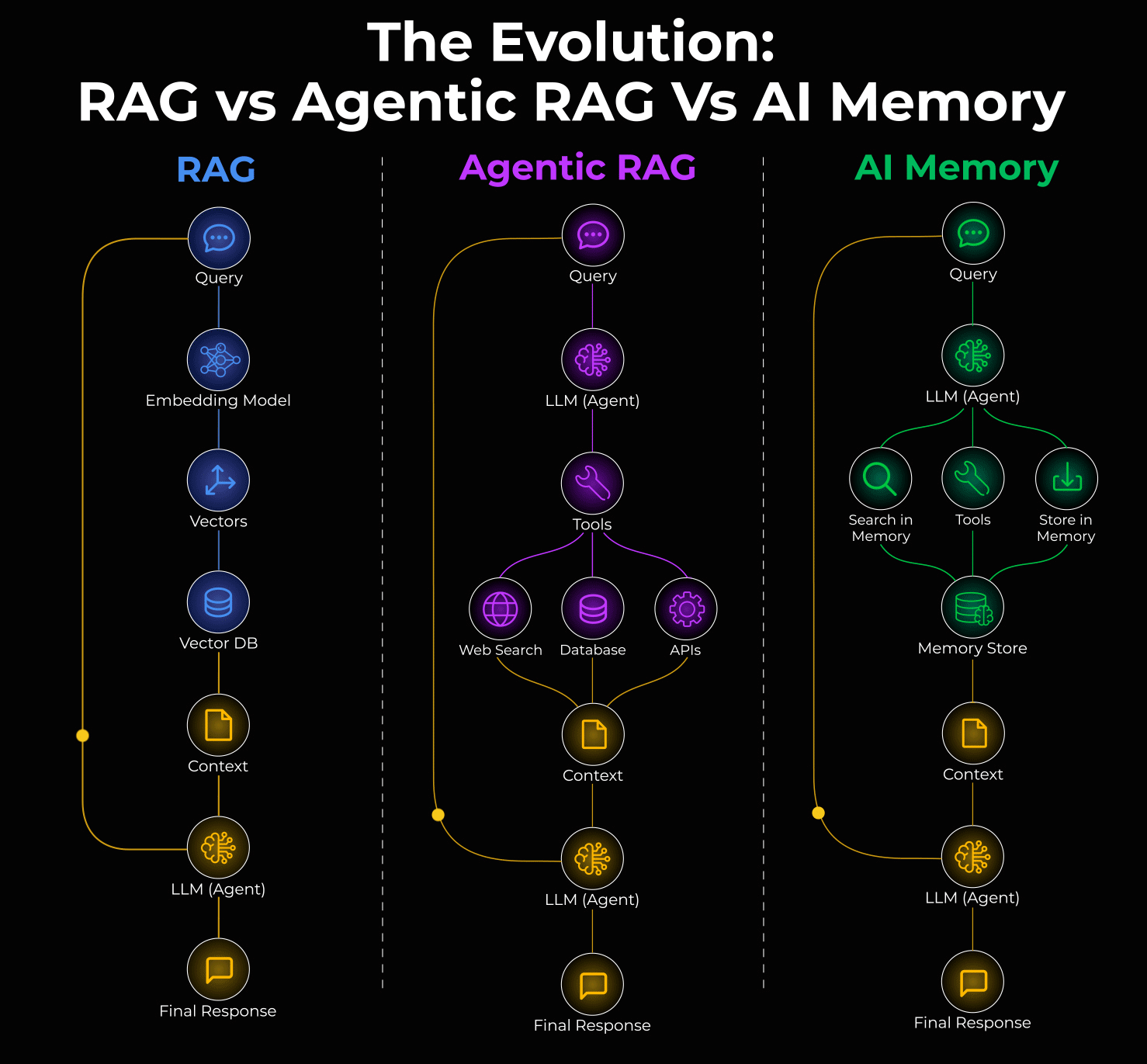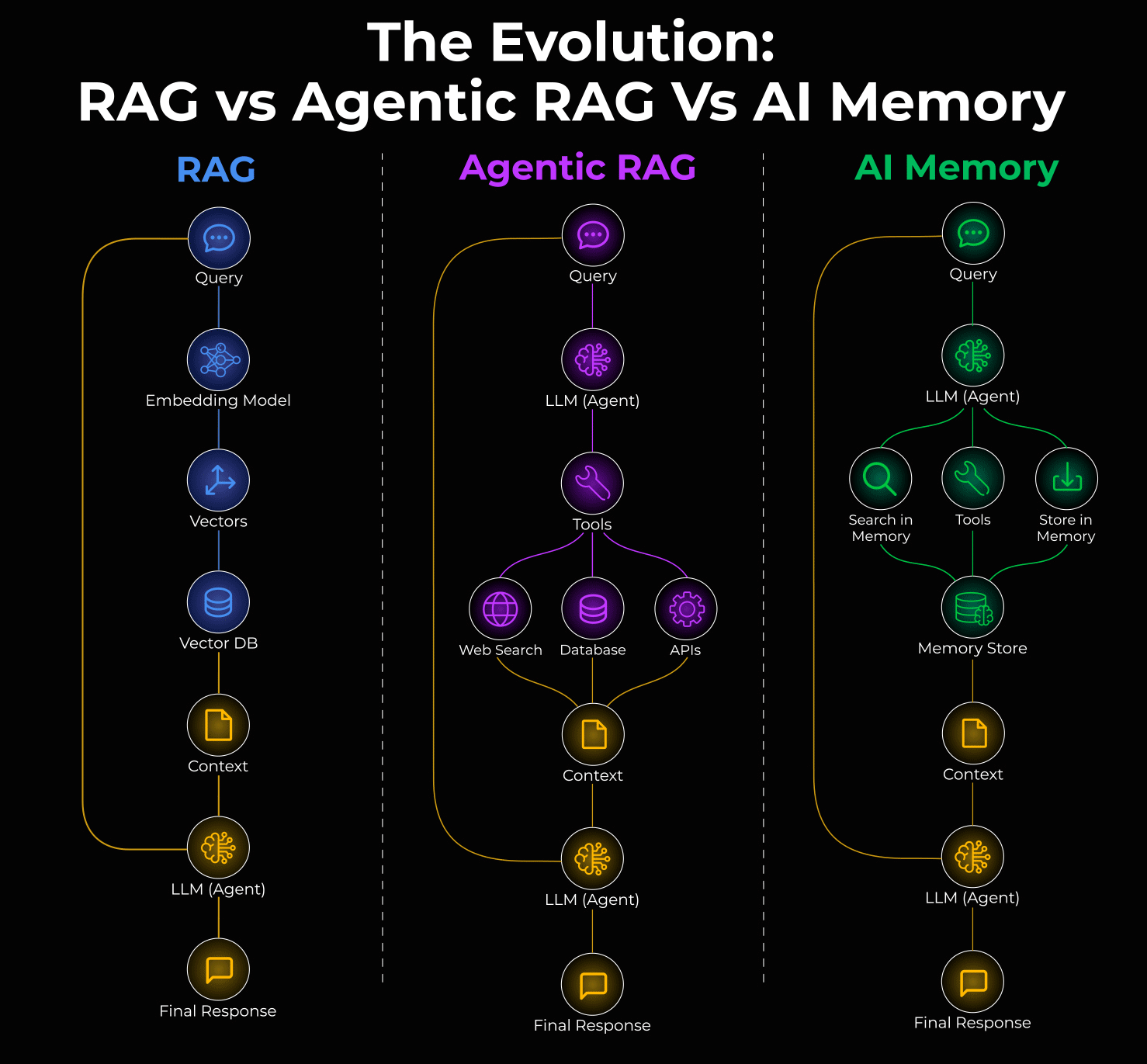
RAG (2020-2023):
Retrieve info once, generate response
No decision-making, just fetch and answer
Problem: Often retrieves irrelevant context
Agentic RAG:
Agent decides *if* retrieval is needed
Agent picks *which* source to query
Agent validates *if* results are useful
Problem: Still read-only, can’t learn from interactions
AI Memory:
Reads AND writes to external knowledge
Learns from past conversations
Remembers user preferences, past context
Enables true personalization
The mental model is simple:
RAG: read-only, one-shot
Agentic RAG: read-only via tool calls
Agent Memory: read-write via tool calls
Here’s what makes agent memory powerful:
The agent can now “remember” things, like user preferences, past conversations, and important dates. All stored and retrievable for future interactions.
