
Regular ML Inference vs. LLM Inference
5 key differences that AI engineers should know!

Firecrawl v2.5 is the world’s best Web Data API!
Firecrawl now has the highest quality and most comprehensive Web Data API, powered by a new Semantic Index and custom browser stack.
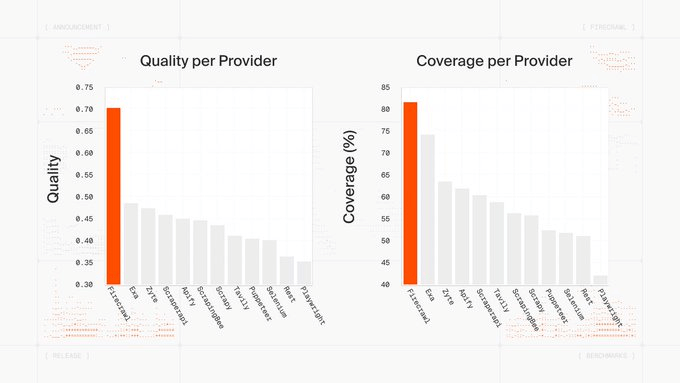
It automatically detects how each page is rendered, allowing you to extract data at high speeds while maintaining the same quality bar.
Start using the best Web Data API here →
Thanks to Firecrawl for partnering today!
Regular ML Inference vs. LLM Inference
LLM Inference presents unique challenges over regular ML inference, due to which we have specialized, high-performance LLM inference engines, like vLLM, LMCache, SGLang, and TensorRT LLM.
Let’s understand these challenges today and how we solve them!
Continuous batching
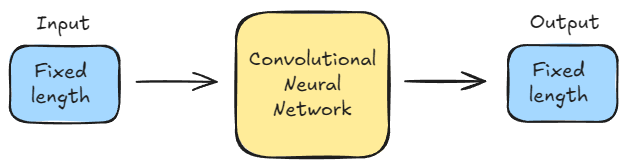
Traditional models, like CNNs, have a fixed-size image input and a fixed-length output (like a label). This makes batching easy.
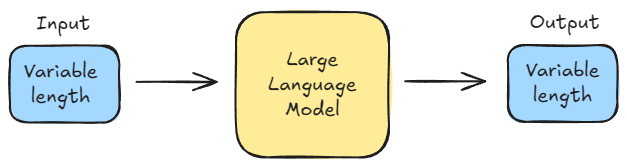
LLMs, however, deal with variable-length inputs (the prompt) and generate variable-length outputs.
So if you batch some requests, all will finish at different times, and the GPU would have to wait for the longest request to finish before it can process new requests. This leads to idle time on the GPU:
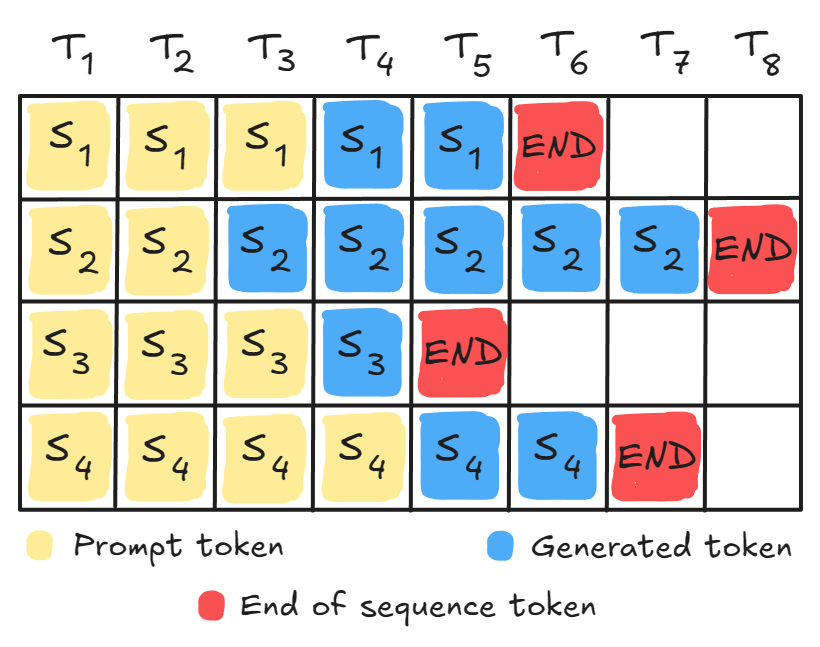
Continuous Batching solves this.
Instead of waiting for the entire batch to finish, the system monitors all sequences and swaps completed ones (<EOS> token) with new queries:
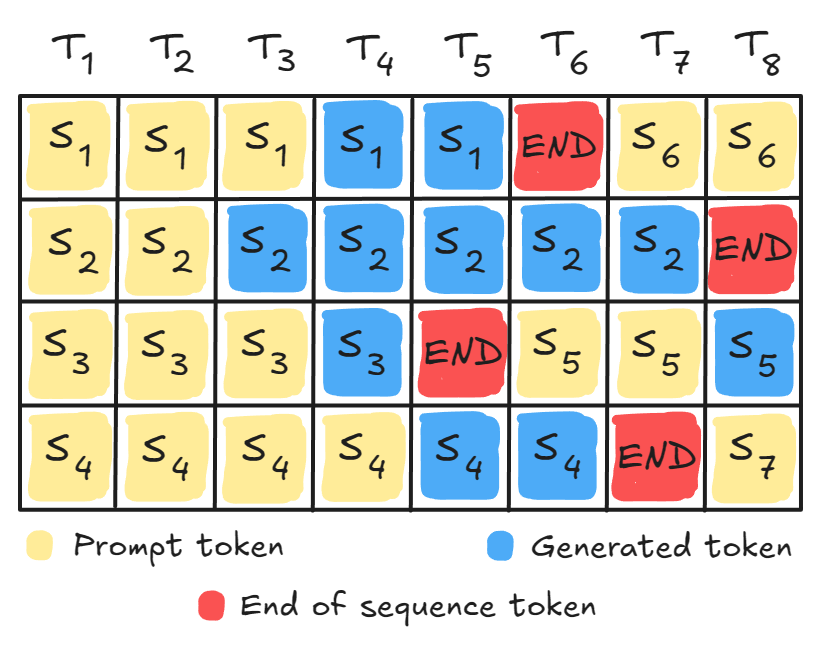
This keeps the GPU pipeline full and maximizes utilization.
Prefill-decode disaggregation
LLM inference is a two-stage process with fundamentally different resource requirements.
The prefill stage processes all the input prompt tokens at once, so this is compute-heavy.
The decode stage autoregressively generates the output, and this demands low latency.

Running both stages on the GPU means the compute-heavy prefill requests will interfere with the latency-sensitive decode requests.
Prefill-decode disaggregation solves this by allocating a dedicated pool of GPUs for the prefill stage and another pool for the decode stage.
