
Relational DBs vs FalkorDB
...explained visually!

One workspace for your entire agent stack
Building Agents requires more than just an LLM with tool calls for any practical utility.
You need to store state between runs, a knowledge base that agents can actually query, a cron-based scheduler that executes without a manual trigger, and integrations that don’t require you to write a new connector every time.
Devs stitch all of this together themselves, but now Sim’s Mothership has an elegant solution to this.
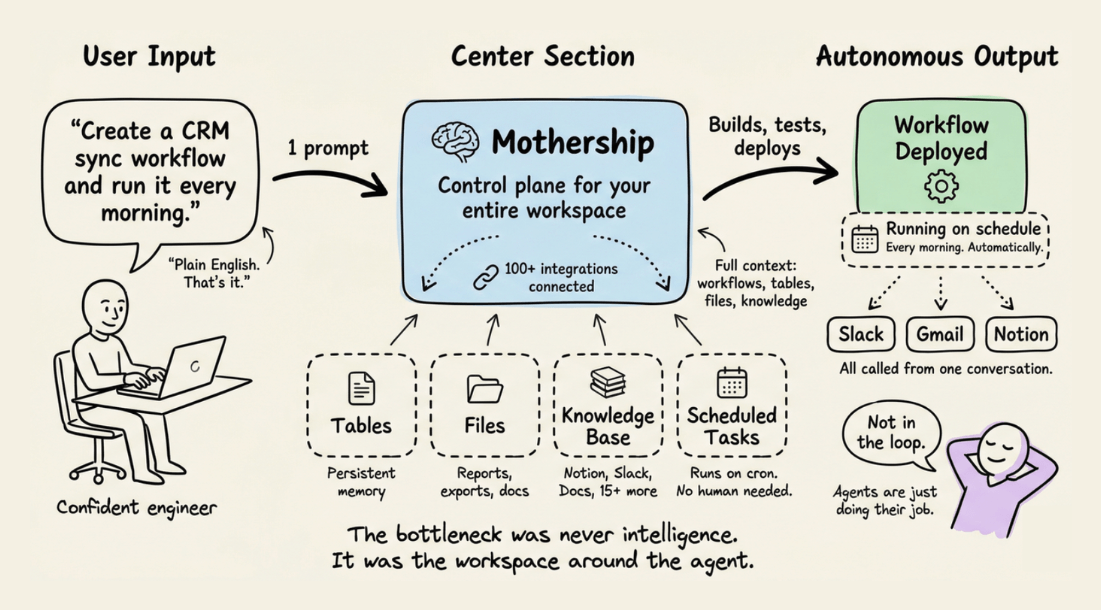
Under the hood, it gives typed tables for persistent state, knowledge base connectors that auto-index from Notion, Slack, GitHub, and 15+ others, and a task scheduler with two execution modes:
persistent for recurring cron jobs
until_completefor polling workflows that stop once a condition is met.
A natural language control plane sits on top of all of it.
We are working on a demo and will release it soon, but in the meantime, you can try it yourself here →
Relational DBs vs FalkorDB
Imagine you want to find all accounts within 3 hops of a suspicious transaction, or link fragmented customer records across systems by shared emails and phone numbers.
These are graph traversal queries. SQL can handle relationships, but not depth.