This unlocks something bigger: continual learning.
Instead of being frozen at training time, agents can now accumulate knowledge from every interaction. They improve over time without retraining.
Memory is the bridge between static models and truly adaptive AI systems.
But it’s not all smooth sailing.
Memory introduces new challenges RAG never had: memory corruption, deciding what to forget, and managing multiple memory types (procedural, episodic, and semantic).
Solving these problems from scratch is hard. If you want to give your agents human-like memory, check out Graphiti, an open-source framework for building real-time knowledge graphs.
You can find the GitHub repo here →
8 key LLM development skills for AI engineers
Working with LLMs isn’t just about prompting.
Production-grade systems demand a deep understanding of how LLMs are engineered, deployed, and optimized.
Here are the eight pillars that define serious LLM development:
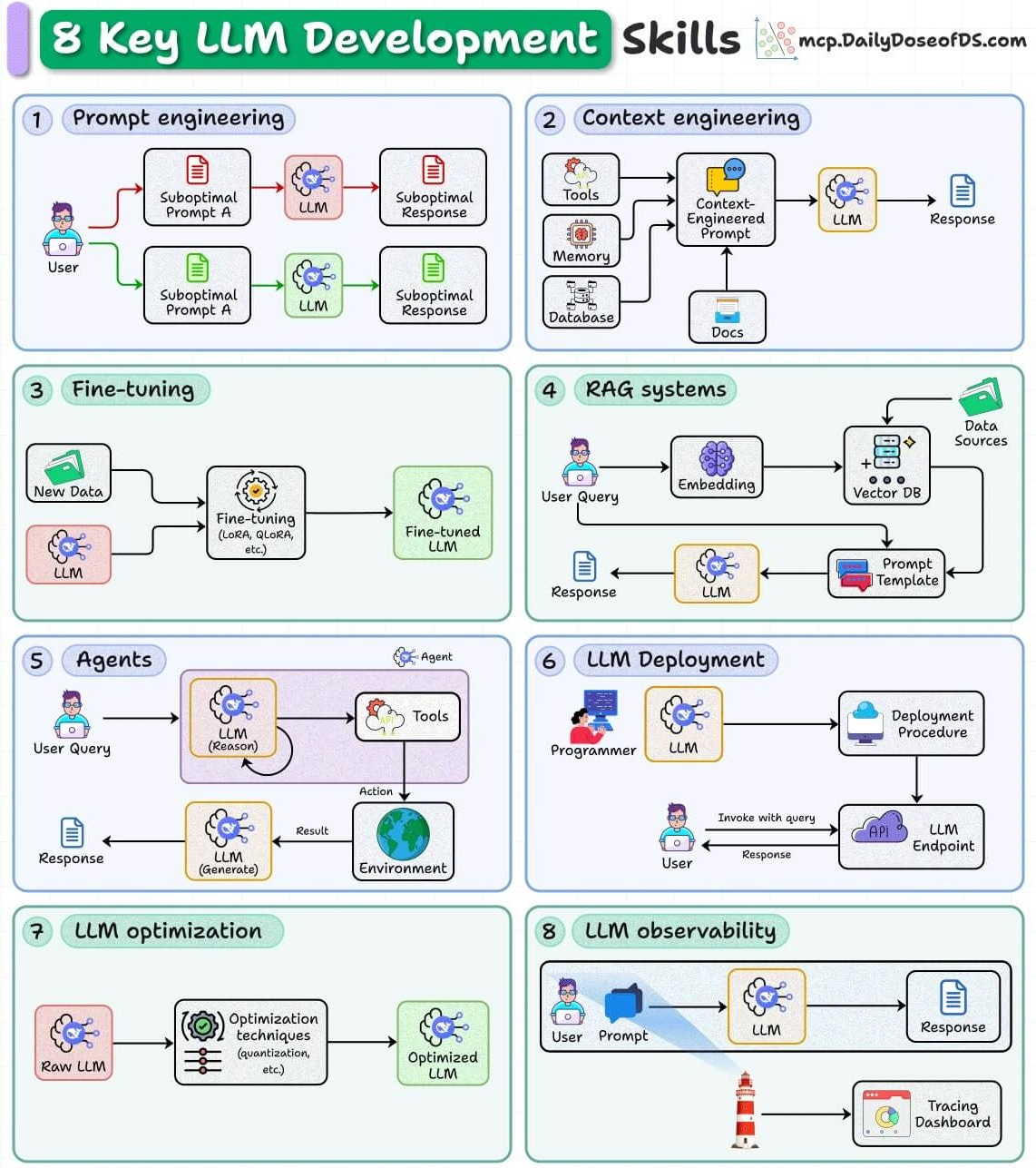
Let’s understand each of them:
1. Prompt engineering
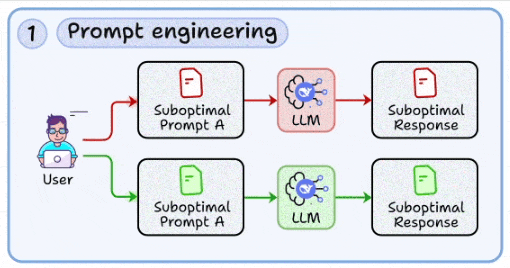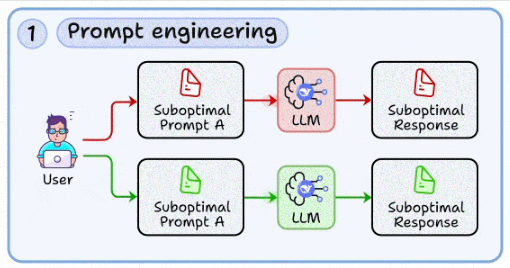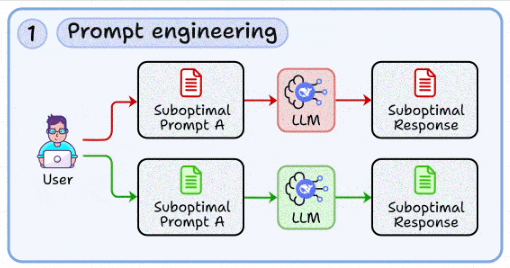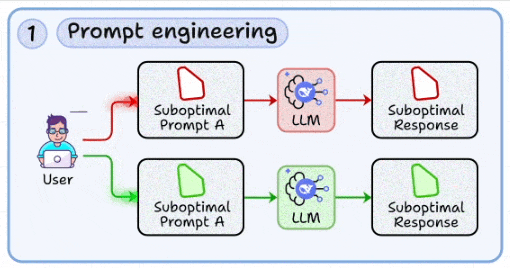
The most basic skill is to craft structured prompts that reduce ambiguity and guide model behavior toward deterministic outputs.
This involves iterating quickly with variations, using patterns like chain-of-thought, and a few-shot examples to stabilize responses (covered here).
Treating prompt design as a reproducible engineering task, not trial-and-error copywriting.
