
Recursive Language Models
...explained visually.

The context problem with MCP tools

MCP tools have hardcoded descriptions that can’t adapt to different users or contexts.
Dynamic FastMCP is a Python framework that extends the official MCP SDK with context-aware tools.
Using this, MCP Tool descriptions and behaviors can adapt dynamically based on user identity, tenant info, and request parameters.
The framework integrates seamlessly with FastAPI, supports authentication out of the box, and works alongside your existing static tools.
Recursive Language Models
LLMs typically become less effective as conversations become longer.
Even if the context fits within the model’s window, performance drops. The model loses its ability to recall and reason over information.
This is called “context rot.”
Researchers from MIT just proposed a fix called Recursive Language Models (RLMs), and it is explained in the visual below:
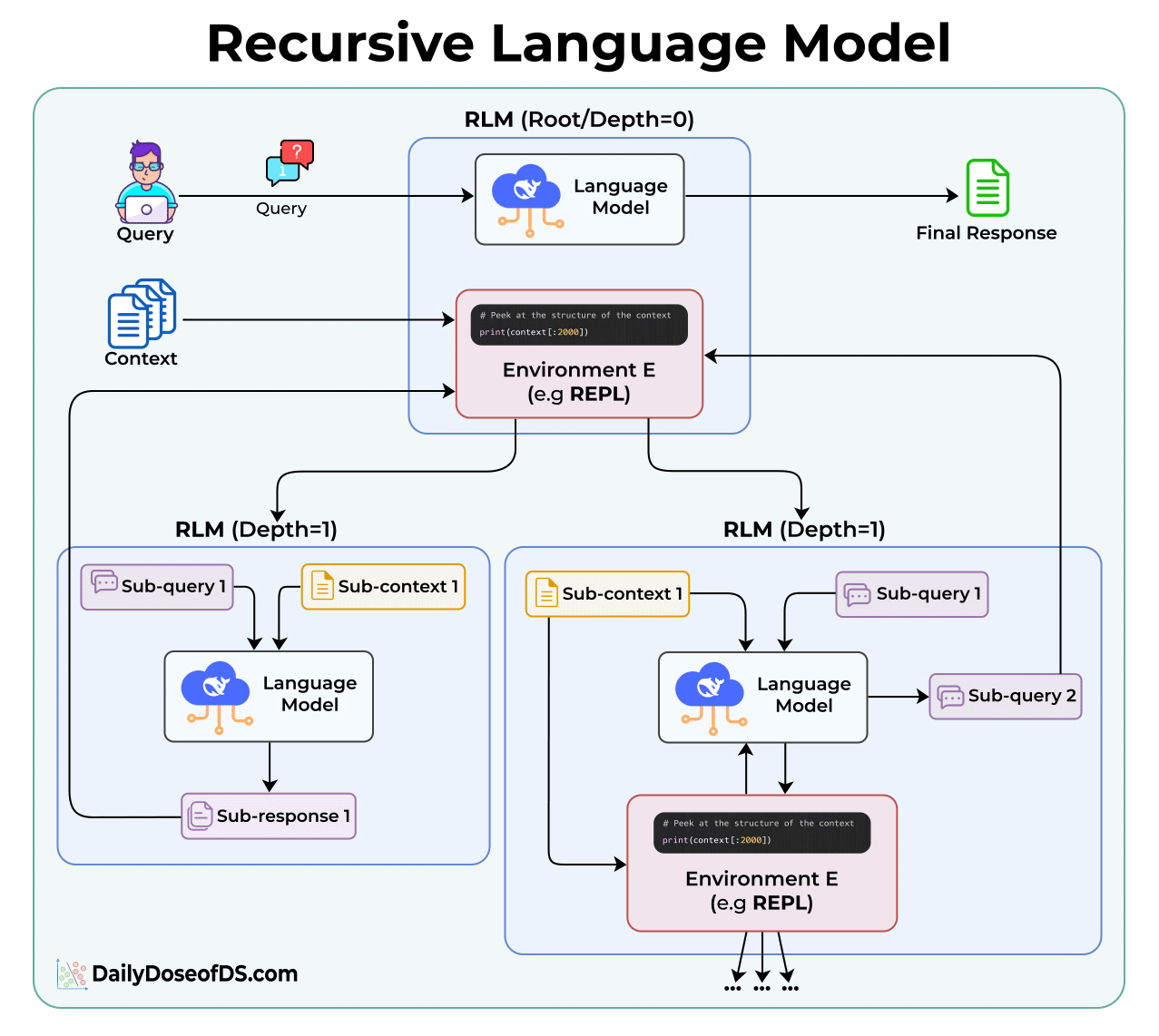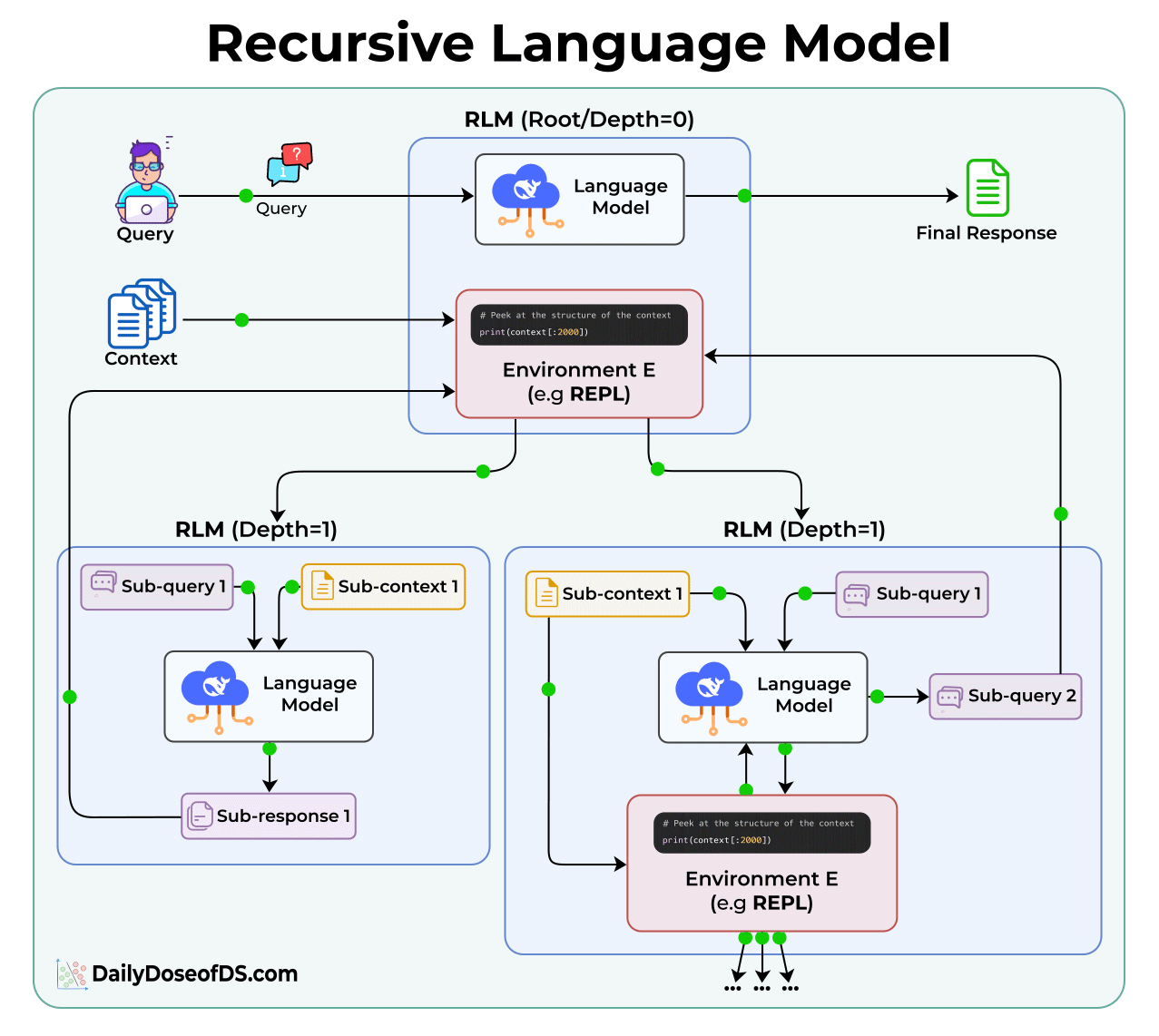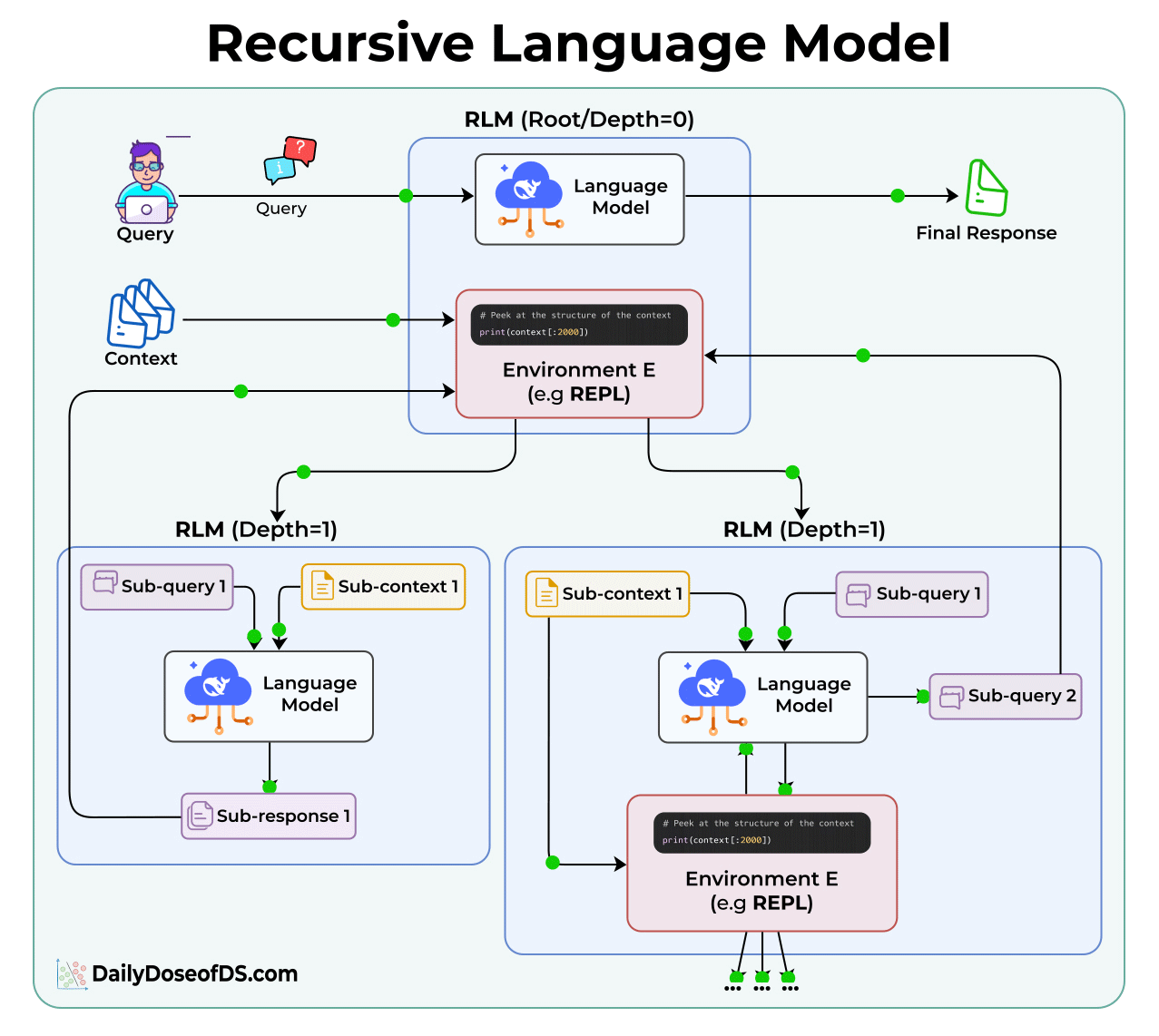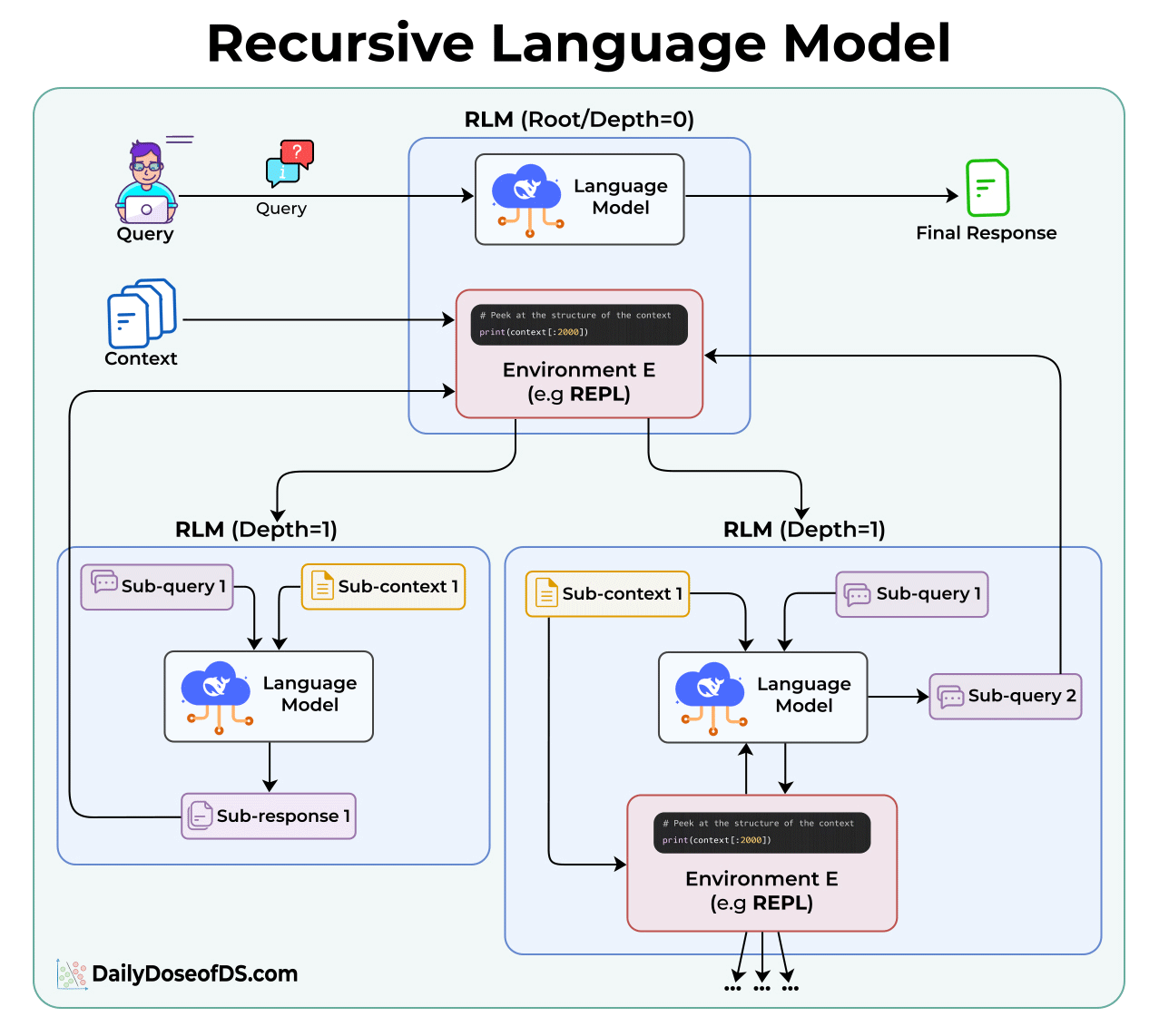
Here’s how they work:
In a normal LLM call, you send the query and the full context together. The model processes everything at once.
In an RLM, the context is stored separately as a variable in a Python REPL environment. The model never sees all of it directly.