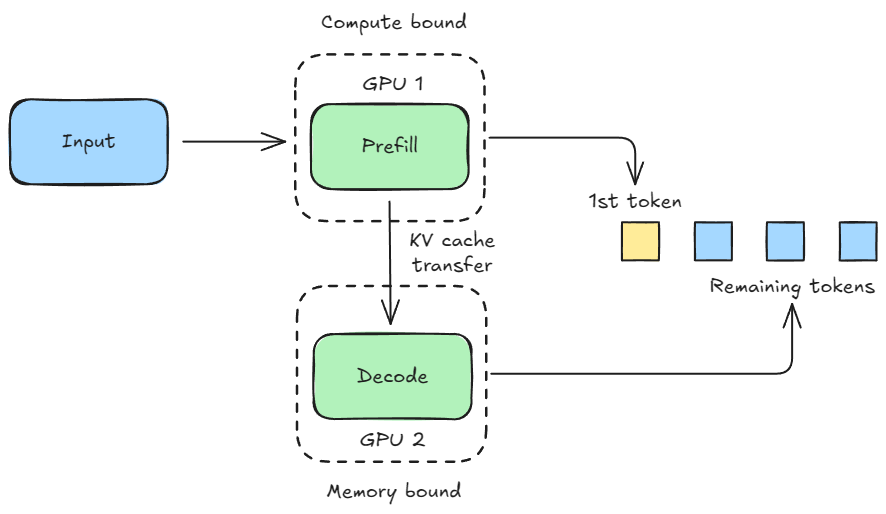
In contrast, a standard ML model typically has a single, unified computation phase.
GPU memory management + KV caching
Generating a new token uses the key and value vectors of all previous tokens. To avoid recomputing these vectors for all tokens over and over, we cache them (we covered KV caching in detail here):
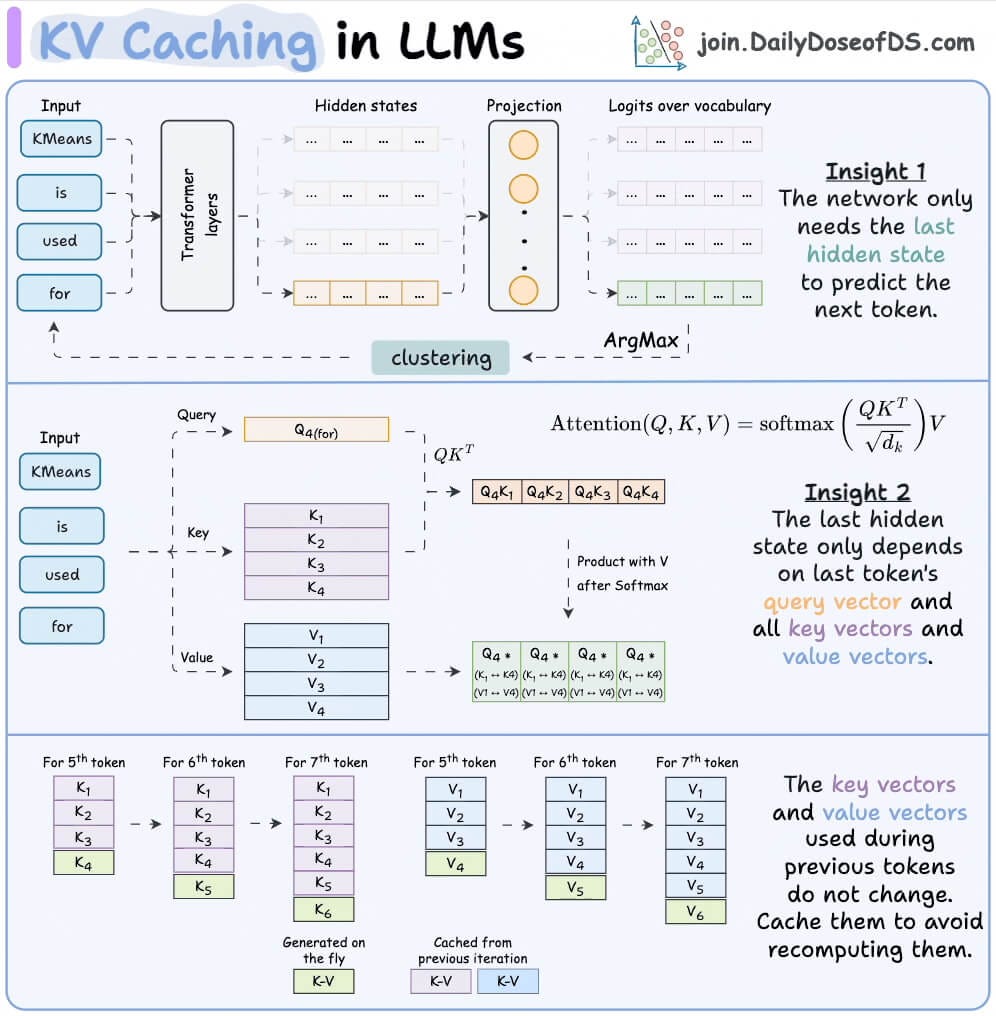
This KV Cache grows linearly with the total length of the conversation history.
But in many workflows, inputs like the system prompts are shared across many requests. So we can avoid recomputing them by using these KV vectors across all chats:
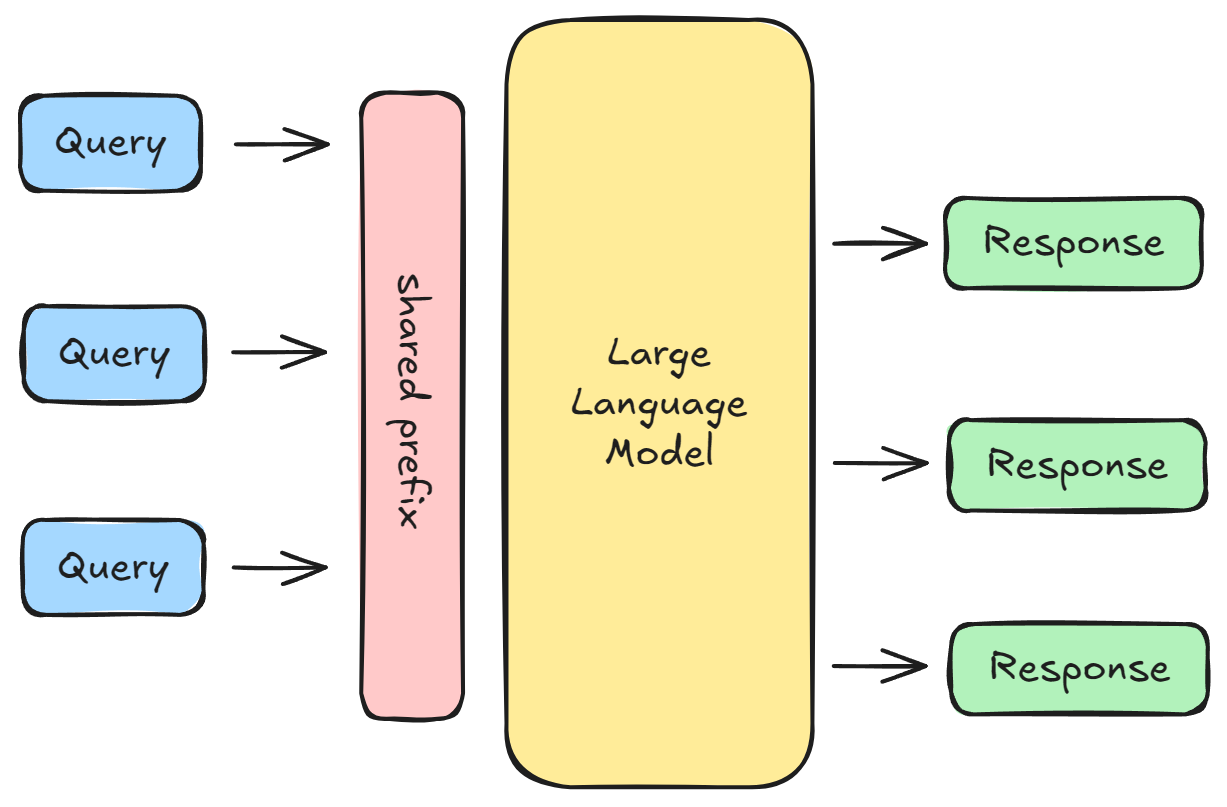
That said, KV cache takes up a significant memory since it’s stored in contiguous blocks. This wastes GPU memory and leads to memory fragmentation:

Paged Attention solves this problem by storing KV caching in non-contiguous blocks and then using a lookup table to track these blocks. The LLM only loads the blocks it needs, instead of loading everything at once.
