
Gradient Checkpointing: Reduce Memory Usage by At least 50-60% When Training a Neural Network
An underrated technique to train larger ML models.

Neural networks primarily utilize memory in two ways:

When they store model weights (this is fixed memory utilization).
When they are trained (this is dynamic). It happens in two ways:
During forward pass while computing and storing activations of all layers.
During backward pass while computing gradients at each layer.
The latter, i.e., dynamic memory utilization, often restricts us from training larger models with bigger batch sizes.

This is because memory utilization scales proportionately with the batch size.
That said, there’s a pretty incredible technique that lets us increase the batch size while maintaining the overall memory utilization.
It is called Gradient checkpointing, and in my experience, it’s a highly underrated technique to reduce the memory overheads of neural networks.
Let’s understand this in more detail.
How gradient checkpointing works?
Gradient checkpointing is based on two key observations on how neural networks typically work:
The activations of a specific layer can be solely computed using the activations of the previous layer. For instance, in the image below, “Layer B” activations can be computed from “Layer A” activations only:

Updating the weights of a layer only depends on two things:
The activations of that layer.
The gradients computed in the next (right) layer (or rather, the running gradients).

Gradient checkpointing exploits these two observations to optimize memory utilization.
Here’s how it works:
Step 1) Divide the network into segments before the forward pass:
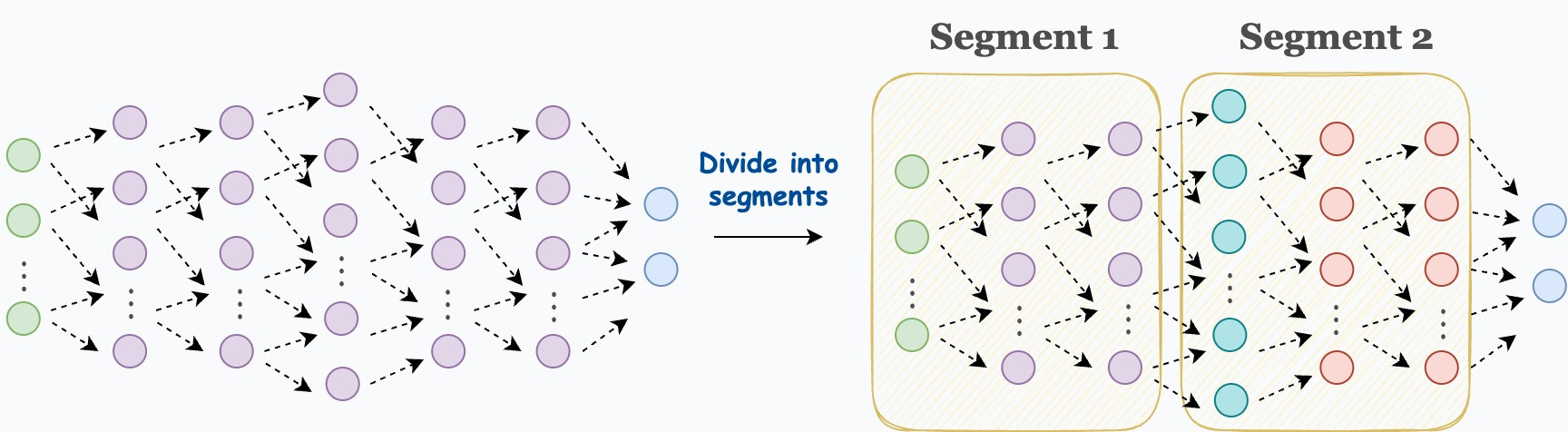
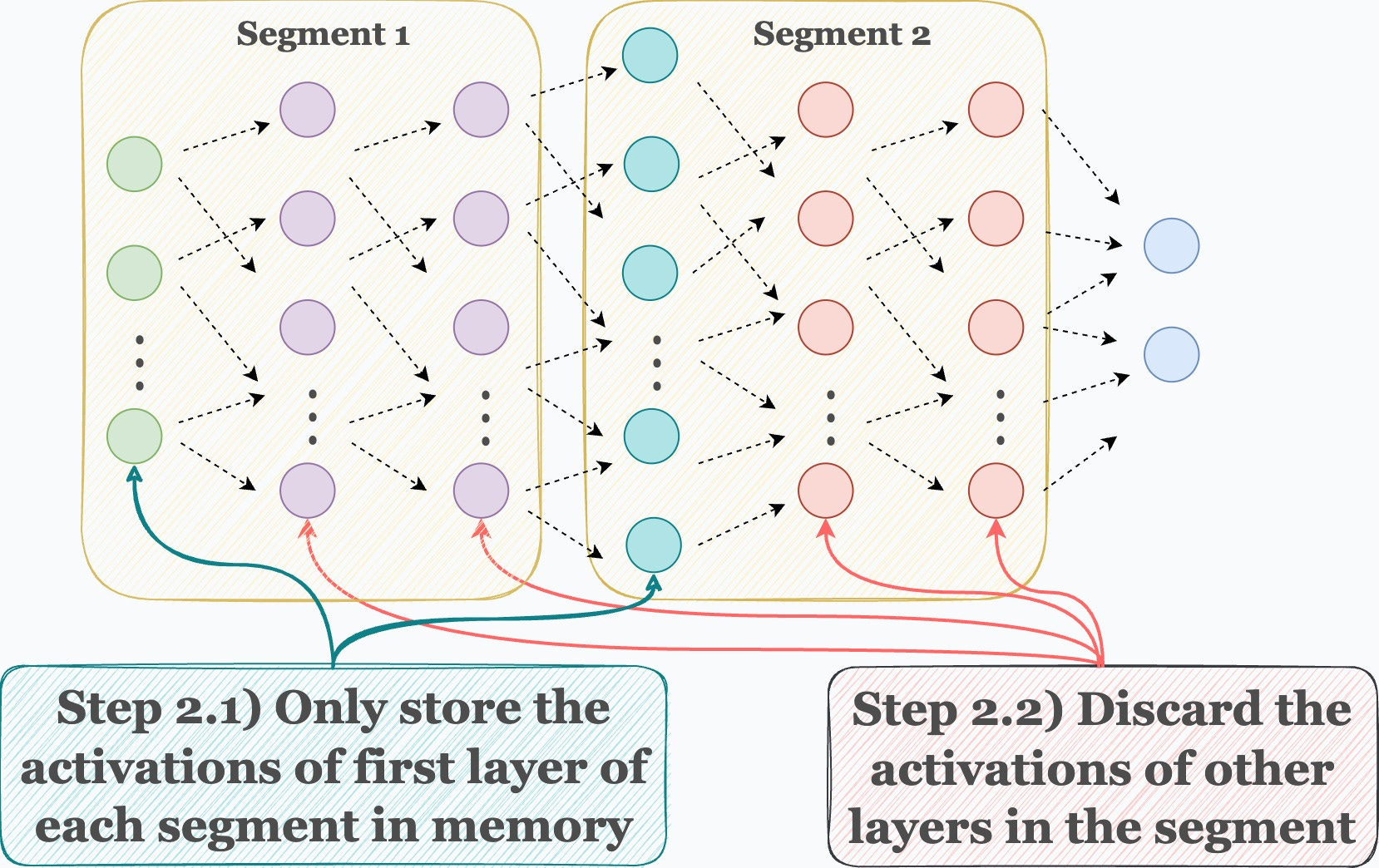
Step 2) During the forward pass, only store the activations of the first layer in each segment. Discard the rest when they have been used to compute the activations of the next layer.
Step 3) Now comes backpropagation. To update the weights of a layer, we need its activations. Thus, we recompute those activations using the first layer in that segment.
For instance, as shown in the image below, to update the weights of the red layers, we recompute their activations using the activations of the cyan layer, which are already available in memory.
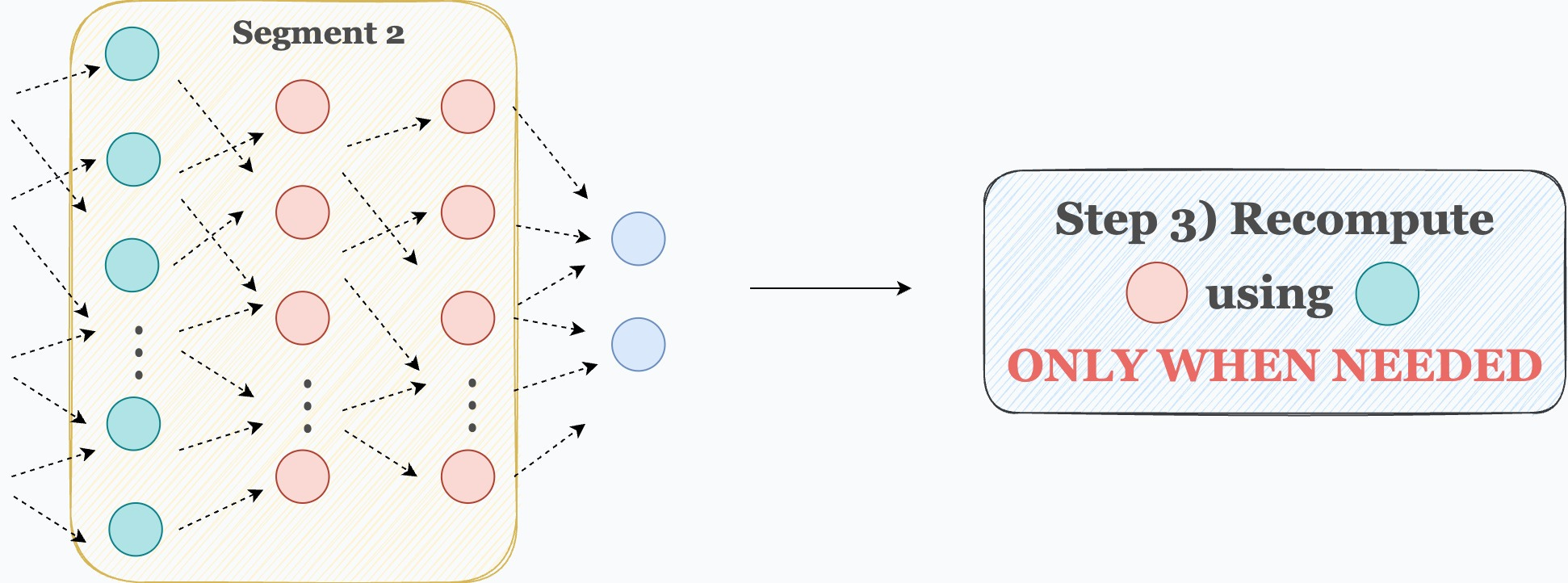
Done!
This is how gradient checkpointing works.
To summarize, the idea is that we don’t need to store all the intermediate activations in memory.
Instead, storing a few of them and recomputing the rest only when they are needed can significantly reduce the memory requirement.
The whole idea makes intuitive sense as well.
In fact, this also allows us to train the network on larger batches of data.
Typically, my observation has been that gradient checkpointing (GCP) can reduce memory usage by at least 50-60%, which is massive.