Instead, it gets access to tools that let it:
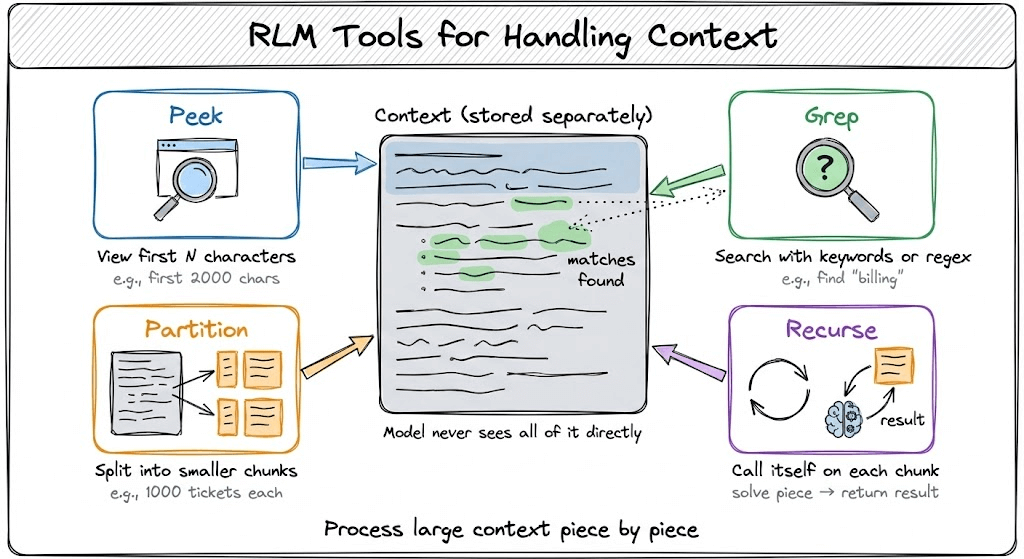
Peek at portions of the context (like the first 2000 characters)
Grep through it using regex or keywords
Partition it into smaller chunks
Call itself recursively on those chunks
Each recursive call is like a function call in programming. It gets a smaller piece of the problem, solves it, and returns the result to the parent.