We will cover Paged Attention in another issue.
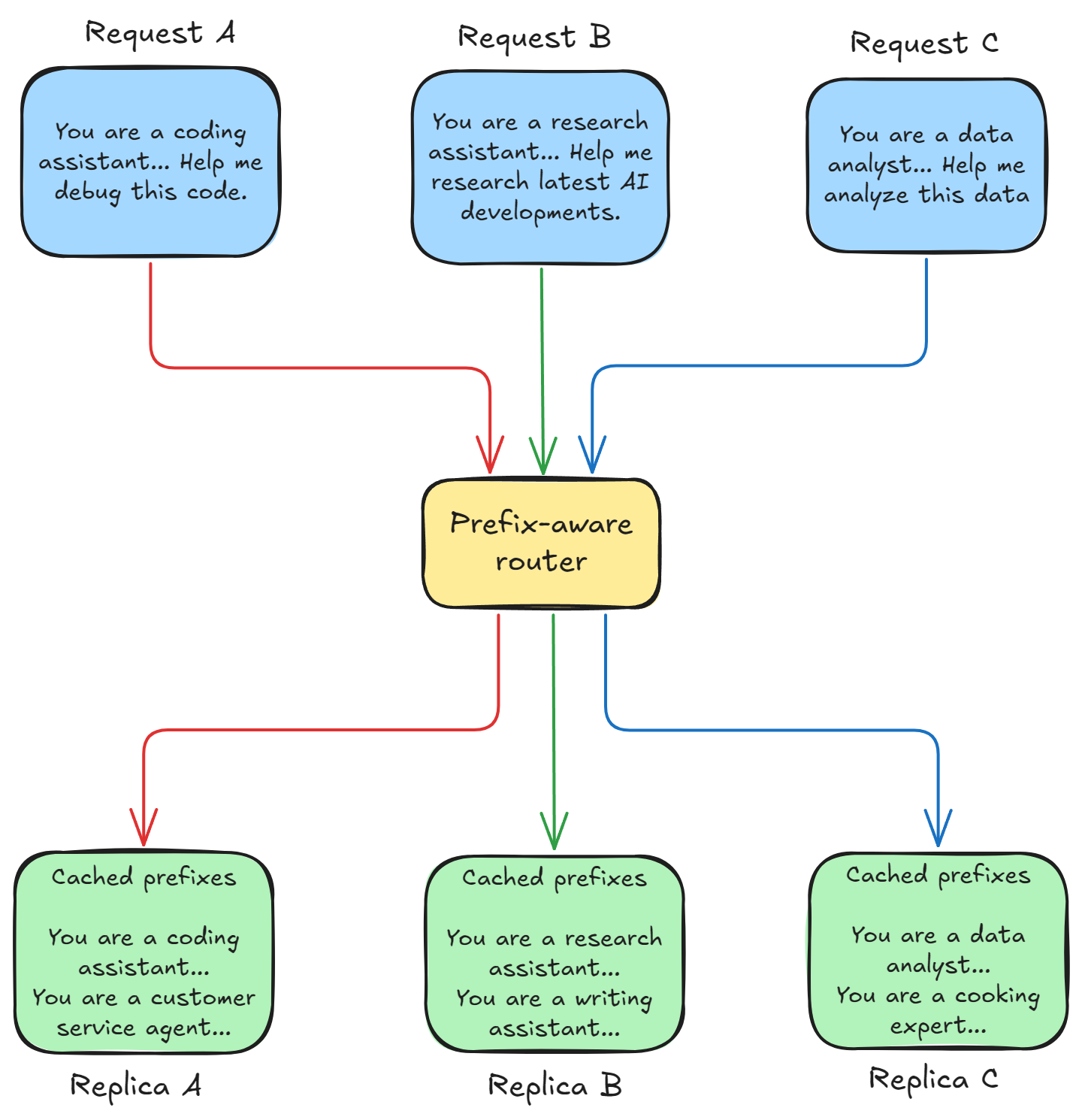
Prefix-aware routing
To scale standard ML models, you can simply replicate the model across multiple servers/GPUs and use straightforward load-balancing schemes like Round Robin or routing to the least-busy server.
Since each request is independent, this works fine.
But LLMs heavily rely on caching (like the shared KV prefix discussed above), so requests are no longer independent.
If a new query comes in with a shared prefix that has already been cached on Replica A, but the router sends it to Replica B (which is less busy), Replica B has to recompute the entire prefix’s KV cache.
Prefix-aware routing solves this.
Different open-source frameworks each have their own implementations for prefix-aware routing.
Generally, prefix-aware routing requires the router to maintain a map or table (or use a predictive algorithm) that tracks which KV prefixes are currently cached on which GPU replicas.
When a new query arrives, the router sends the query to the replica that has the relevant prefix already cached.