Sure, you can write recursive CTEs and self-joins. That works at 1-2 hops, but if you go deeper, two things happen:
The query becomes unreadable
And the performance drops
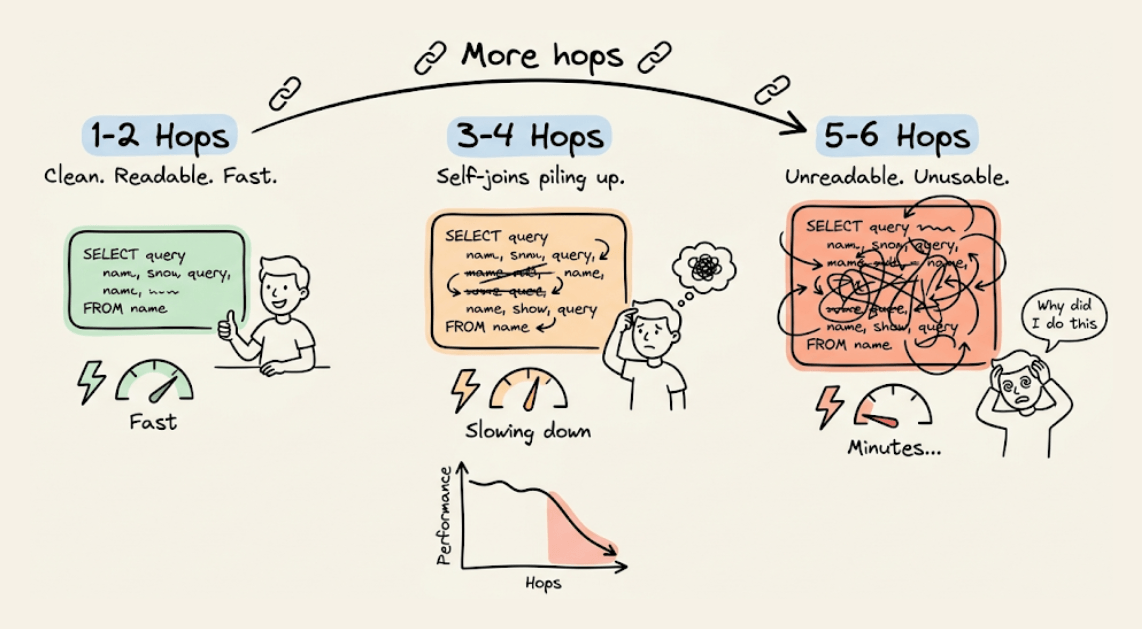
Each hop adds another self-join. By hop 5-6, you’re looking at queries that run for minutes and fall apart under load.
Now this is the Cypher equivalent of the same query:
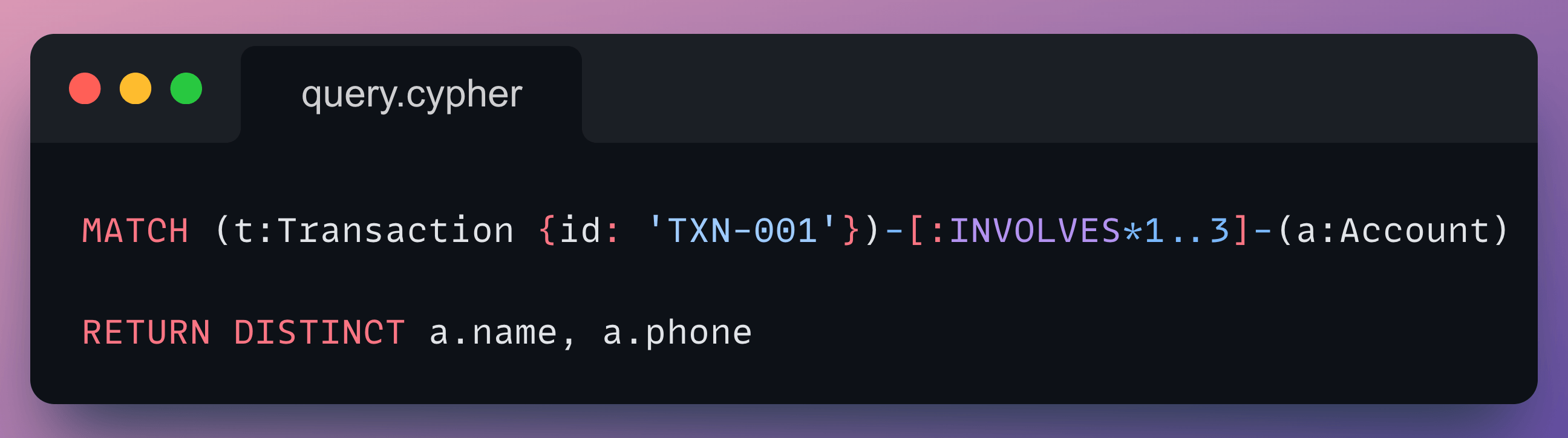
Graph databases solve this.
But not all of them solve it the same way.
Most graph DBs traverse relationships by physically jumping from node to node.
Each hop is a separate pointer lookup. At shallow depths, this is fine. But as your query goes deeper, these lookups stack up and latency compounds with every hop.