2. Context engineering
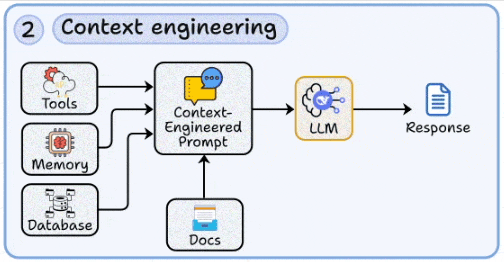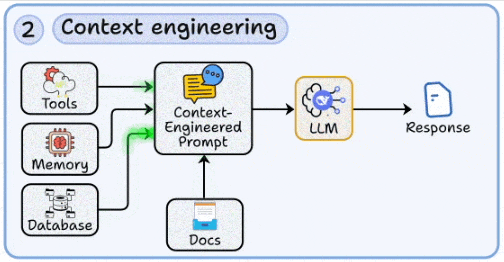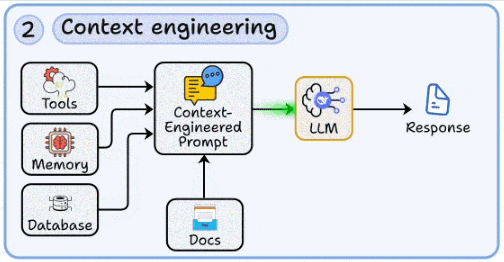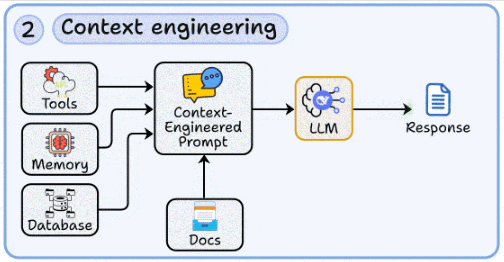
Dynamically injecting relevant external data (databases, memory, tool outputs, documents) into prompts.
Designing context windows that balance completeness with token efficiency.
Handling retrieval noise and context collapse, critical in long-context scenarios.
We’ll be doing a demo on context engineering pretty soon to make this more concrete.
3. Fine-tuning
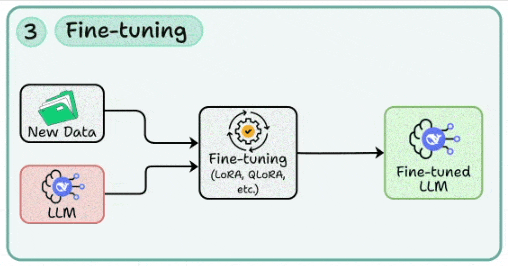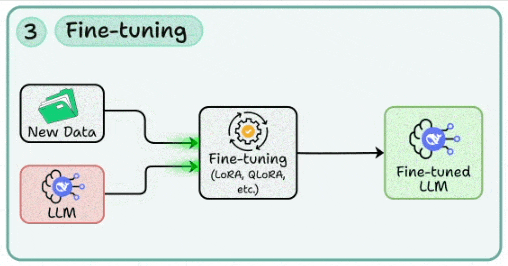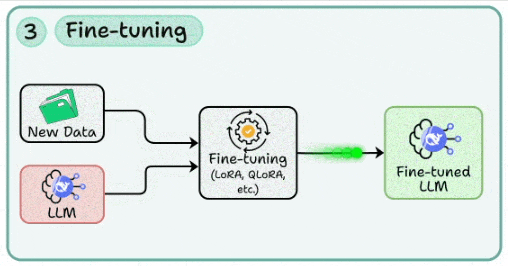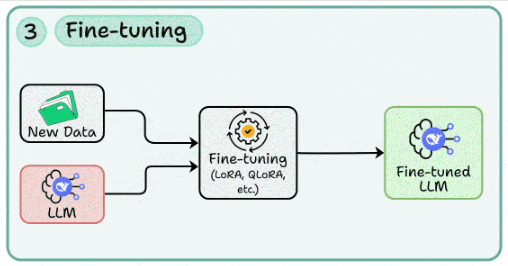
In many cases, you may need to tweak the LLM’s behaviour to your use cases. This skill involves applying methods like LoRA/QLoRA to adapt a base model with domain-specific data while keeping compute costs low.
Managing data curation pipelines (deduplication, instruction formatting, quality filtering).
Monitoring overfitting vs. generalization when extending the model beyond zero/few-shot capabilities.