Of course, as we compute some activations twice, this does come at the cost of increased run-time, which can typically range between 15-25%.
So there’s always a tradeoff between memory and run-time.

That said, another advantage is that it allows us to use a larger batch size, which can slightly (not entirely though) counter the increased run-time.
Nonetheless, gradient checkpointing is an extremely powerful technique to train larger models, which I have found to be pretty helpful at times, without resorting to more intensive techniques like distributed training, for instance.
Thankfully, gradient checkpointing is also implemented by many open-source deep learning frameworks like Pytorch, etc.
Gradient checkpointing in PyTorch
To utilize this, we begin by importing the necessary libraries and functions:

Next, we define our neural network:

As demonstrated above, in the forward method, we use the checkpoint_sequential method to use gradient checkpointing and divide the network into two segments.
Next, we can proceed with network training as we usually would.
Pretty simple, isn’t it?
👉 Over to you: What are some ways you use to optimize a neural network’s training?
👉 If you liked this post, don’t forget to leave a like ❤️. It helps more people discover this newsletter on Substack and tells me that you appreciate reading these daily insights.

The button is located towards the bottom of this email.
Thanks for reading!
Latest full articles
If you’re not a full subscriber, here’s what you missed last month:
How To (Immensely) Optimize Your Machine Learning Development and Operations with MLflow.
Don’t Stop at Pandas and Sklearn! Get Started with Spark DataFrames and Big Data ML using PySpark.
DBSCAN++: The Faster and Scalable Alternative to DBSCAN Clustering.
Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
You Cannot Build Large Data Projects Until You Learn Data Version Control!
Deploy, Version Control, and Manage ML Models Right From Your Jupyter Notebook with Modelbit.
To receive all full articles and support the Daily Dose of Data Science, consider subscribing:
👉 Tell the world what makes this newsletter special for you by leaving a review here :)
👉 If you love reading this newsletter, feel free to share it with friends!
Very interesting. Running into memory issues is very common for me. Shall try this and see if it helps. Thanks a lot.
Great article. Please discuss techniques for reducing GPU requirements especially while implementing Transformers.