
RAG & Fine-tuning in LLMs
...explained visually.

One MCP server to access the web
When Agents use web-related tools, they run into issues like IP blocks, bot traffic, captcha solvers, etc.
Agents get rate-blocked or rate-limited.
Agents have to deal with JS-heavy or geo-restricted sites.
This hinders the Agent’s execution.
Bright Data MCP server gives you 30+ powerful tools that allow AI agents to access, search, crawl, and interact with the web without getting blocked.

The video below depicts the browser tool usage from Bright Data, where the Agent is autonomously navigating a web page.
Unlike typical scraping tools, this MCP server dynamically picks the most effective tool based on the structure of the target site.
These are some of the tools:

Browser tool
Web Unlocker API
Scraper API
Platform-specific scrapers for Instagram, LinkedIn, YouTube, etc.
SERP API, and more.
You can try the MCP server using this GitHub repo →
The steps are detailed in the GitHub repo.
RAG & Fine-tuning in LLMs
If you’re building real-world LLM apps, you can rarely use a model out of the box without adjustments.
Devs typically treat RAG and fine-tuning as interchangeable options, but in reality, they are not.
RAG and fine-tuning solve fundamentally different problems. One controls what the model knows at runtime. The other changes how the model behaves by default.
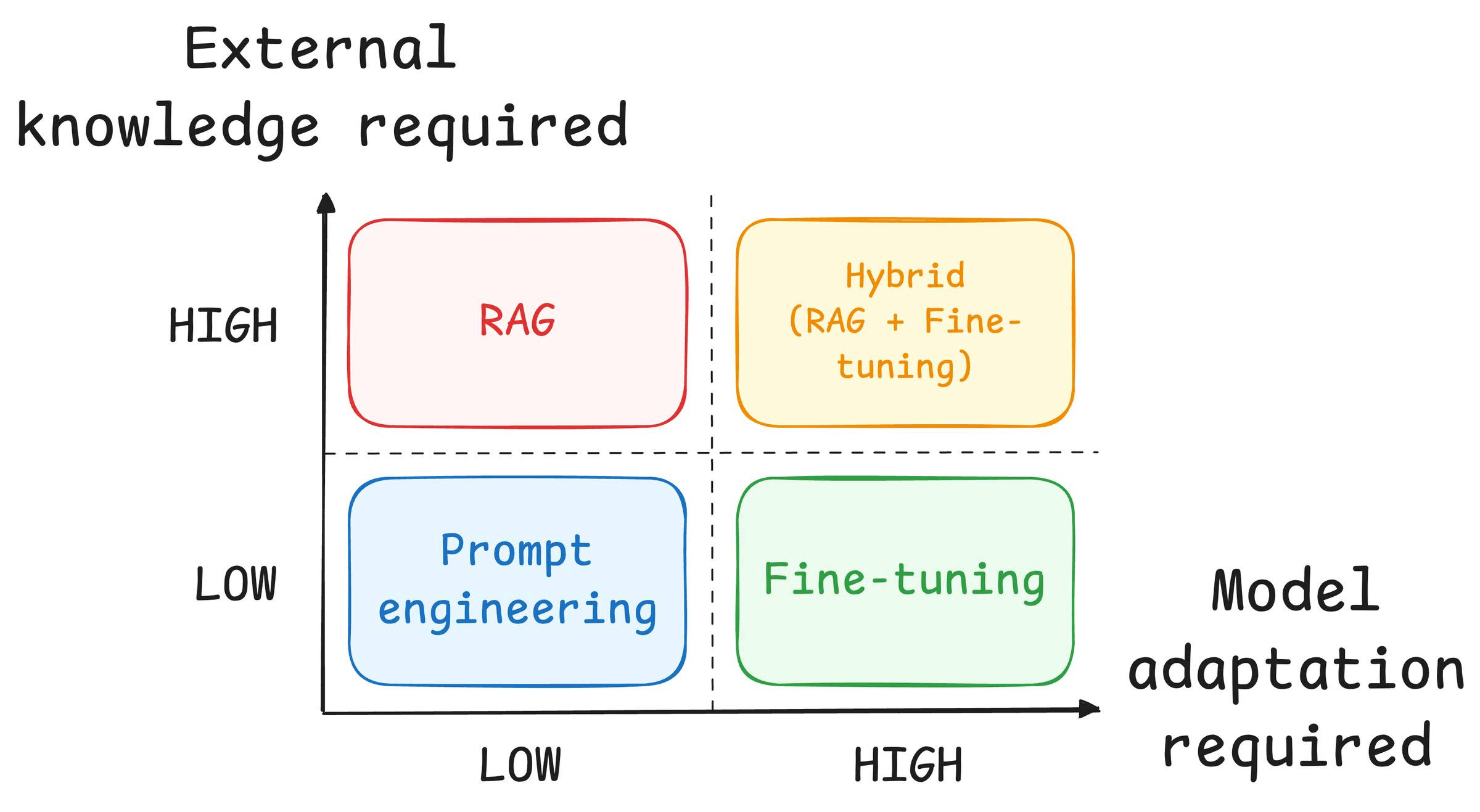
This visual breaks it down for you:
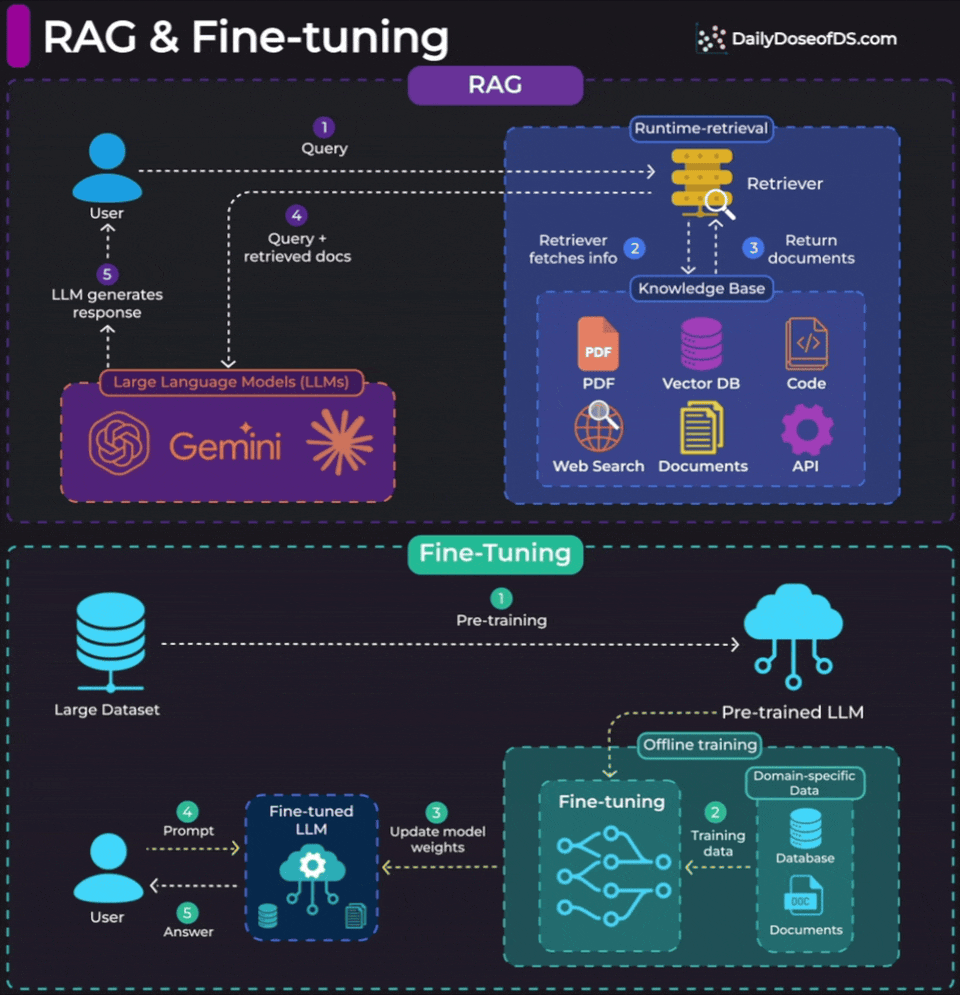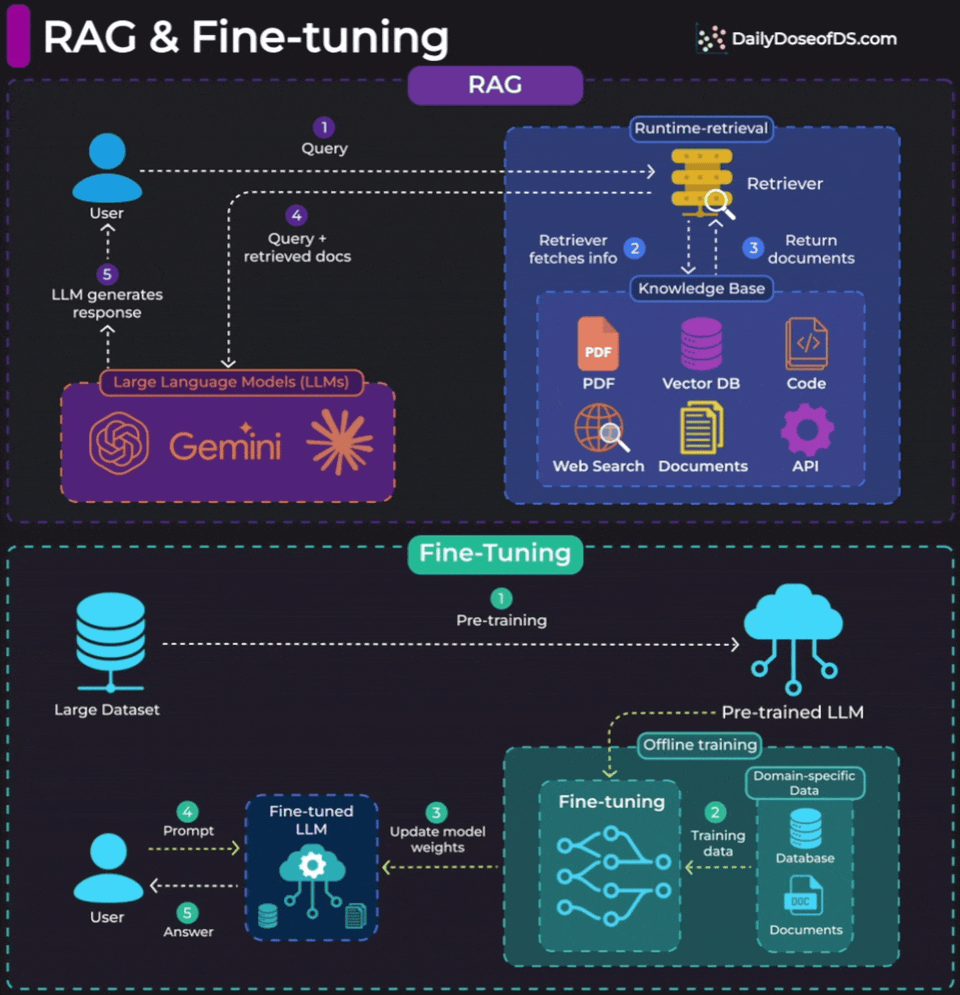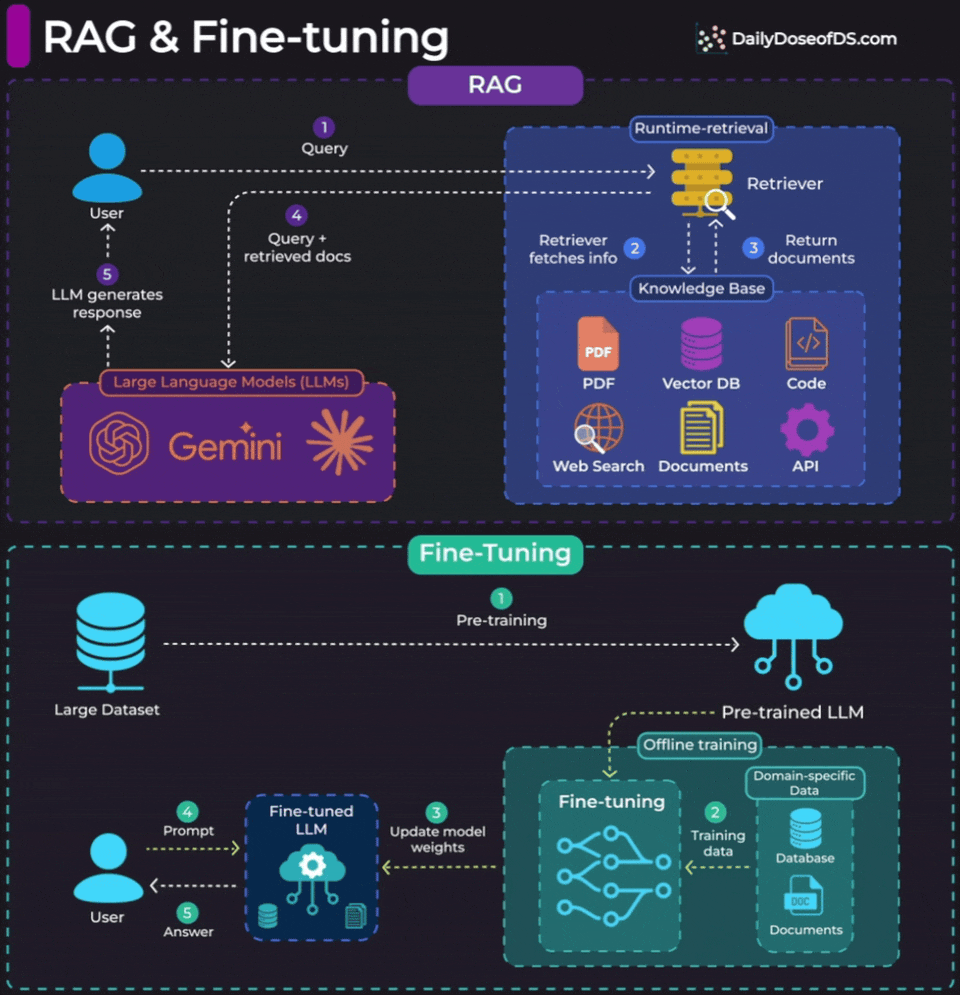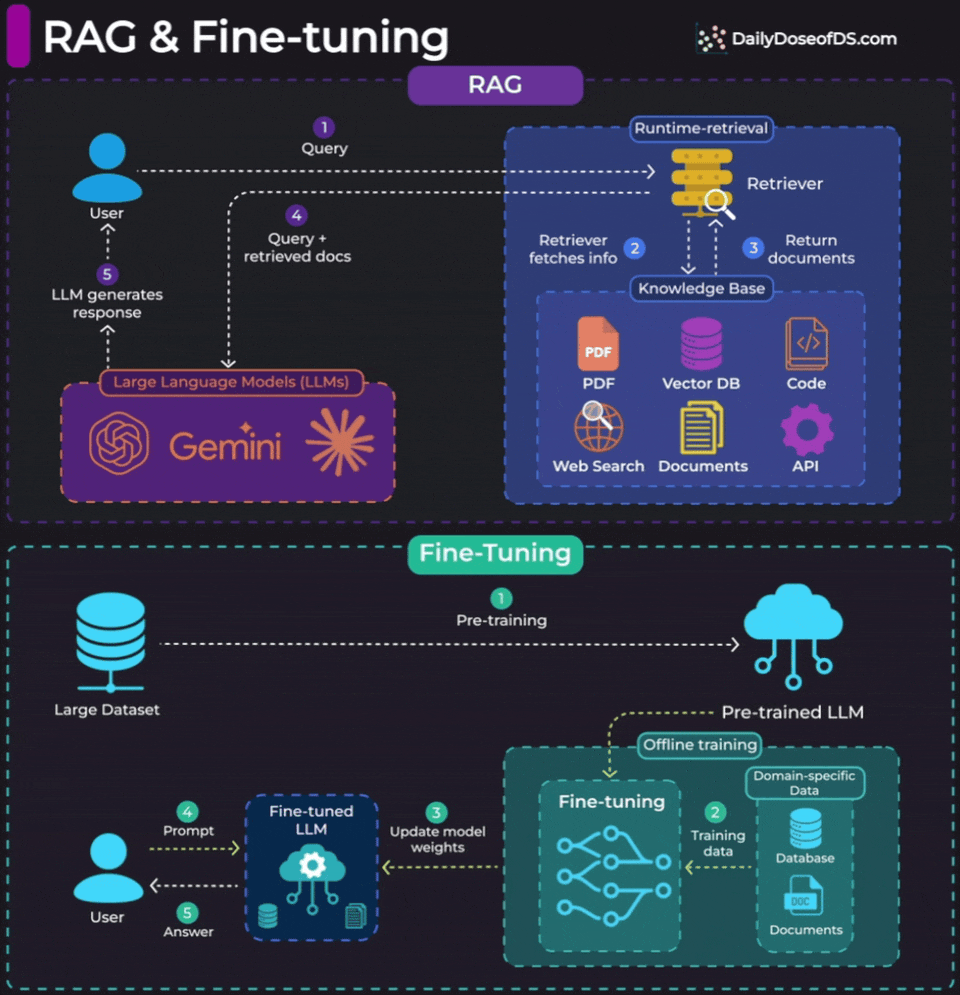
For RAG, look at the top half of the visual.
