
RAG vs. Graph RAG vs. Agentic RAG
...explained visually!

Free hands-on virtual event on agentic AI at AWS Summit India Online

AWS Summit India Online is happening on June 3rd, and it’s completely free.
The part we like about this event is that it hosts hands-on virtual labs with Amazon Bedrock and agentic AI. These are not just talks about agents, but actual labs where participants can experiment with them to build AI systems in production.
Beyond the labs, there are 50+ sessions covering agentic AI, serverless computing, cloud modernization, and real-world case studies from companies across industries. Live Q&A with AWS solution architects and AWS Partners is available throughout the day.
The event runs from 10 AM to 4 PM IST, and on-demand replays stay accessible through July 3rd, so it’s easy to learn at your own pace from anywhere.
Thanks to AWS for partnering today!
RAG vs. Graph RAG vs. Agentic RAG
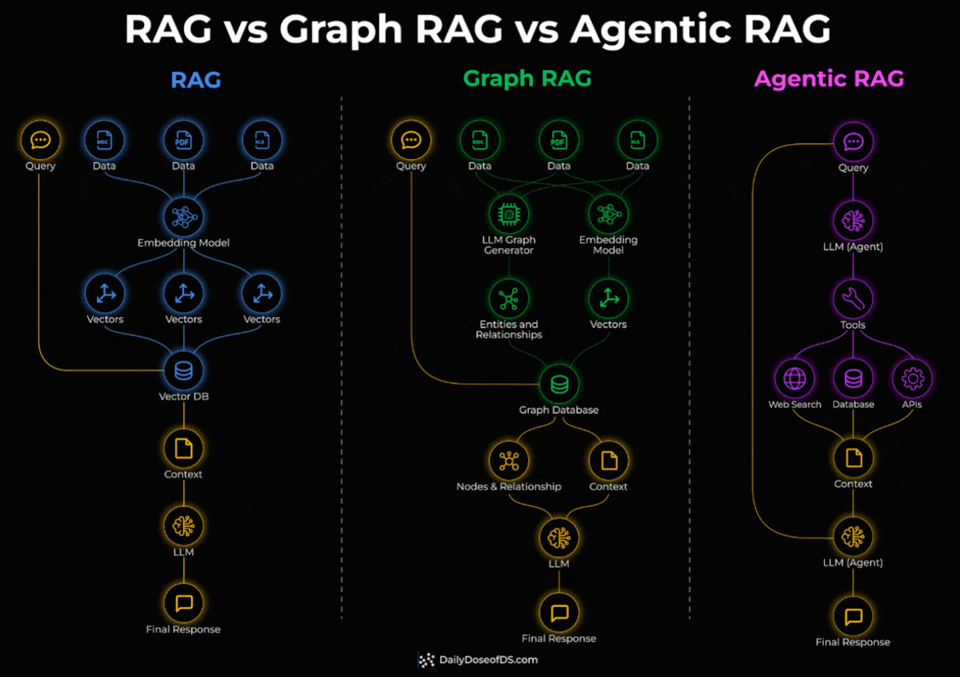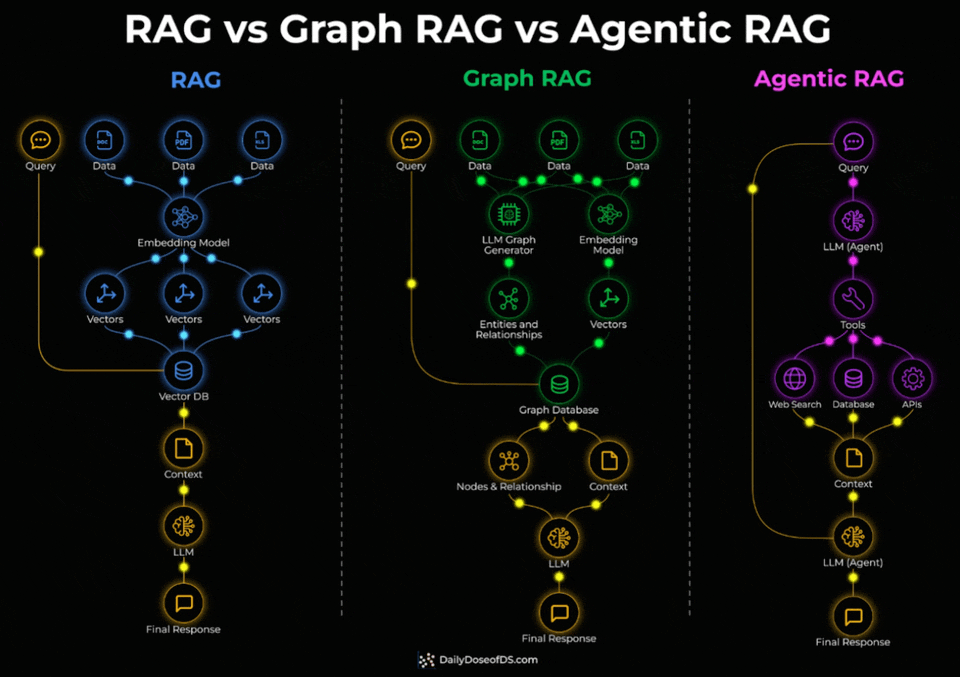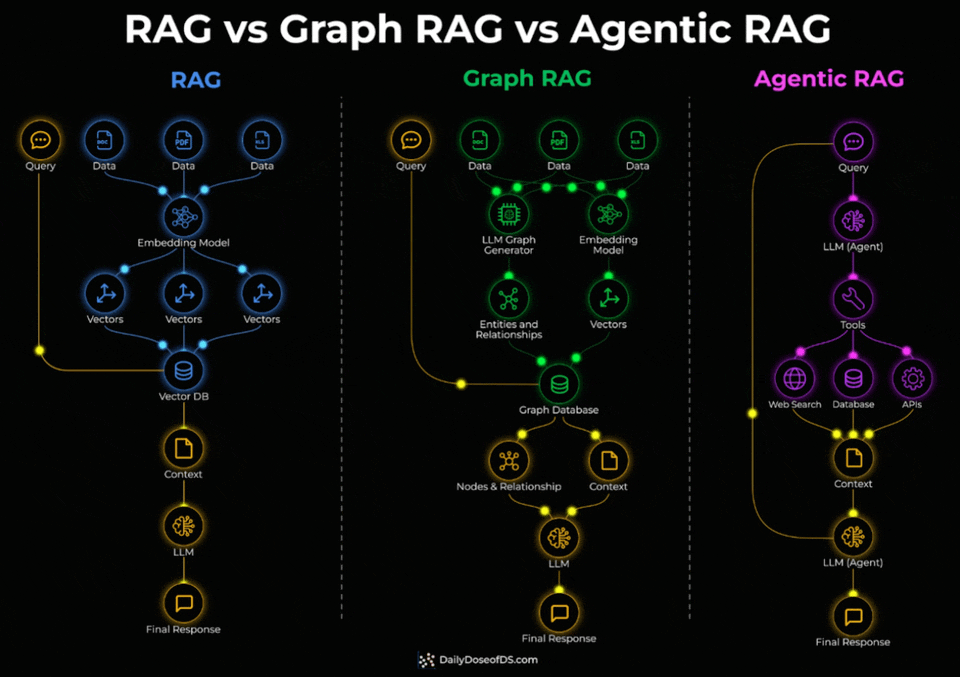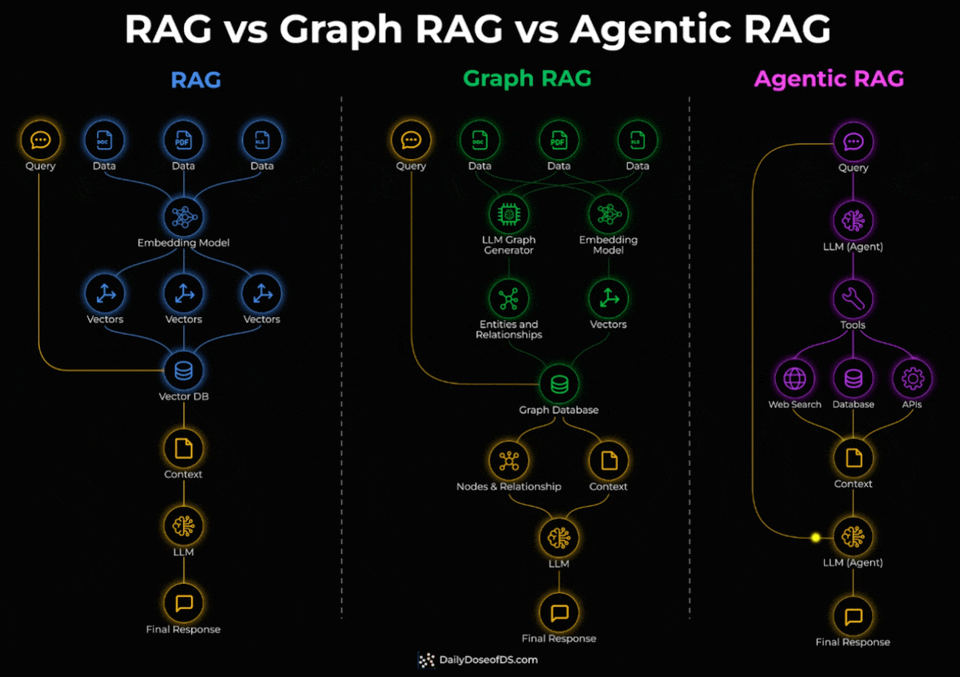
Standard RAG embeds documents into vectors and retrieves the most similar chunks via similarity search. For direct factual lookups, this works well.