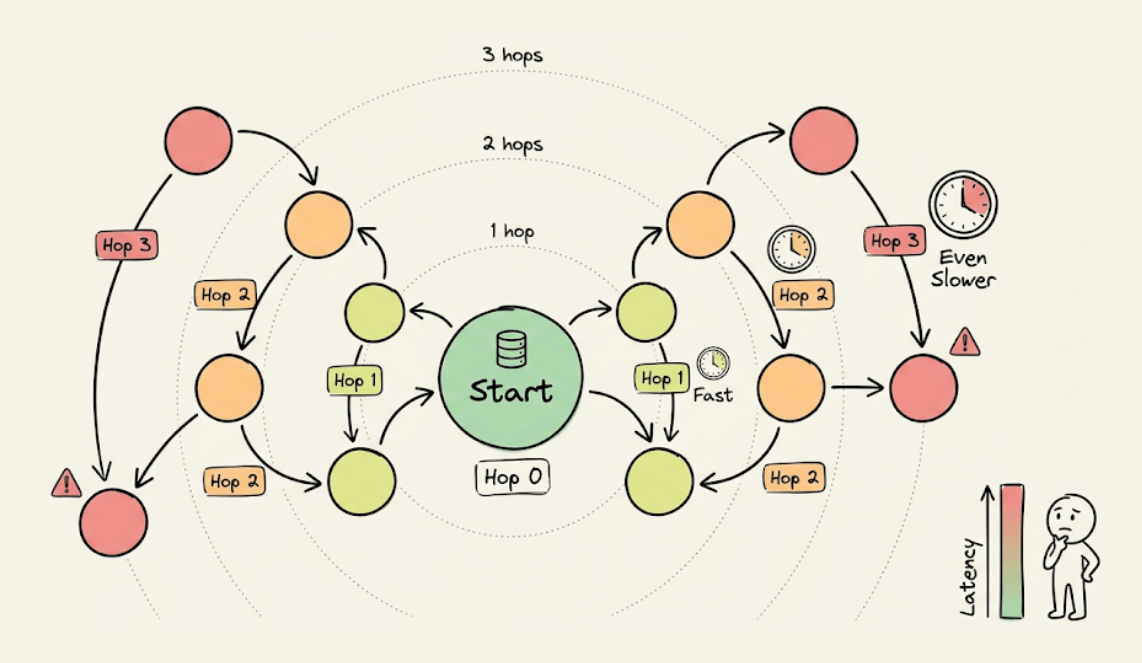
FalkorDB takes a fundamentally different approach under the hood.
Most graph DBs chase pointers from node to node during traversal. FalkorDB doesn’t do that.
It’s built on GraphBLAS, a linear algebra framework that represents graph operations as sparse matrix computations. Each hop becomes an optimized matrix operation instead.
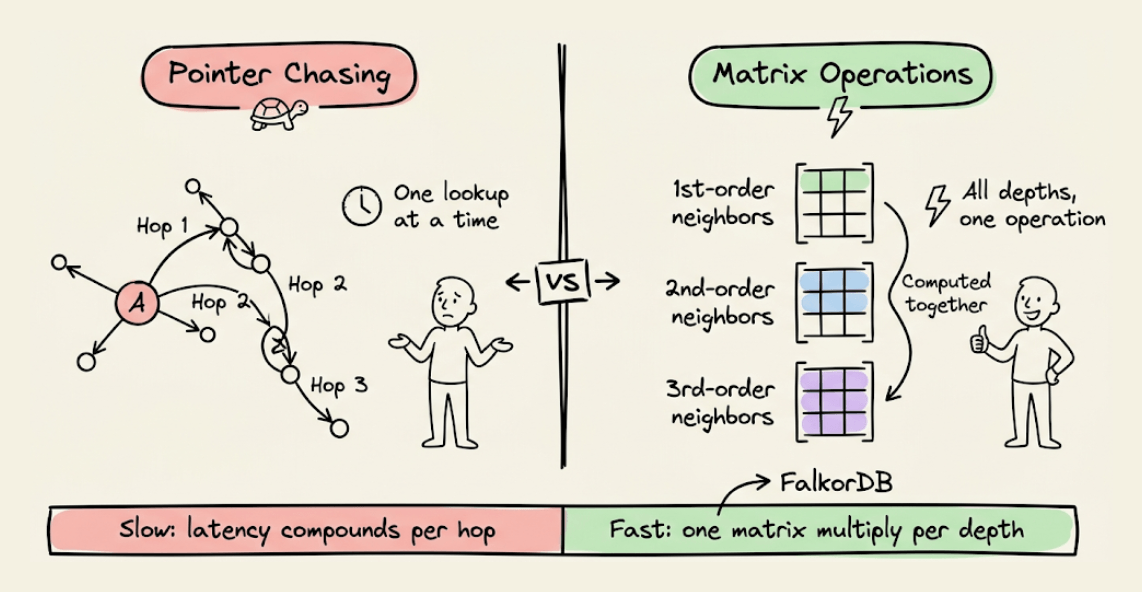
This results in a better cache behavior, and due to parallel computation across hops, it provides sub-millisecond latency on deep multi-hop queries/
It also uses openCypher. So if you’ve written Cypher before (say, with Neo4j), the syntax is identical. No new query language to pick up.