RAG operates at inference time. When a user sends a query, the retriever searches your knowledge base (PDFs, vector DBs, APIs, documents), pulls relevant context, and passes it to the LLM along with the query. The model weights never change. You’re giving the LLM a “cheat sheet” at runtime.
Fine-tuning is different. To understand, look at the bottom half of the visual.
It happens offline, before deployment. You train the model on domain-specific data, and the weights actually update. The model now behaves differently by default.
Fine-tuning is for changing how the model behaves. Its tone, vocabulary, response structure, or specialized reasoning patterns.
Two questions guide which one you need:
How much external knowledge does your task require?
How much behavioral adaptation do you need?
If you need the model to reference specific documents, product catalogs, or anything that updates frequently, that’s mostly a RAG territory.
If you need the model to adopt internal vocabulary, match a specific writing style, or follow domain-specific reasoning patterns, that’s mostly a fine-tuning territory.
For instance, an LLM might struggle to summarize company meeting transcripts because speakers use internal jargon the model has never seen. Fine-tuning fixes this.
That said, in production systems, you might often need both. A customer support bot might need to pull answers from documentation (RAG) while responding in your brand’s voice (fine-tuning).
The simple takeaway:
RAG → What should the model know?
Fine-tuning → How should the model behave
They’re not competing. They’re complementary layers in an LLM stack.
On a side note, we started a beginner-friendly crash course on RAGs recently with implementations, which covers:
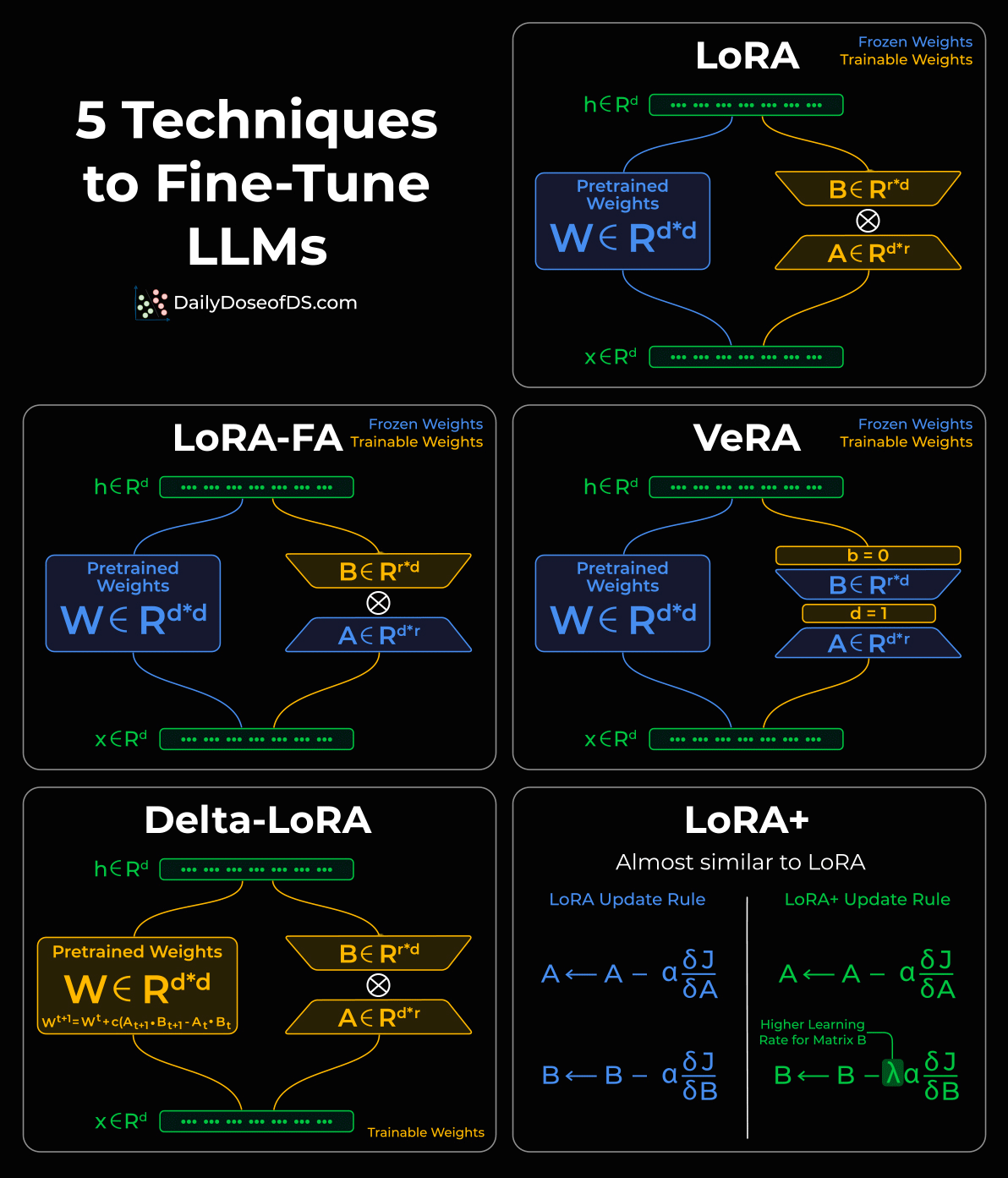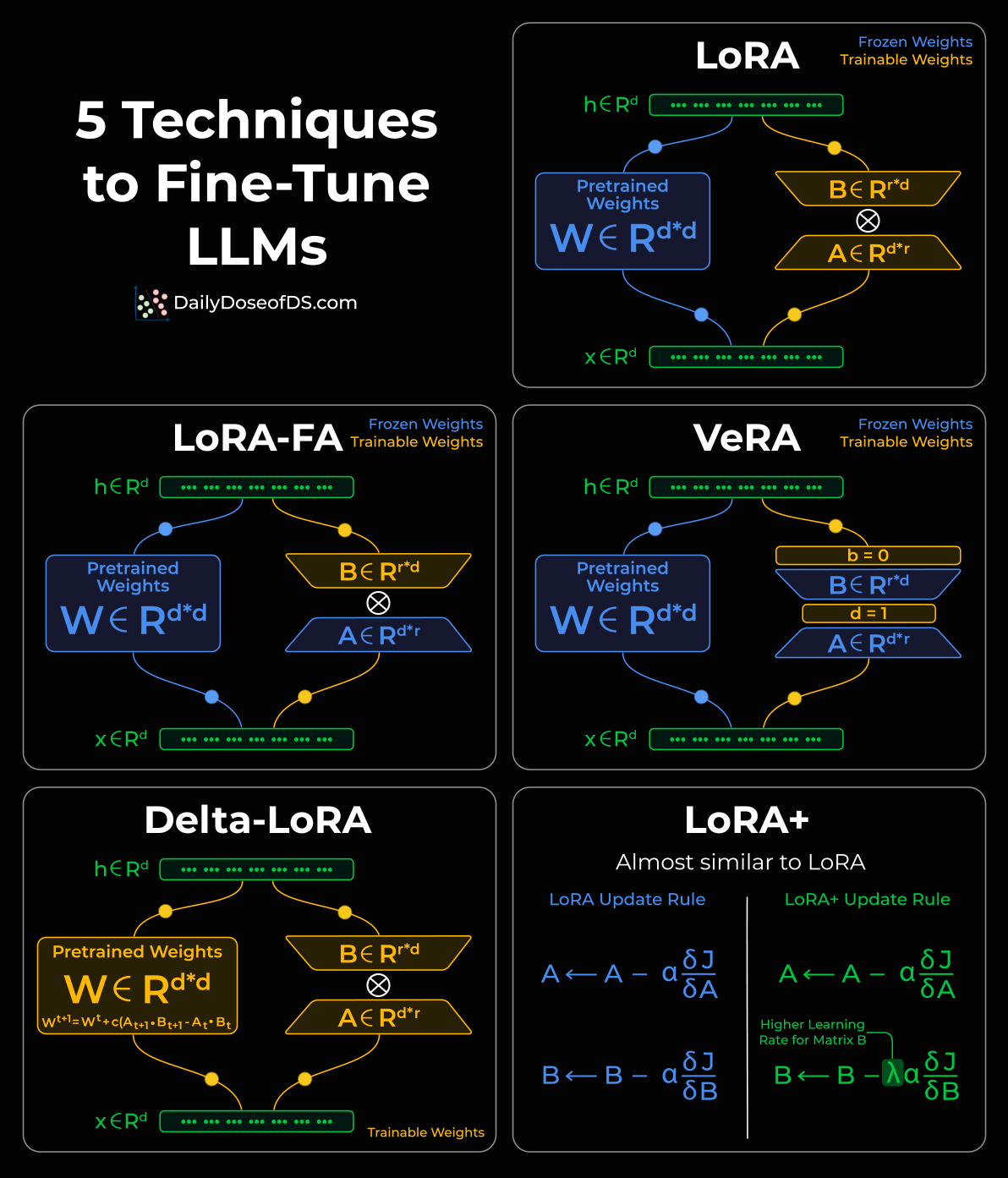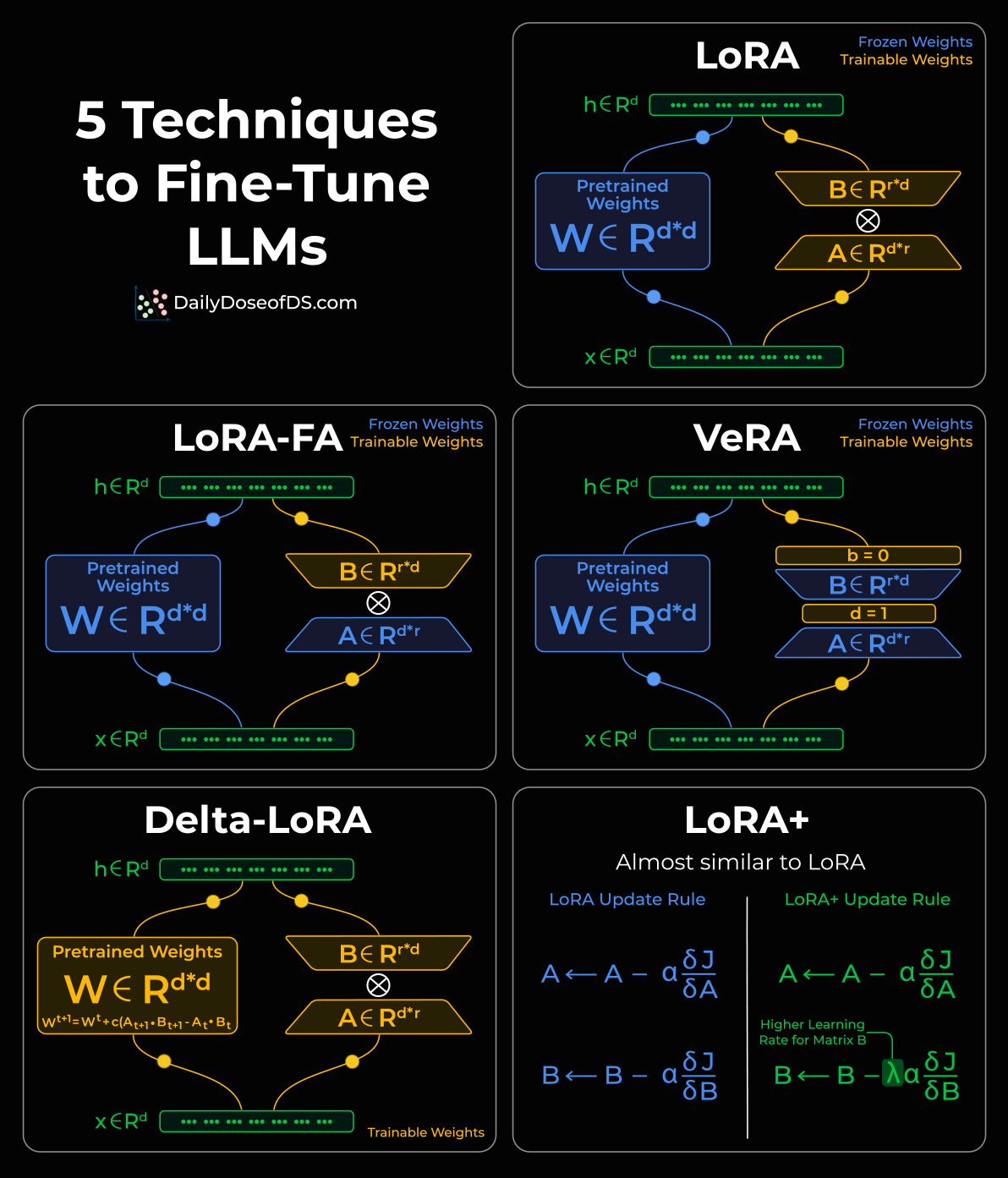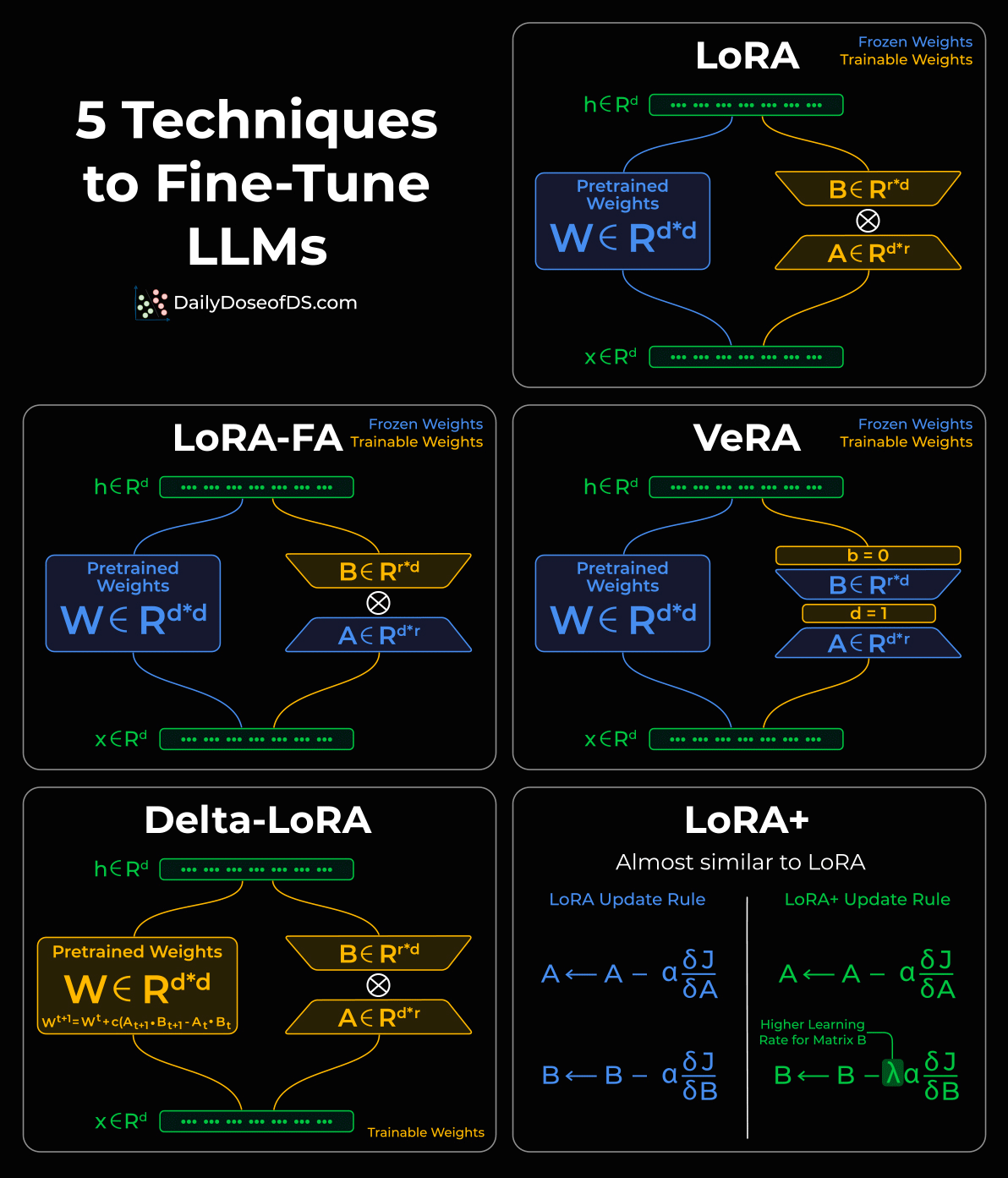
Also, we have covered several LLM fine-tuning with code techniques below:
Thanks for reading!