But it breaks down when a query needs to connect facts spread across multiple documents. Similarity search retrieves individual chunks, not the relationships between them.
Graph RAG adds a knowledge graph layer on top.
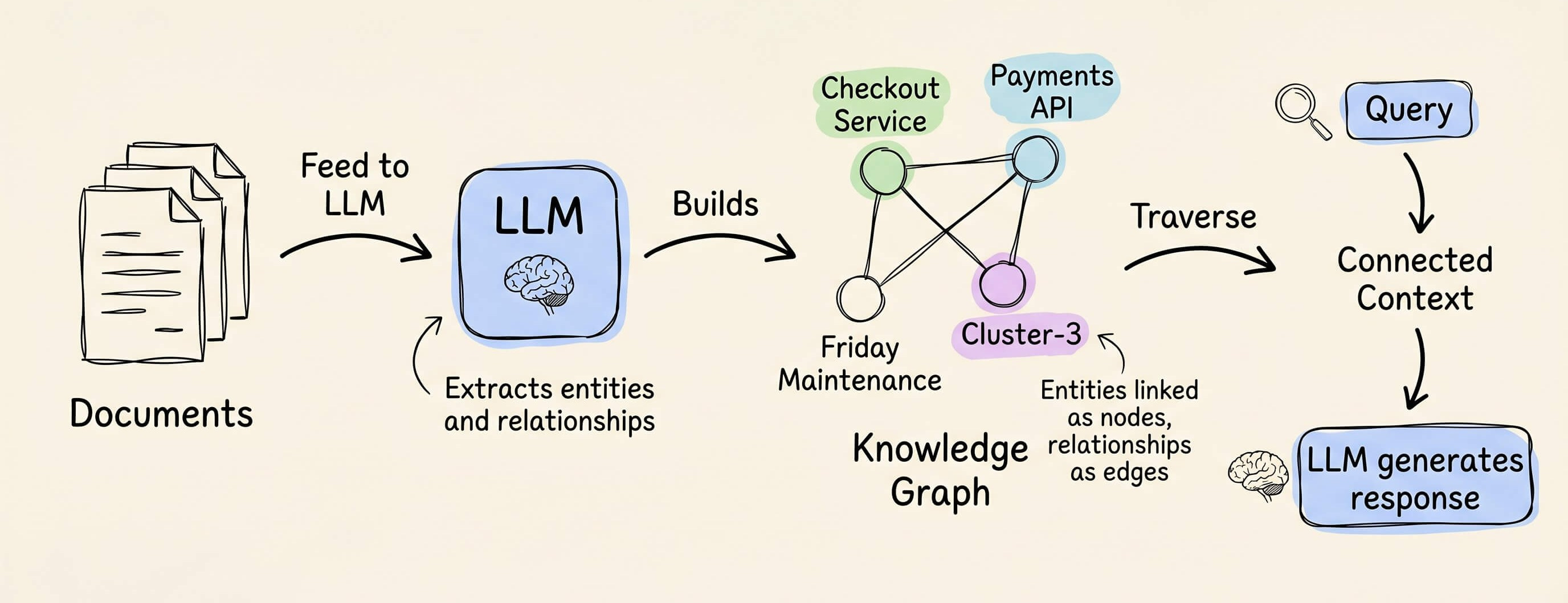
During indexing, an LLM extracts entities and relationships from the documents.
During retrieval, the system traverses these connections instead of relying on embedding similarity alone.
This is what enables multi-hop queries.
Say a vector DB stores three facts about internal services:
↳ “The checkout service uses payments API.”
↳ “The payments API runs on cluster-3.”
↳ “Cluster-3 is scheduled for maintenance on Friday.”
Someone asks: “Will the checkout service be affected by Friday’s maintenance?”
Vector search can likely retrieve facts 1 and 3 because the query mentions “checkout service” and “Friday maintenance.”
But it will miss fact 2, which connects the payments API to cluster-3.
