
Random Forest vs. ExTra Trees
"ExTra" does not mean more.

Analyze audio sentiment in just 5 lines of code!
AssemblyAI’s audio intelligence transcribes audio and analyzes sentiment, turning speech into actionable insights.
Here’s how it works:

Provide an audio file URL.
Transcribe the audio using AssemblyAI's speech-to-text API while enabling sentiment analysis.
Display sentiment, confidence, and timestamps for each text segment.
Try it here and get 100+ hours of FREE transcription →
Thanks to AssemblyAI for partnering today!
Random Forest vs. ExTra Trees
Under default conditions, decision trees always overfit.
This is because a decision tree is allowed to grow until all leaves are pure.

As the model correctly classifies ALL training instances, this leads to 100% overfitting and poor generalization.
Random Forest addresses this by introducing randomness in two ways:
While creating a bootstrapped dataset.
While deciding a node’s split criteria by choosing candidate features randomly.
This aids the Bagging objective, whose mathematical foundations we covered in this detailed article: Why Bagging is So Ridiculously Effective at Variance Reduction?
That said, the ExTra Trees algorithm introduces another source of randomness.
Note: ExTra Trees does not mean more trees. Instead, it’s a short form for Extra Randomized.
Here’s how it works:
Create a bootstrapped dataset for each tree (same as RF).
Select candidate features randomly for node splitting (same as RF).
Now, Random Forest calculates the best split threshold for each candidate feature.
But ExtRa Trees chooses this split threshold randomly.
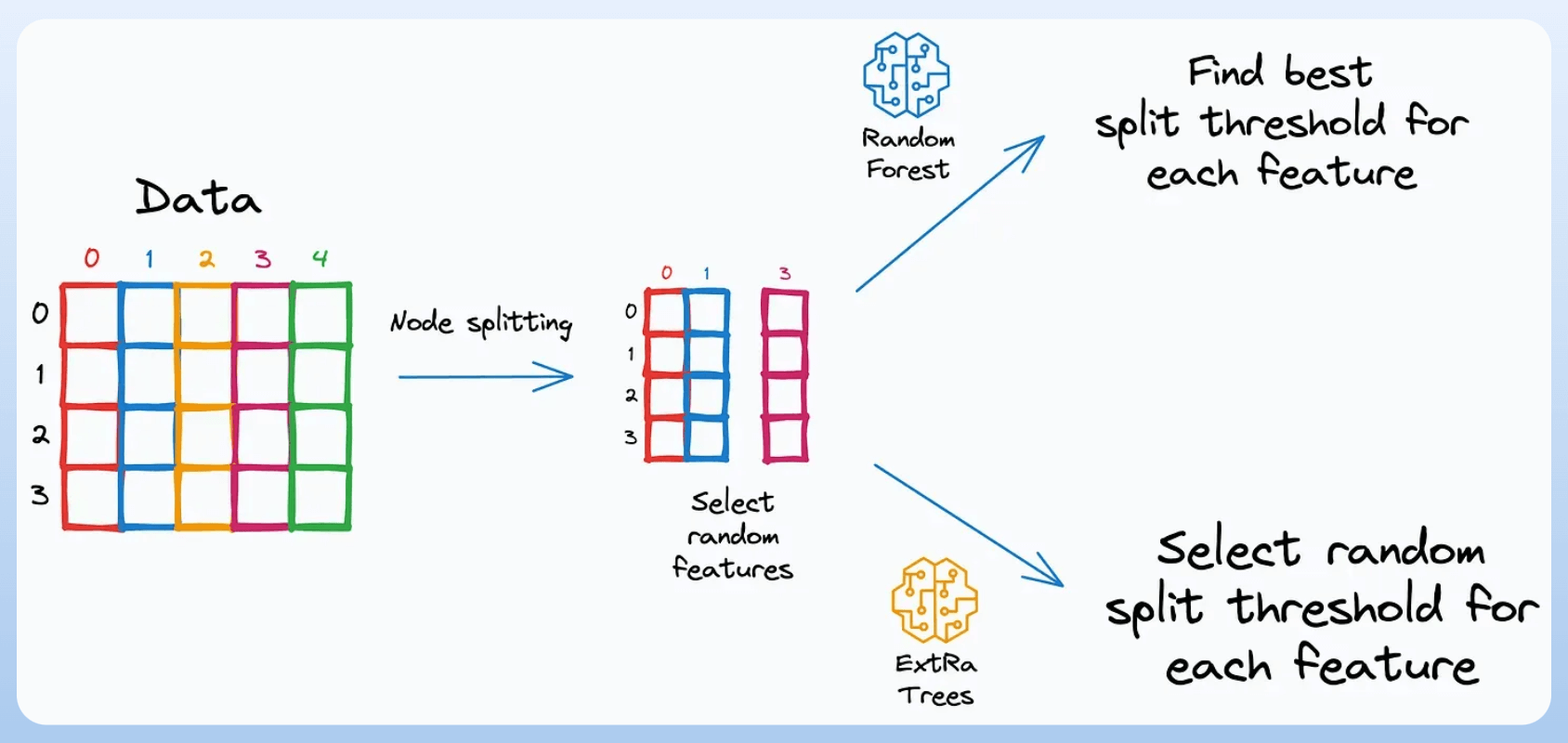
This is the source of extra randomness.
After that, the best candidate feature is selected. This further reduces the variance of the model.
The table below compares decision tree, random forest, and ExTra trees on a dummy dataset:

Decision Trees entirely overfit.
Random Forests work better.
ExTra Trees performs marginally better.
If you want to get into the mathematical foundations of Bagging, which will also help you build your own Bagging models, we covered it here: Why Bagging is So Ridiculously Effective at Variance Reduction?
Also, we implemented the entire XGBoost algorithm from scratch here →
👉 Over to you: Can you think of another way to add randomness to Random Forest?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn how to build Agentic systems in an ongoing crash course with 13 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.