We implemented LoRA here and DoRA here and covered 5 more techniques for fine-tuning LLMs here.
4. RAG systems
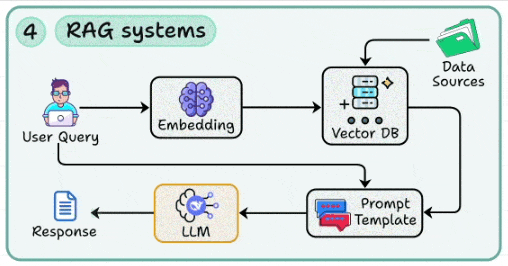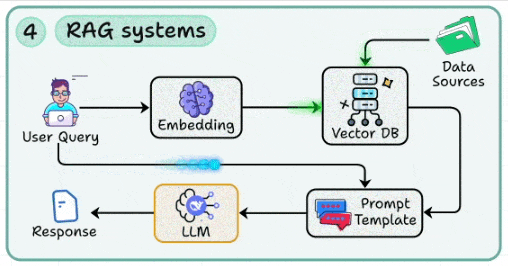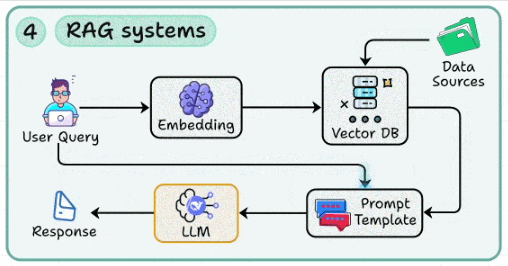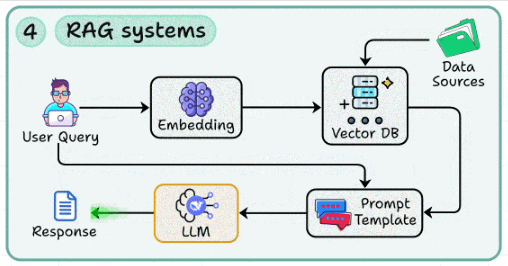
This skill lets you build systems that can augment LLMs with external knowledge via embeddings + vector DBs to reduce hallucinations.
Engineering retrieval pipelines (indexing, chunking, query rewriting) for high recall and precision.
Using prompt templates that fuse retrieved context with user queries in a structured way.
This 9-part rag crash course covers everything with implementation →
5. Agents
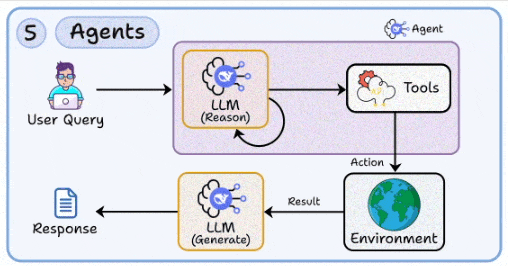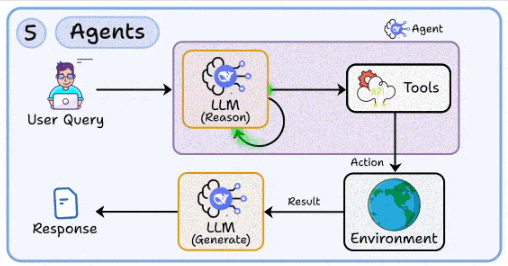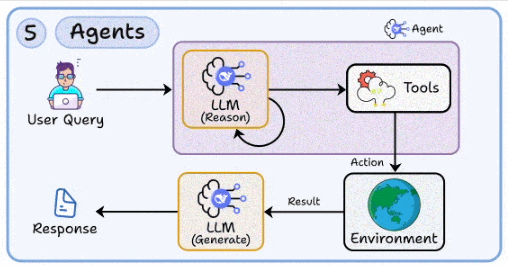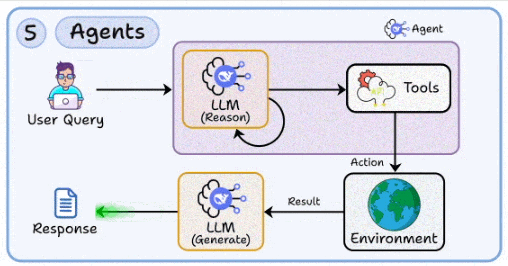
With this skill, you learn to move beyond static Q&A by orchestrating multi-step reasoning loops with tool use.