Model sharding strategies
There are several strategies to scale a dense ML model:
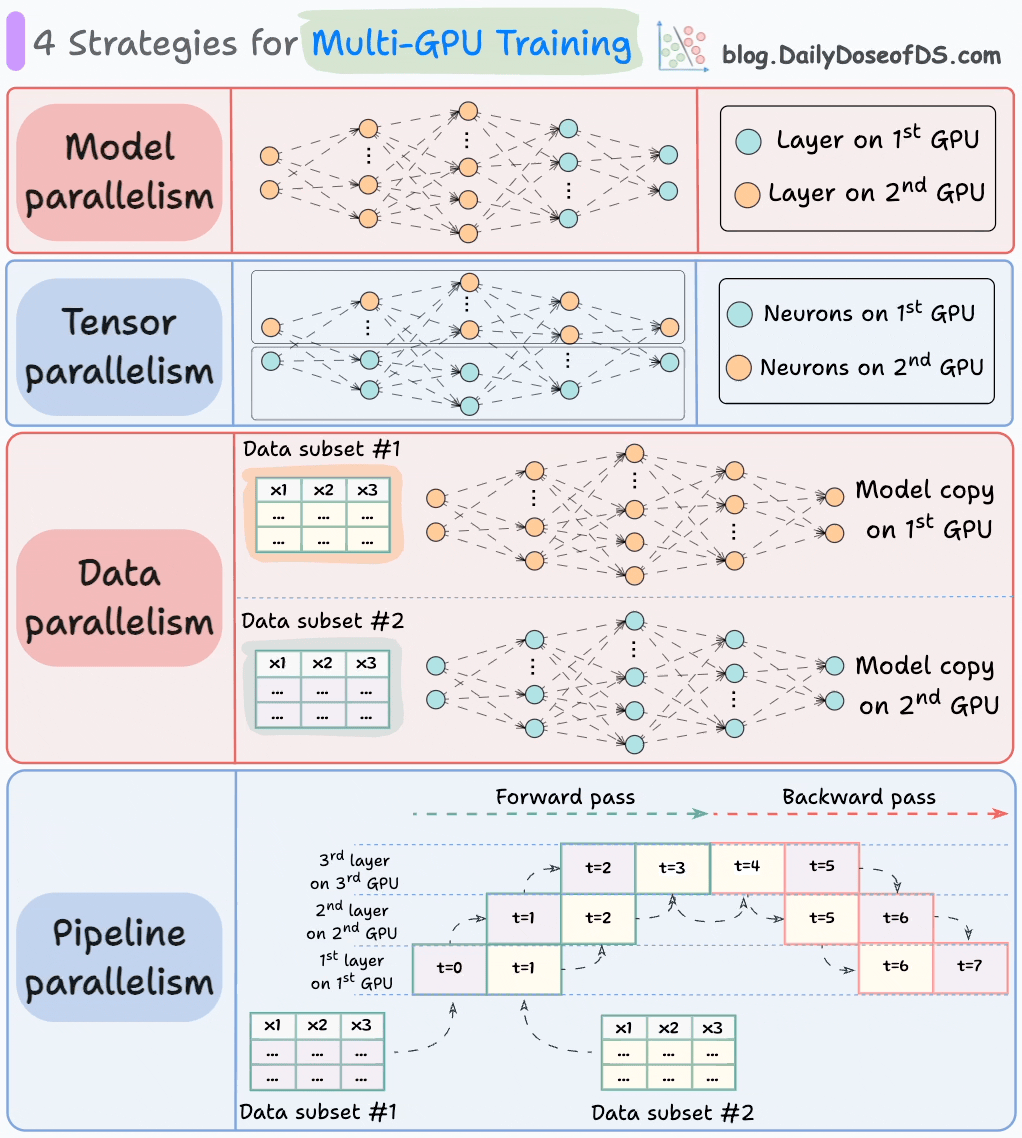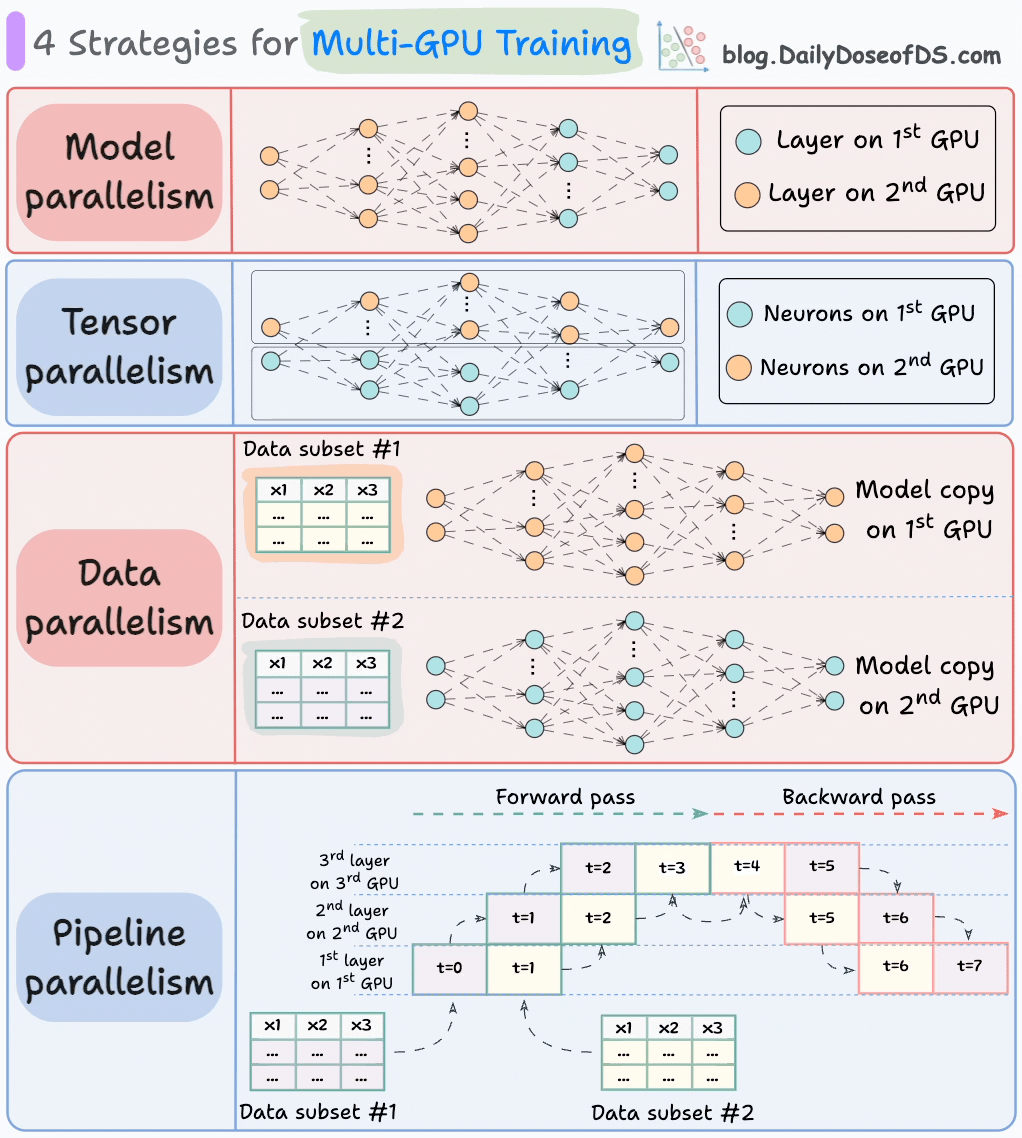