Here’s a concrete example:
You have 5,000 customer support tickets. Each has a User ID and a question. You ask: “Among users 12345, 67890, and 11111, how many questions are about billing?”
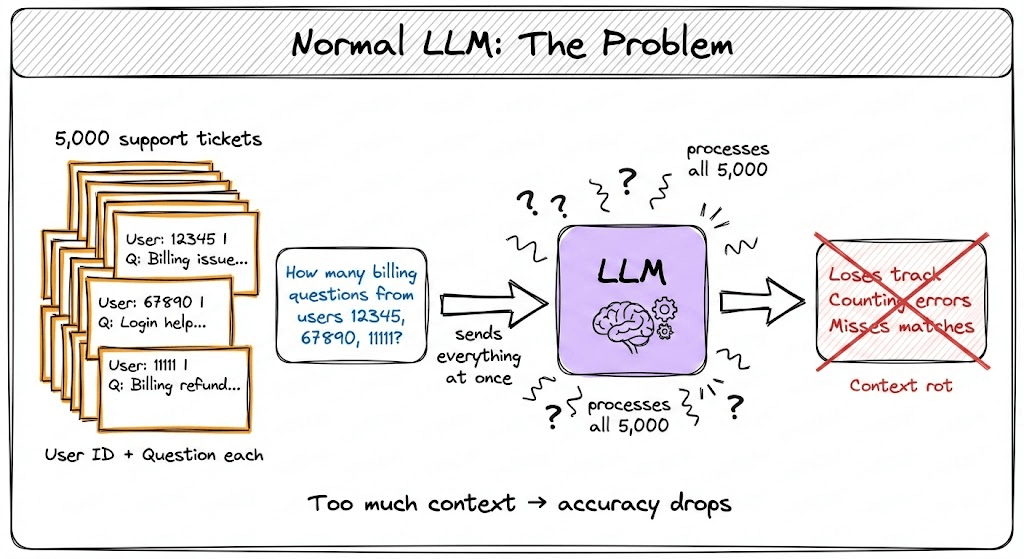
A normal LLM receives all 5,000 tickets, tries to scan through everything, gets overwhelmed, and makes counting errors.
Here’s what an RLM does:
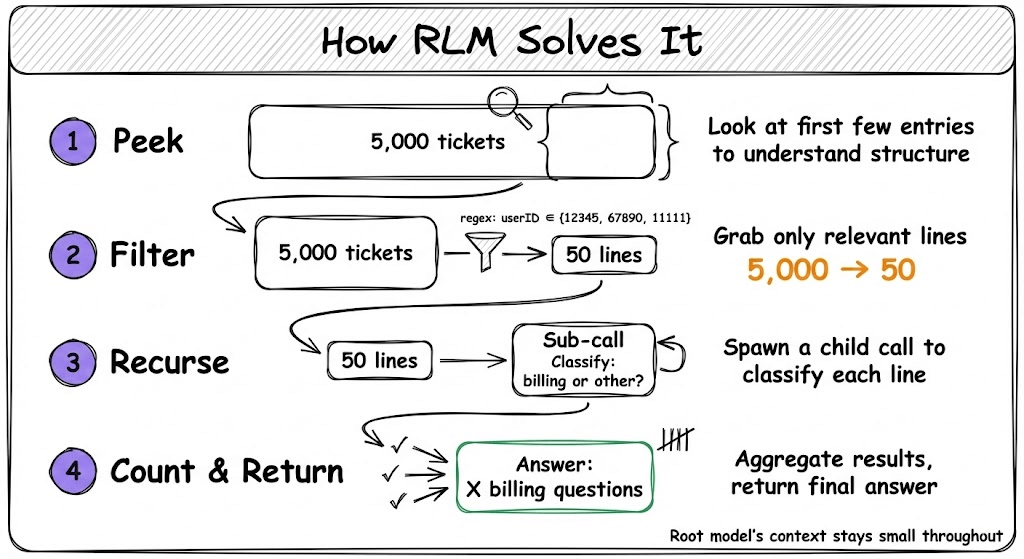
Step 1: It peeks at the first few entries to understand the structure.