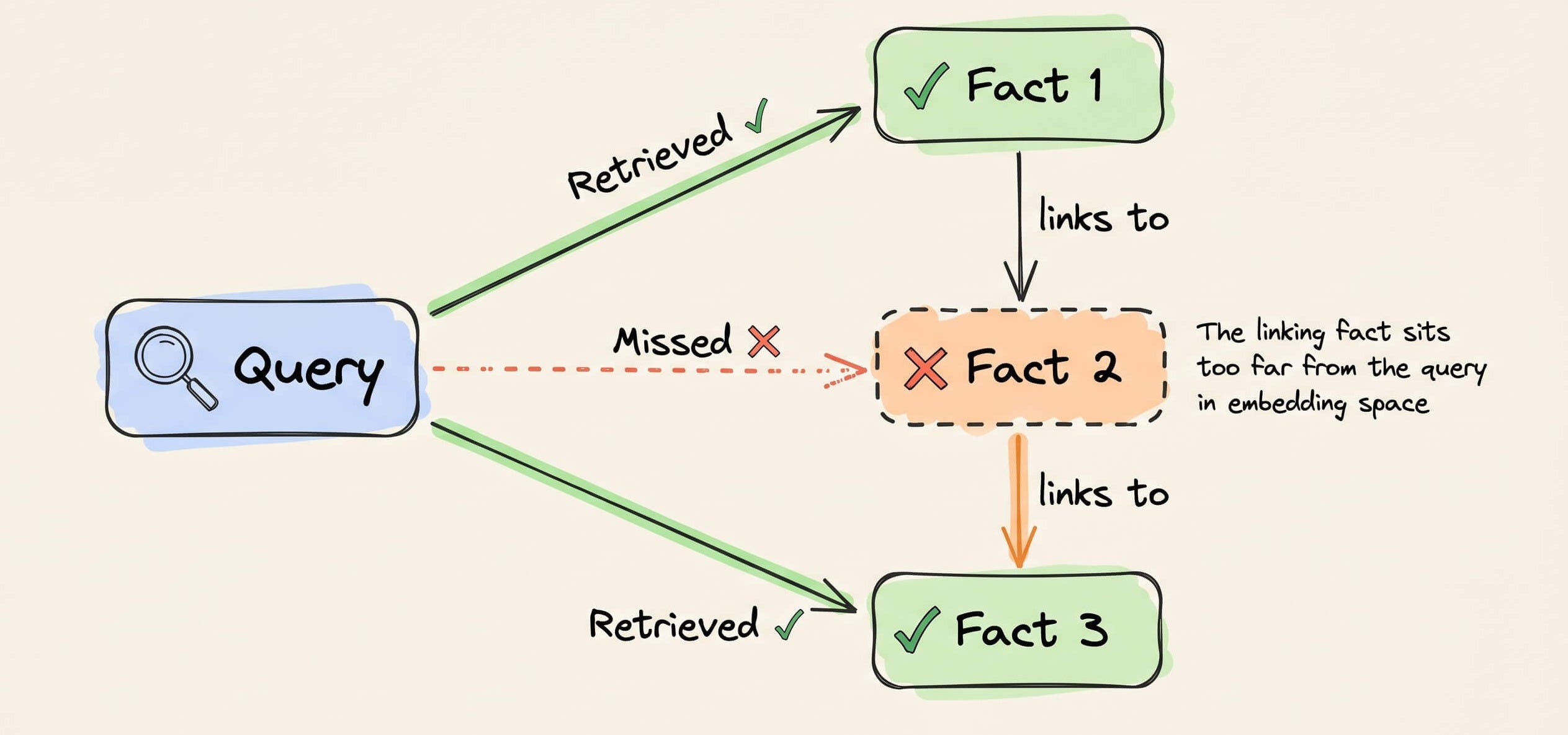
That middle fact sits too far from the query in embedding space. It mentions neither “checkout” nor “maintenance,” so it never makes it into the retrieved context.
A knowledge graph connects these as linked entities, and graph traversal finds the full path in one query.
Agentic RAG takes a different approach entirely.
Instead of a fixed retrieval pipeline, an LLM agent decides at query time which tools to invoke, which sources to query, and in what order.
Check the visual below again to understand the three architectures thoroughly.
One thing to note here is that these three aren’t levels of sophistication that you need to graduate through.
Instead, they solve different query types.
↳ Single-hop factual lookups → standard RAG
↳ Multi-hop relationship queries → Graph RAG
↳ Dynamic multi-source tasks with tool use → Agentic RAG
If you want to dive further, our full RAG crash course discusses RAG from basics to beyond:
👉 Over to you: Which RAG architecture are you running in production?
Thanks for reading!