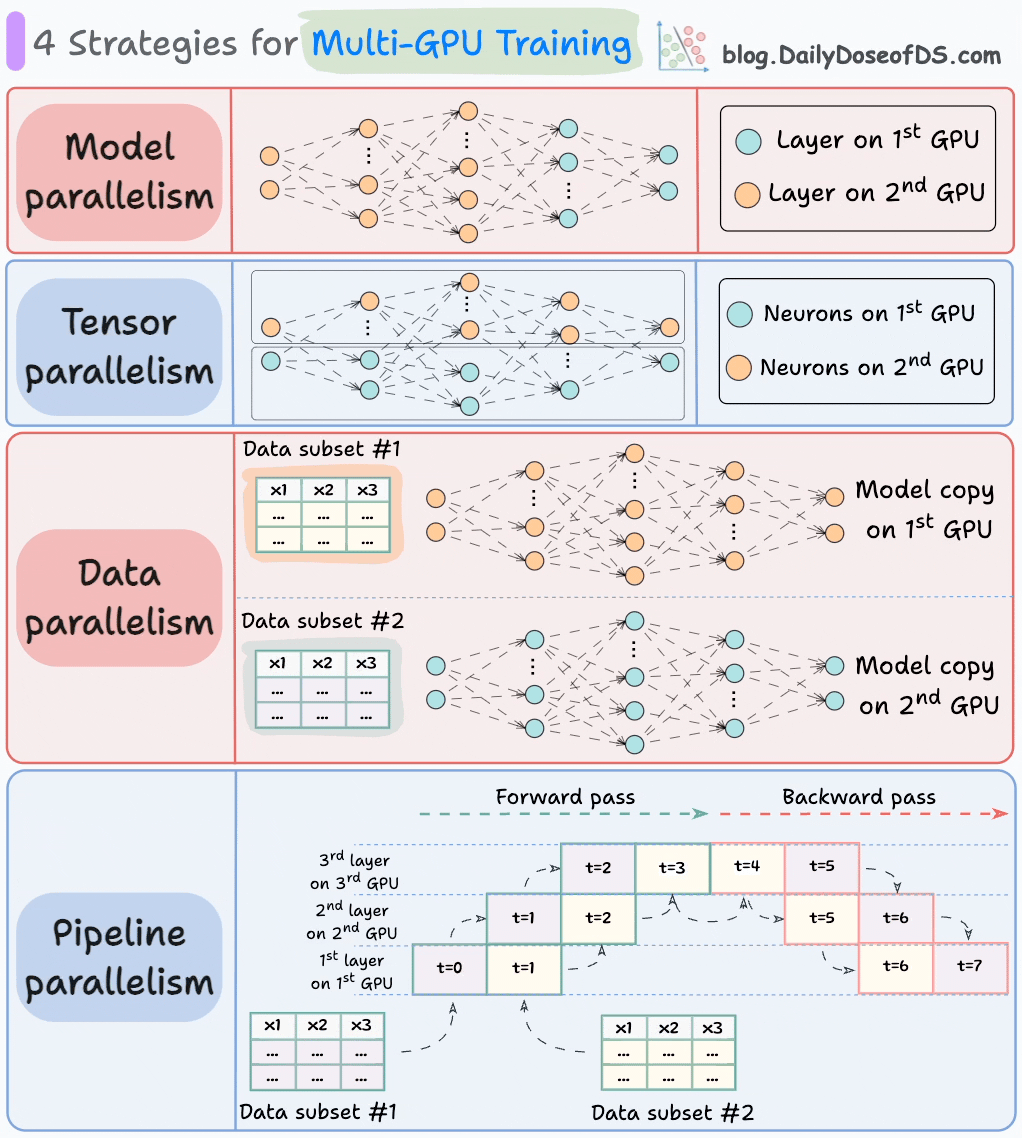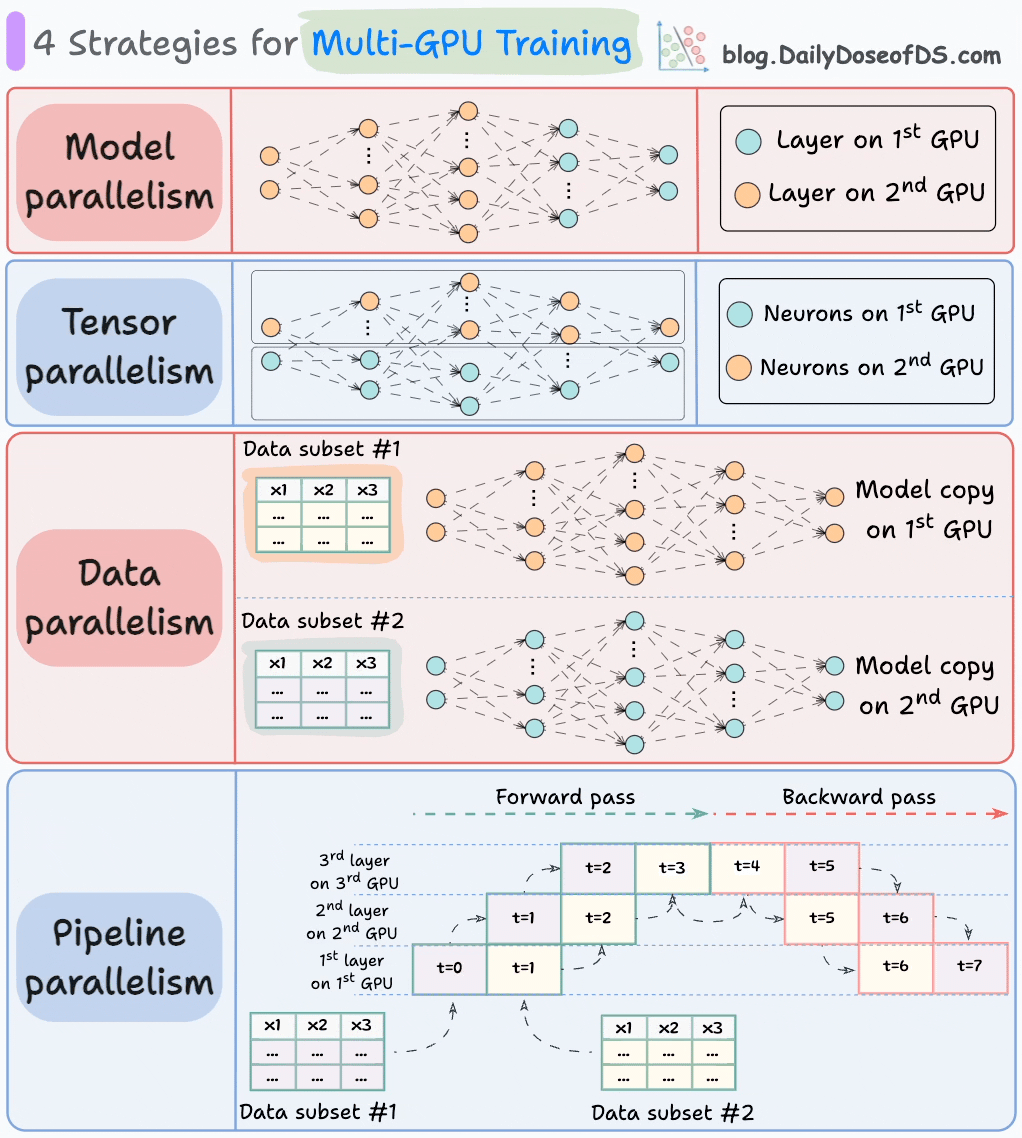
LLMs, like Mixture of Experts (MoE), are complicated.