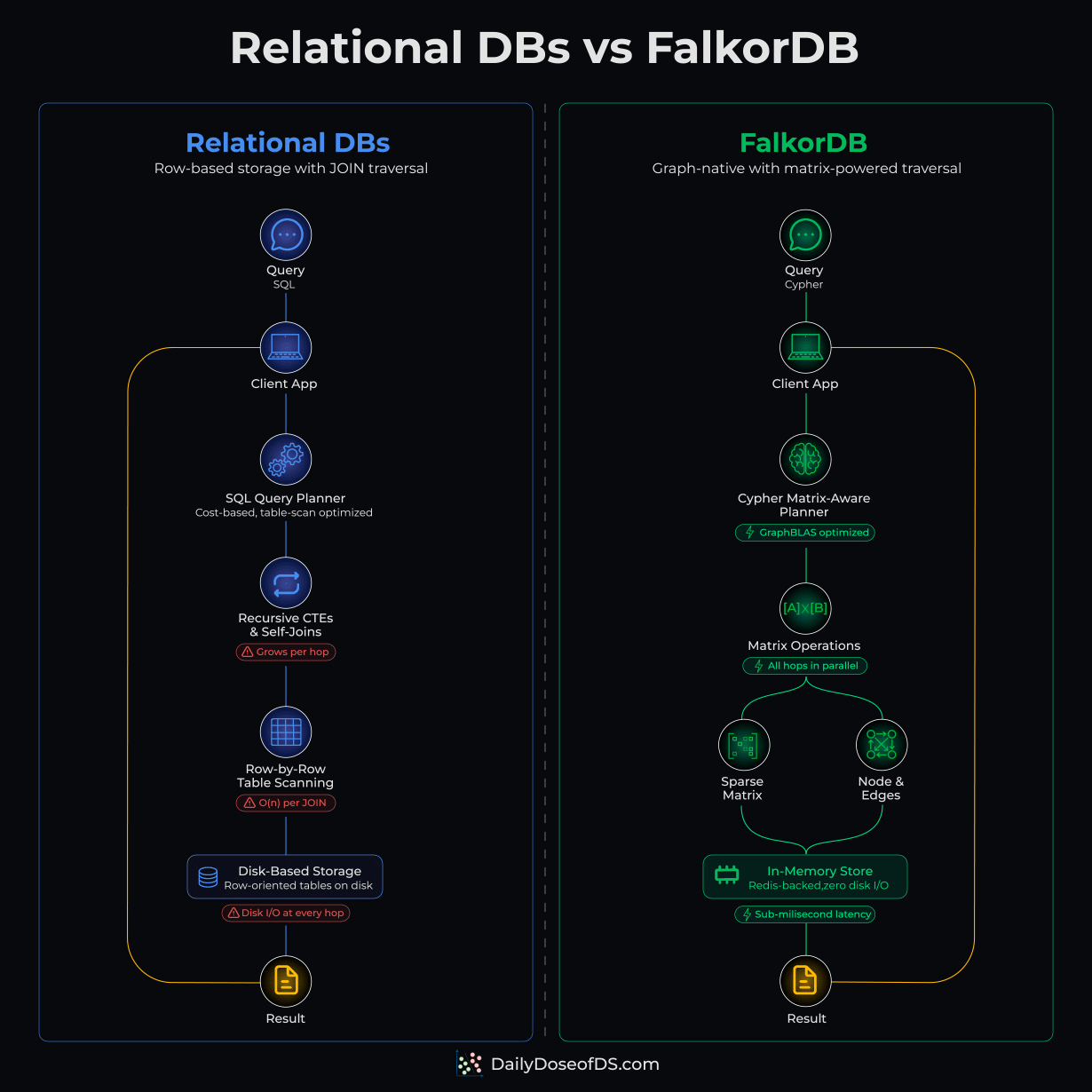