Step 2: It runs a regex filter to grab only lines with the target user IDs. Now it has 50 lines instead of 5,000.
Step 3: It spawns a recursive sub-call: “Classify each of these as billing or other.”
Step 4: It counts the billing ones and returns the final answer.
The root model’s context window stays small throughout. It only sees its query, its code, and the results from sub-calls.
The results are incredible.
RLM with GPT-5-mini outperformed GPT-5 on challenging long-context benchmarks. More than double the correct answers on some tasks. And cheaper per query.
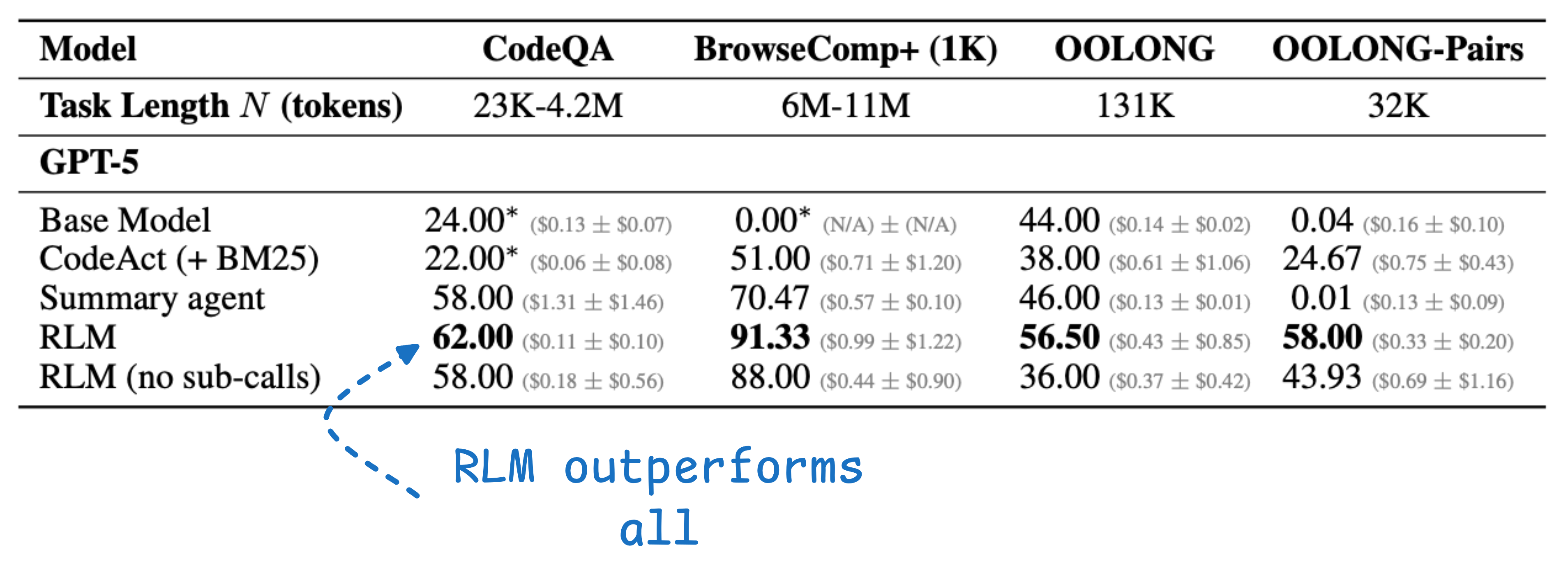
At 10M+ tokens, RLMs didn’t degrade. Regular LLM calls fall apart way before that.
Traditional LLMs treat context as a black box to process all at once. RLMs treat context as data to be programmatically explored. The model decides how to decompose the problem on its own.
Interestingly, this approach also mirrors how agentic coding tools like Claude Code already operate.
They peek at file structures, grep through codebases, and only pull relevant snippets into context rather than loading entire repositories at once.
If you want to learn more about Sub-agents in Claude Code, we did a hands-on walkthrough recently. You can learn more in the video below:
You can find the RLM Paper here →
The GitHub repo is available here →
Thanks for reading!