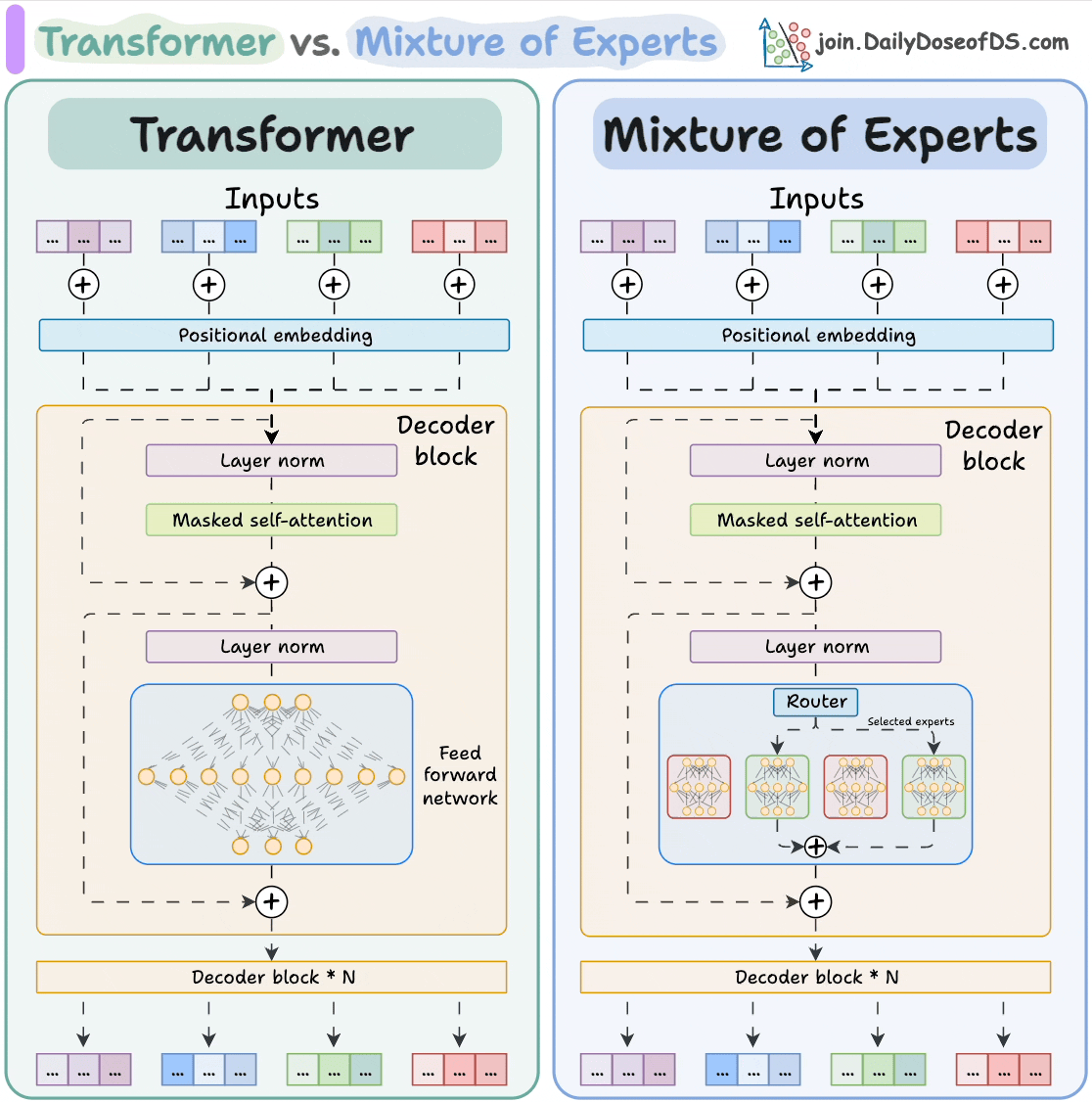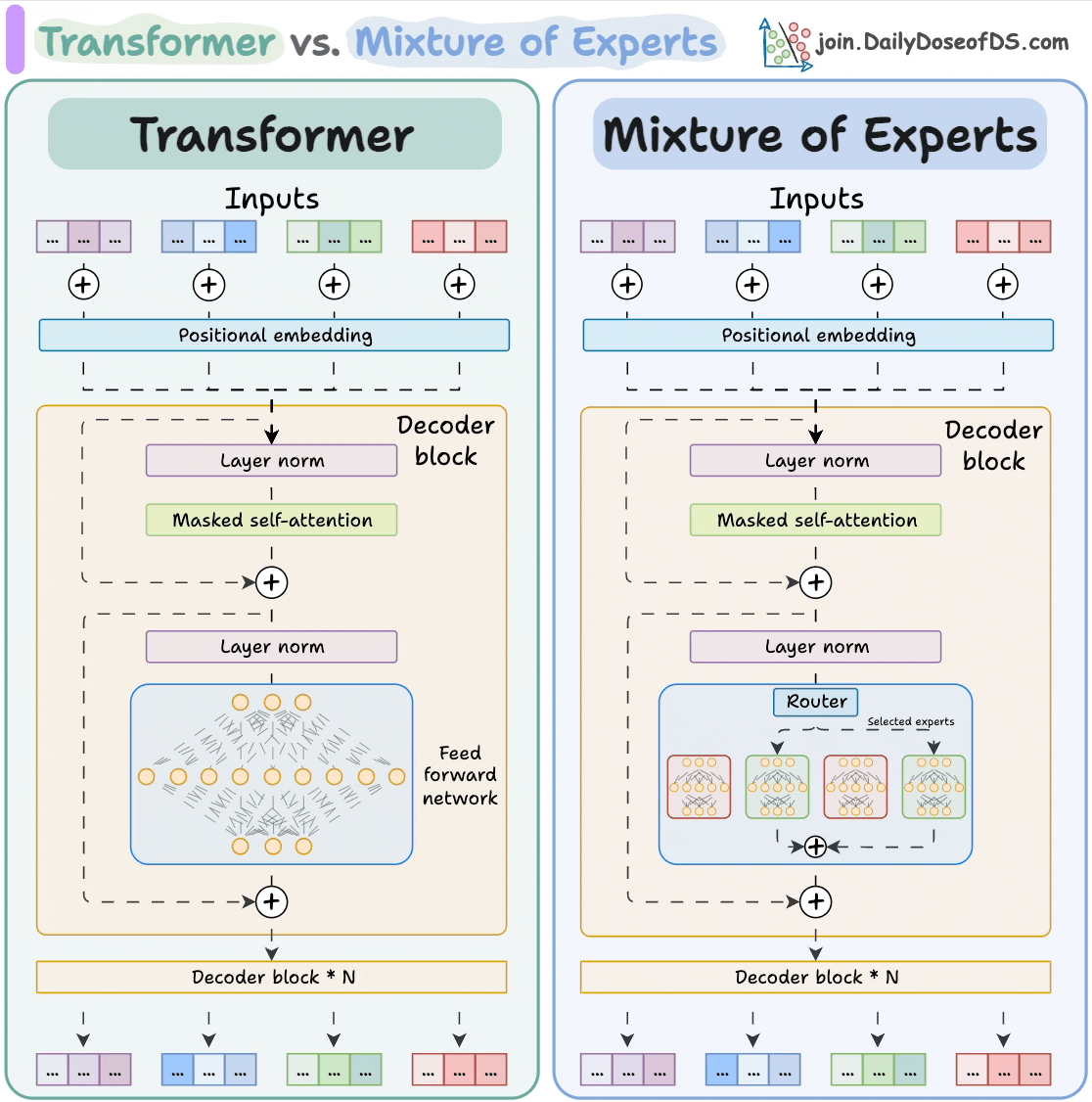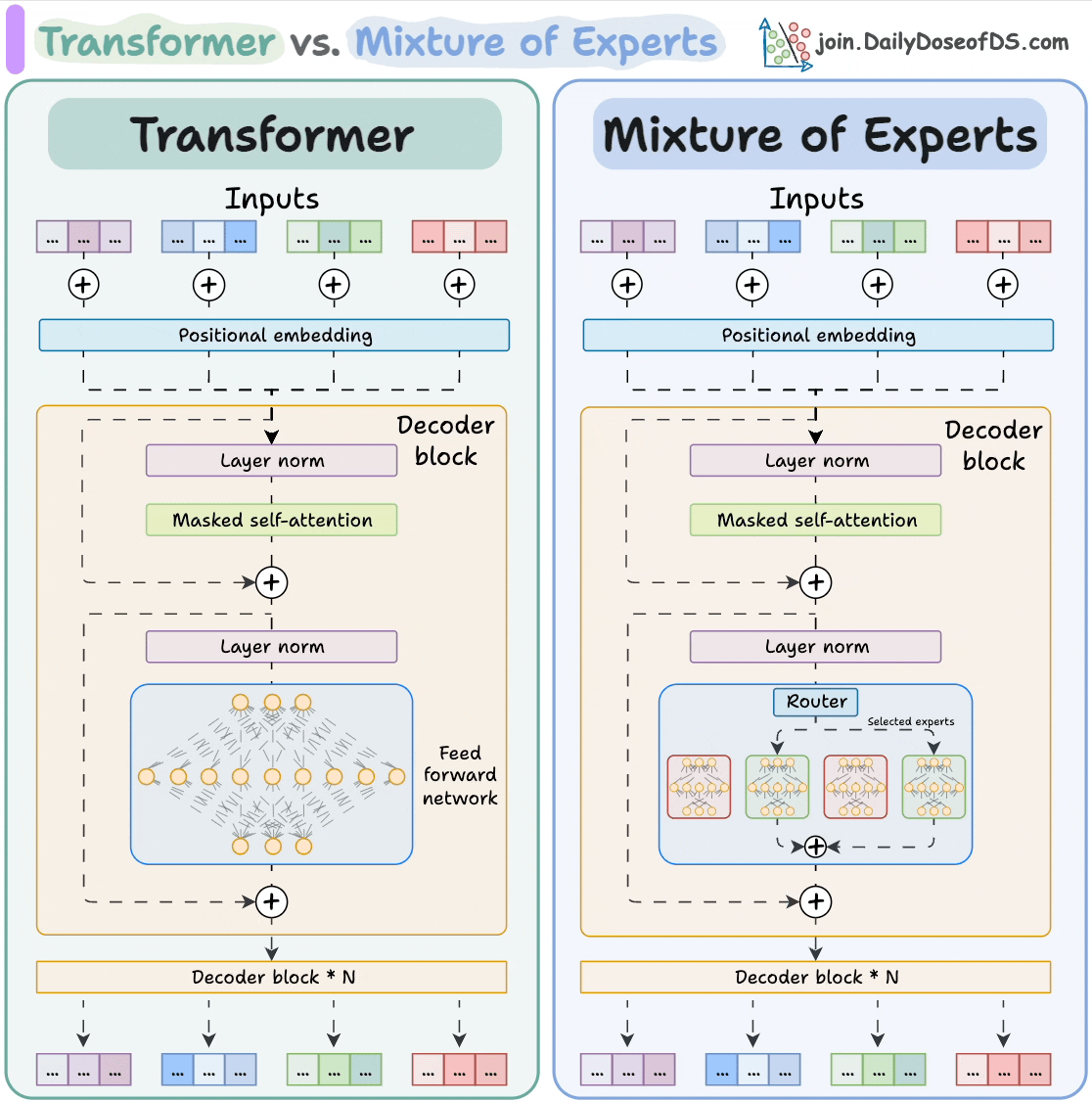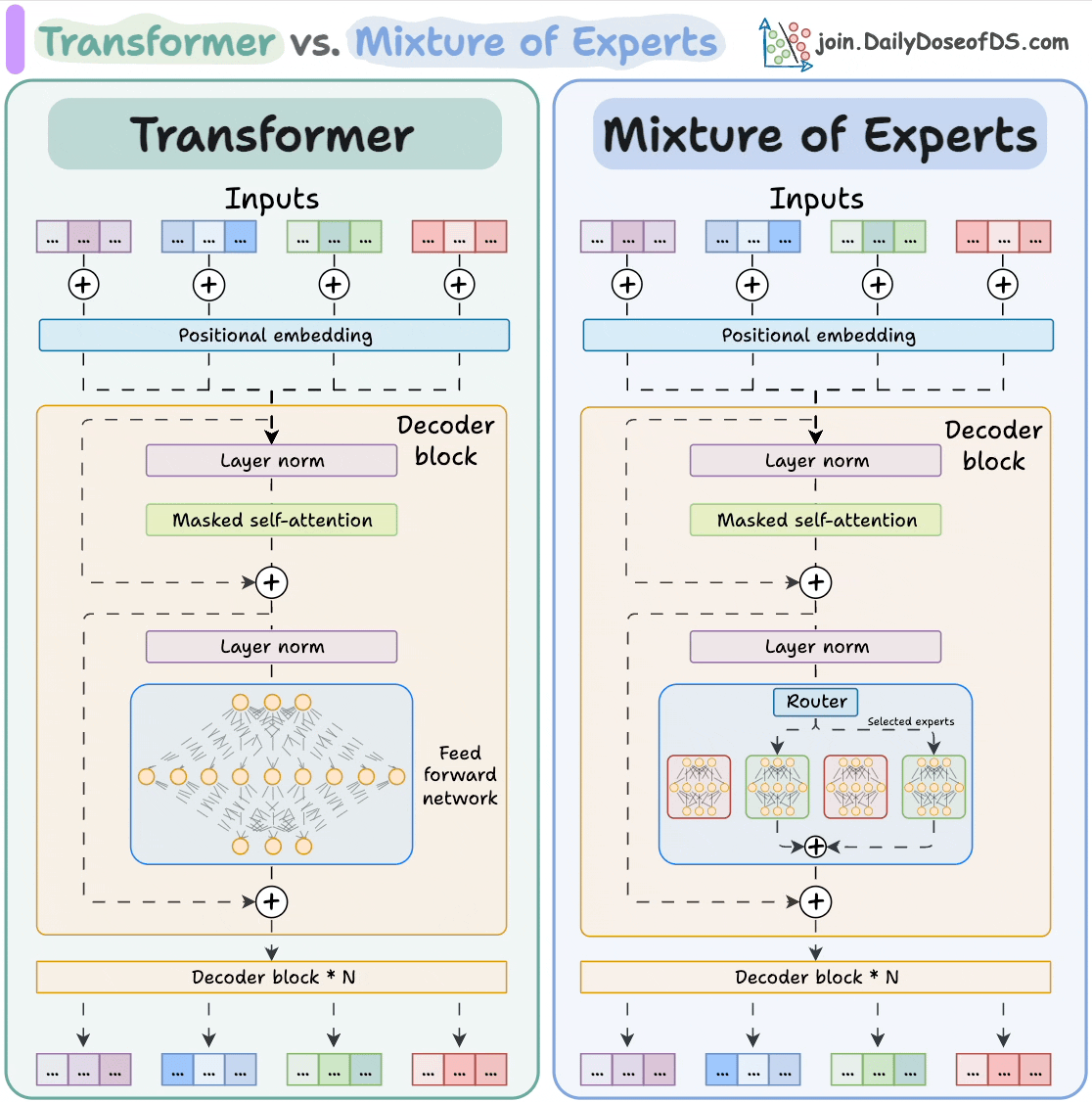
MoE models use a specialized parallelism strategy called expert parallelism, which splits the experts themselves across different devices, and the attention layers are replicated across all GPUs:
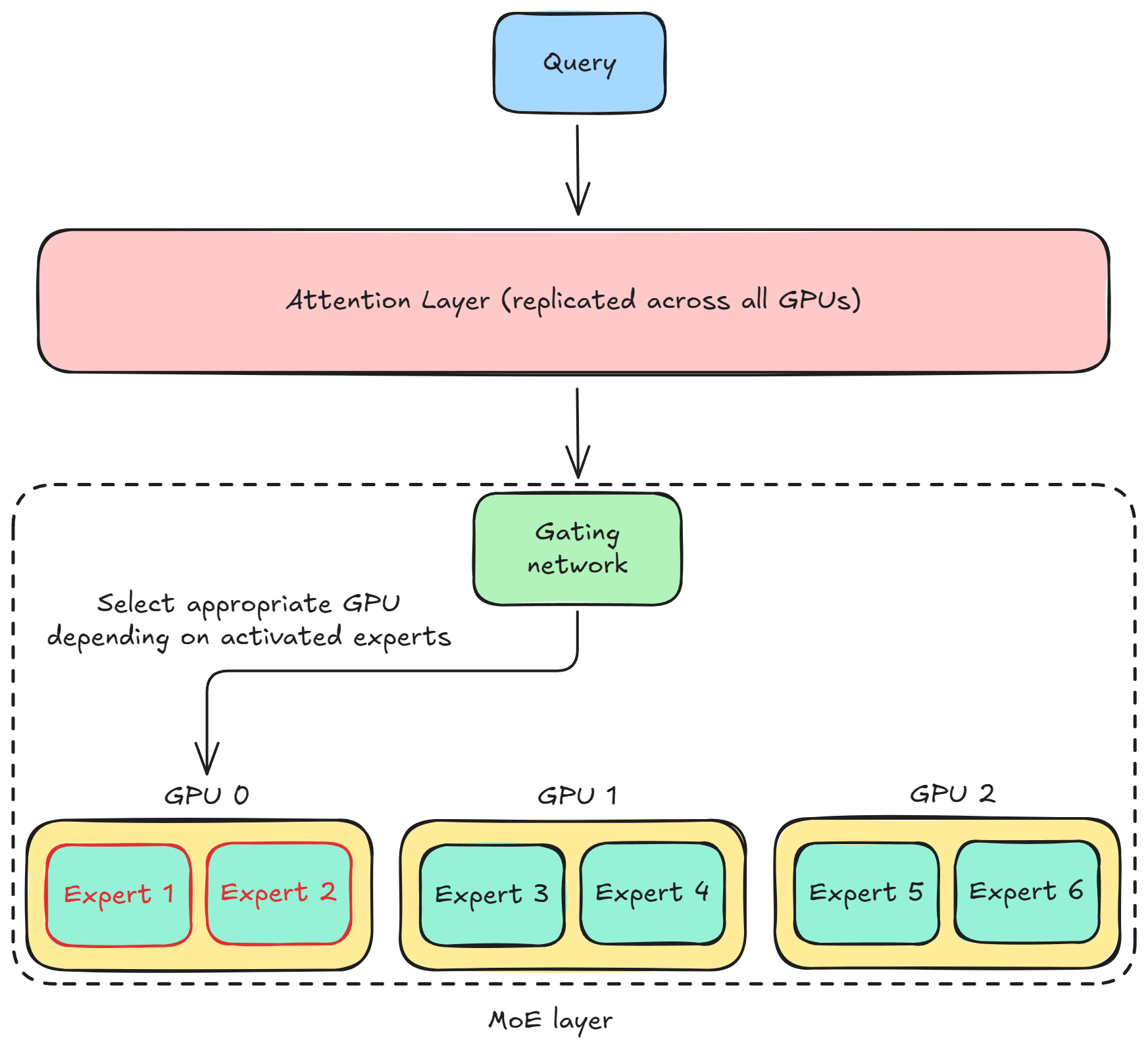
So each GPU holds the full weights of only some experts, not all. This means that each GPU processes only the tokens assigned to the experts stored on that GPU.
Now, when a query arrives, the gating network in the MoE layer dynamically decides which GPU it should go to, depending on which experts are activated.
This is a complex internal routing problem that cannot be treated like a simple replicated model. You need a sophisticated inference engine to manage the dynamic flow of computation across the sharded expert pool.
👉 Over to you: What are some other differences between LLM inference and regular inference?
Thanks for reading!