Handling environment interactions, state management, and error recovery in autonomous workflows.
Designing fallbacks for when reasoning paths fail or external APIs return incomplete results.
This 14-part Agents crash course covers everything with implementation →
This mini crash course is also a good starting point that covers:
What is an AI Agent
Connecting Agents to tools
Overview of MCP
Replacing tools with MCP servers
Setting up observability and tracing
6. LLM deployment
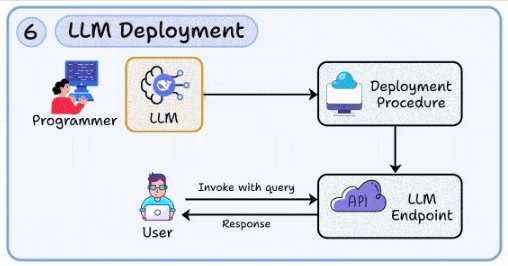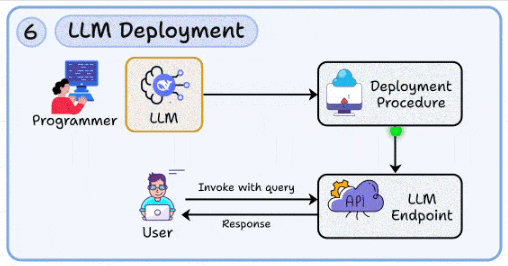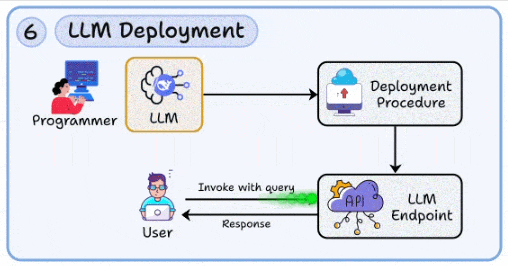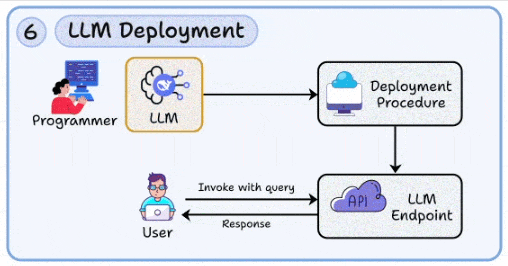
At this stage, you have likely built your LLM app. This skill lets you package models into production-grade APIs with scalable deployment pipelines.
Managing latency, concurrency, and failure isolation (think: autoscaling + container orchestration).
Building guardrails around access, monitoring cost per request, and controlling misuse.
