
REINFORCE and Actor-critic Methods in RL
The full RL nanodegree, covered with implementation.

Part 7 of the Reinforcement Learning course is here.
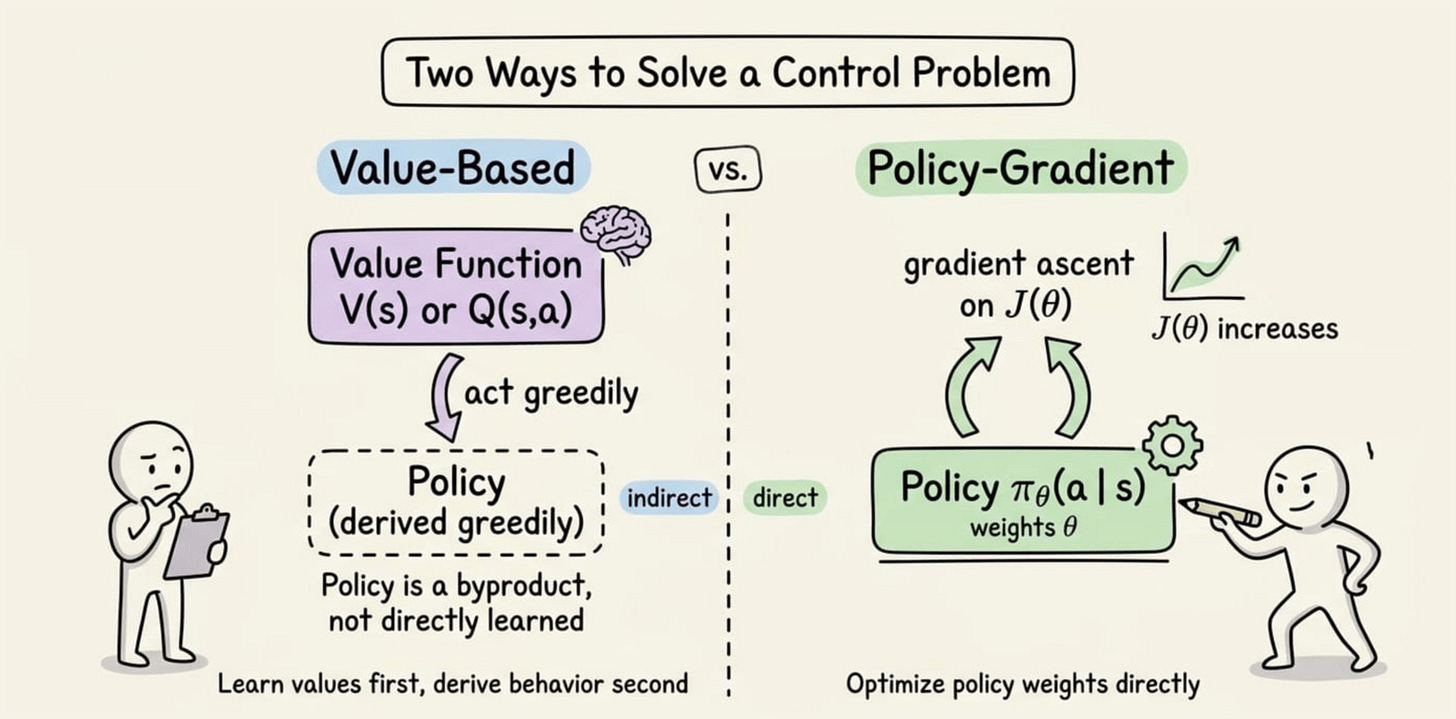
Every method up to this point learned a value function first and derived behavior from it. In this chapter, instead of scoring actions and picking the best one, we learn the choosing itself.
You can read Part 7 of the course here →
It covers:
Why learning the policy directly matters
The log-derivative trick
The REINFORCE algorithm
The variance problem
The advantage function
The actor-critic architecture
Generalized advantage estimation (GAE)
How LLMs are tuned with RL
And a hands-on comparison of REINFORCE vs. actor-critic on CartPole showing the variance difference in real training curves.
Everything is covered from scratch, so no RL background is required.
You can read Part 7 of the course here →
Why care?
Techniques like RLHF, PPO, GRPO, and DPO show up in every model release announcement.
But the machinery underneath them is often treated as a black box.
PPO becomes a library call.
RLHF becomes a pipeline stage.
GRPO becomes a config option.
All of them are built on policy gradients, advantage estimation, and actor-critic architectures.
The policy gradient theorem, the variance-bias tradeoff, GAE, and baselines are the actual moving parts that determine whether post-training succeeds or fails.
When things go wrong (through reward hacking, training instability, mode collapse), understanding these fundamentals is what lets you reason about why, instead of just tuning hyperparameters and hoping.
This series builds that layer of understanding from the ground up.
In the last seven chapters, we have covered bandits, MDPs, value functions, deep Q-learning, and now we have the policy gradient methods that power modern LLM alignment.
Each concept builds on the last, and by this point, things like advantage-weighted policy updates feel like natural tools rather than abstract formulas.
👉 Over to you: What topics would you like us to cover in this RL series?
Thanks for reading!