
RBF Kernel Mathematically Explained
...and why it so powerful.

Langwatch—Observe, Evaluate, and Optimize LLM apps [Open-source]

Andrew Ng said “Our current eval tools fall short for LLMs.”
LangWatch just solved this with its Evaluations Wizard. It lets you simulate real-world user interactions and run 30+ evaluators—even if you have no eval dataset!
100% open-source.
GitHub repo (don’t forget to star the repo) →
Thanks to the LangWatch team for partnering today!
The math behind the RBF kernel
A couple of days back, we understood kernels and why the kernel trick is called a “trick.”
To recap, a kernel function lets us compute dot products of two vectors in a high-dimensional space without transforming the vectors to that space.

We looked at the polynomial kernel and saw that it computes the dot product of a 2-dimensional vector in a 6-dimensional space without explicitly visiting that space.

Today, let’s discuss the RBF kernel (another powerful kernel), which is also the default kernel in sklearn implementation of SVMs:

To begin, the mathematical expression of the RBF kernel is depicted below (and consider that we have just a 1-dimensional feature vector):

The exponential function is defined as follows:
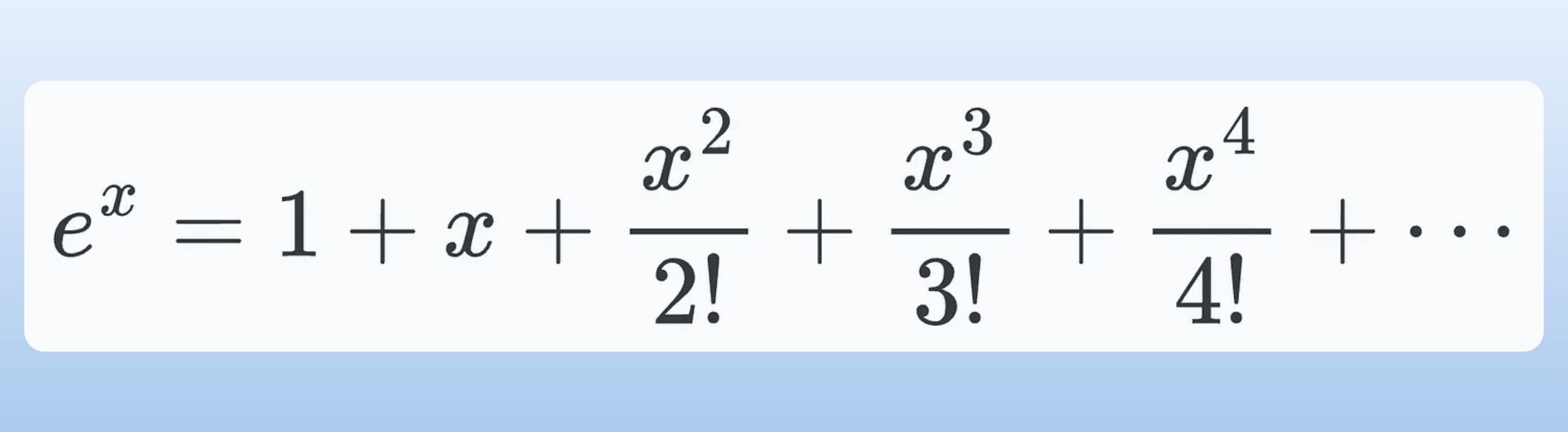
Expanding the square term in the RBF kernel expression, we get:

Distributing the gamma term and expanding the exponent term, we get:

Next, we apply the exponential expansion to the last term and get the following:
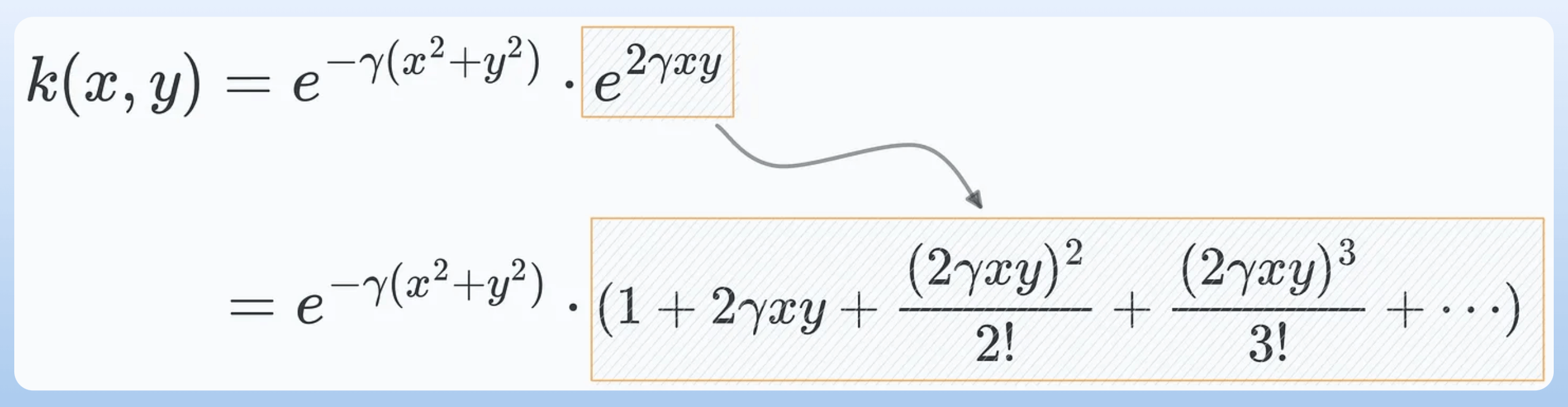
Almost done.
Notice closely that the exponential expansion above can be rewritten as the dot product between the following two vectors:

And there you go.
We get our projection function:

This shows that the RBF kernel function we chose earlier computes the dot product in an infinite-dimensional space without explicitly visiting that space.
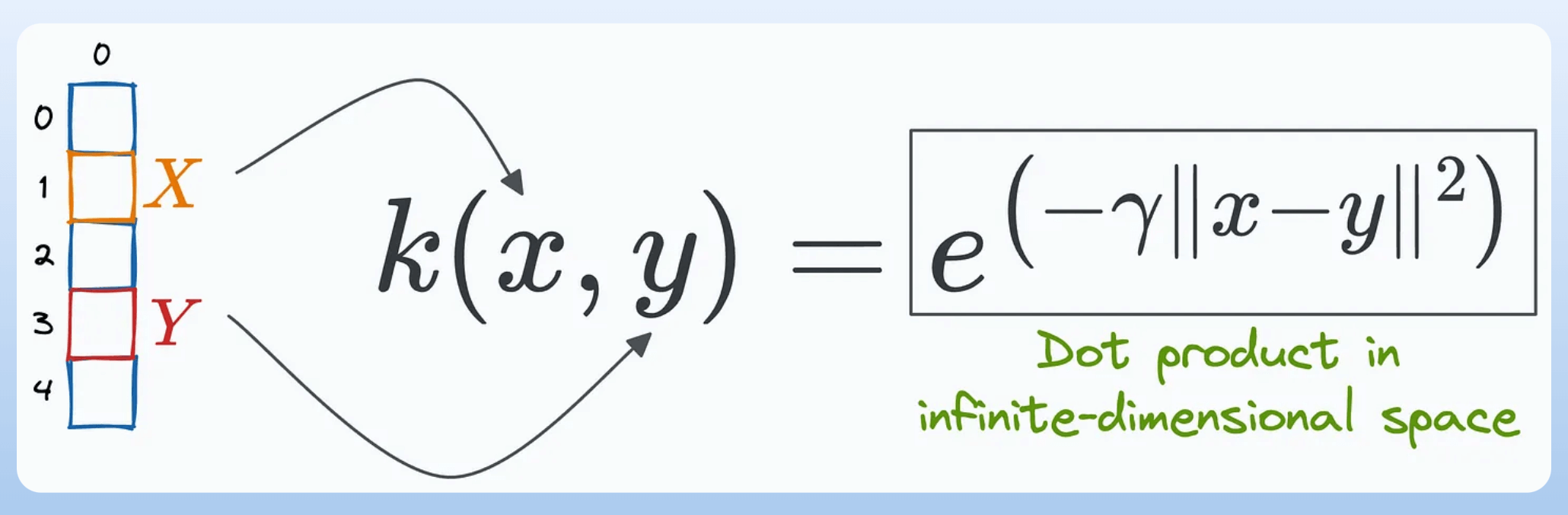
This is why the RBF kernel is considered so powerful, allowing it to easily model highly complex decision boundaries.
Here, note that while the kernel is equivalent to the dot product between two infinite-dimensional vectors, we NEVER compute that dot product, so the computation complexity is never compromised.
That is why the kernel trick is called a “trick.” In other words, it allows us to operate in high-dimensional spaces without explicitly computing the coordinates of the data in that space.
If you feel intimidated by mathematics but want to get going, we covered the mathematical foundations in an intuitive and beginner-friendly way of many core ML techniques/concepts here:
Why Bagging is So Ridiculously Effective At Variance Reduction?
Formulating and Implementing the t-SNE Algorithm From Scratch.
Why Sklearn’s Logistic Regression Has No Learning Rate Hyperparameter?
You Are Probably Building Inconsistent Classification Models Without Even Realizing
👉 Over to you: Can you tell a major pain point of the kernel trick algorithms?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn how to build Agentic systems in an ongoing crash course with 11 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.