Open-source frameworks like Beam can help. GitHub repo →
7. LLM optimization
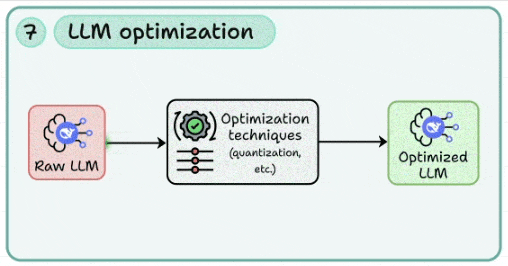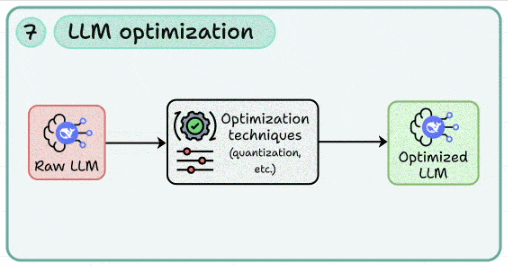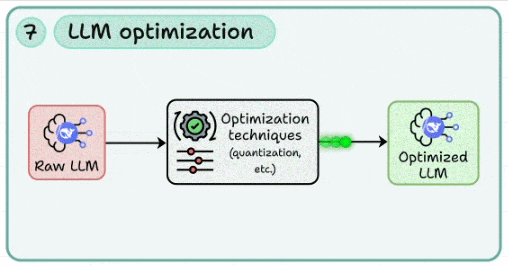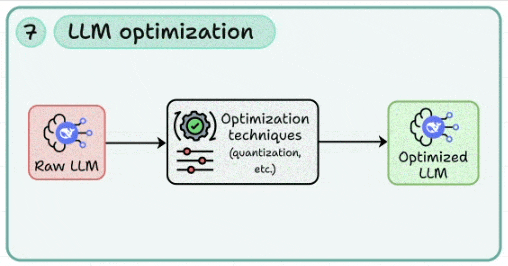
To reduce costs, you need to learn how to apply quantization, pruning, and distillation to reduce memory footprint and inference costs.
This lets you benchmark trade-offs between speed, accuracy, and hardware utilization (GPU/CPU offloading).
Continuously profiling models to ensure optimization doesn’t compromise core functionality.
8. LLM observability
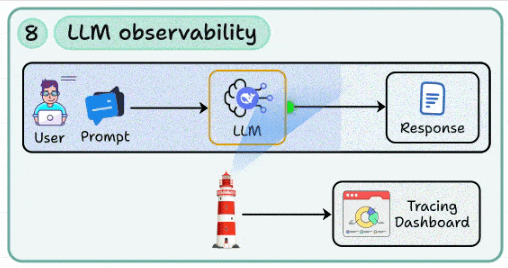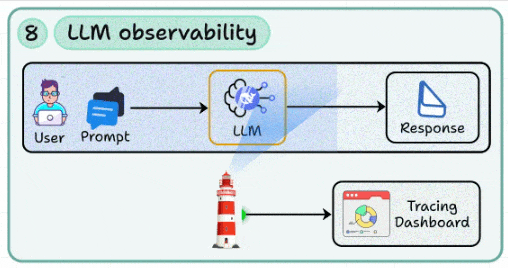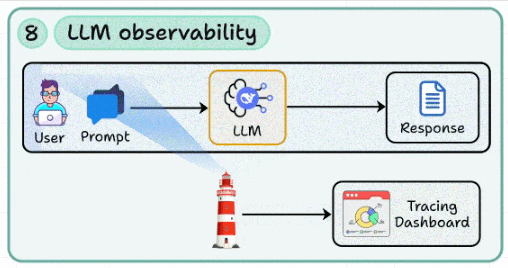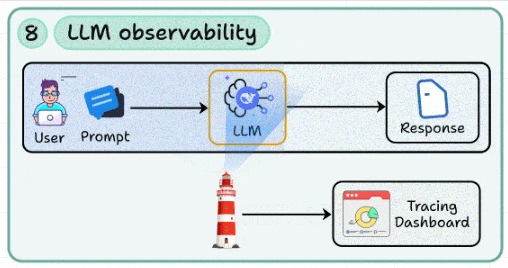
No matter how simple or complex your LLM app is, you must learn how to implement tracing, logging, and dashboards to monitor prompts, responses, and failure cases.
Tracking token usage, latency spikes, and prompt drift in real-world traffic.
Feeding observability data back into iteration cycles for continuous improvement.
This practical guide covers integrating evaluation and observability into LLM apps →
👉 Over to you: What other LLM development skills will you add here?
Thanks for reading!
This is great, incredibly clear designed post!
Hi Avi..I hope you are well. I have e been reading a few of your posts and they are very intriguing. I just want to know exactly where, I know some RAG flows you ha e mentioned it being done on Figma, do you make your diagrams/Rag flows etc..is there a way we could discuss or you could help? Would be very interested in knowing more