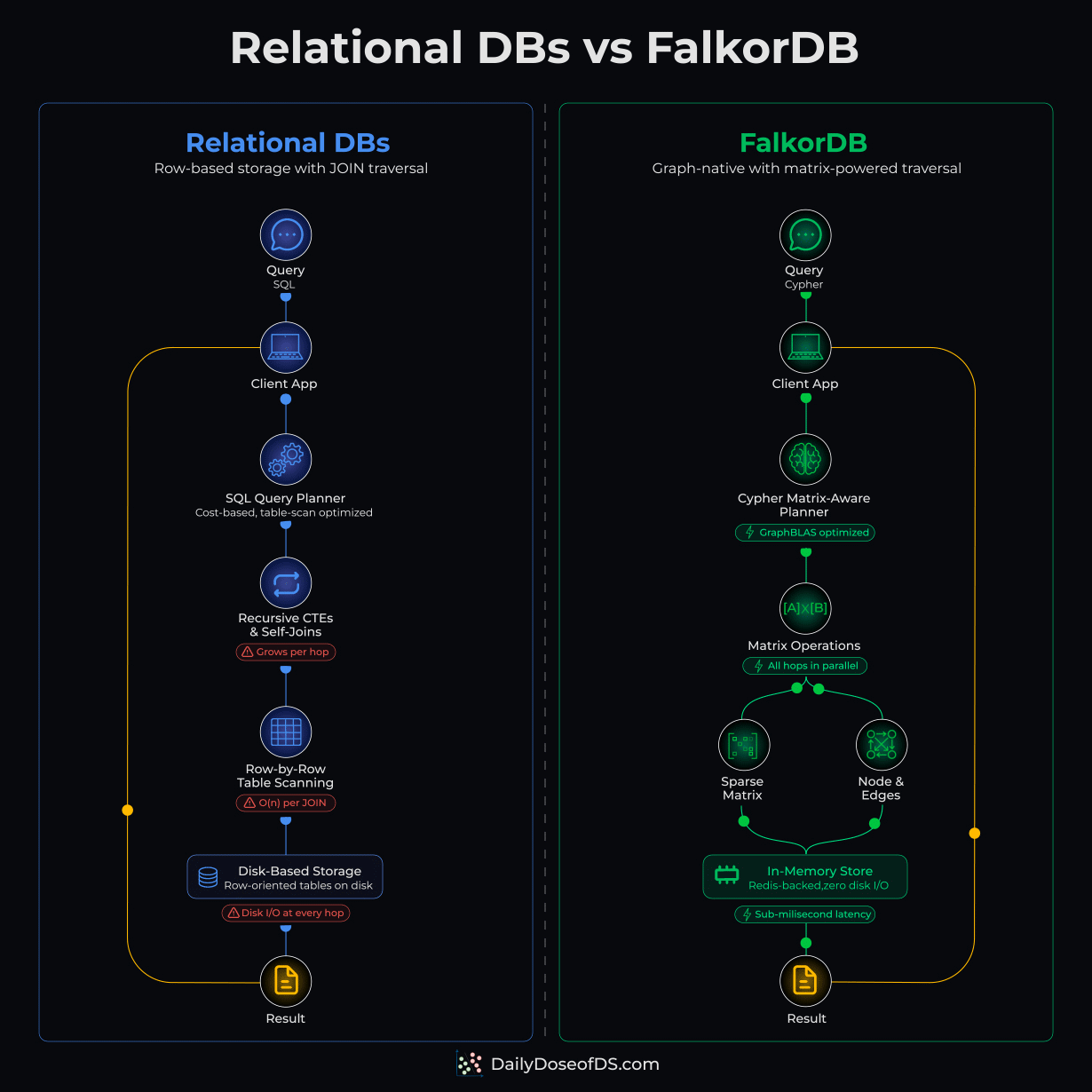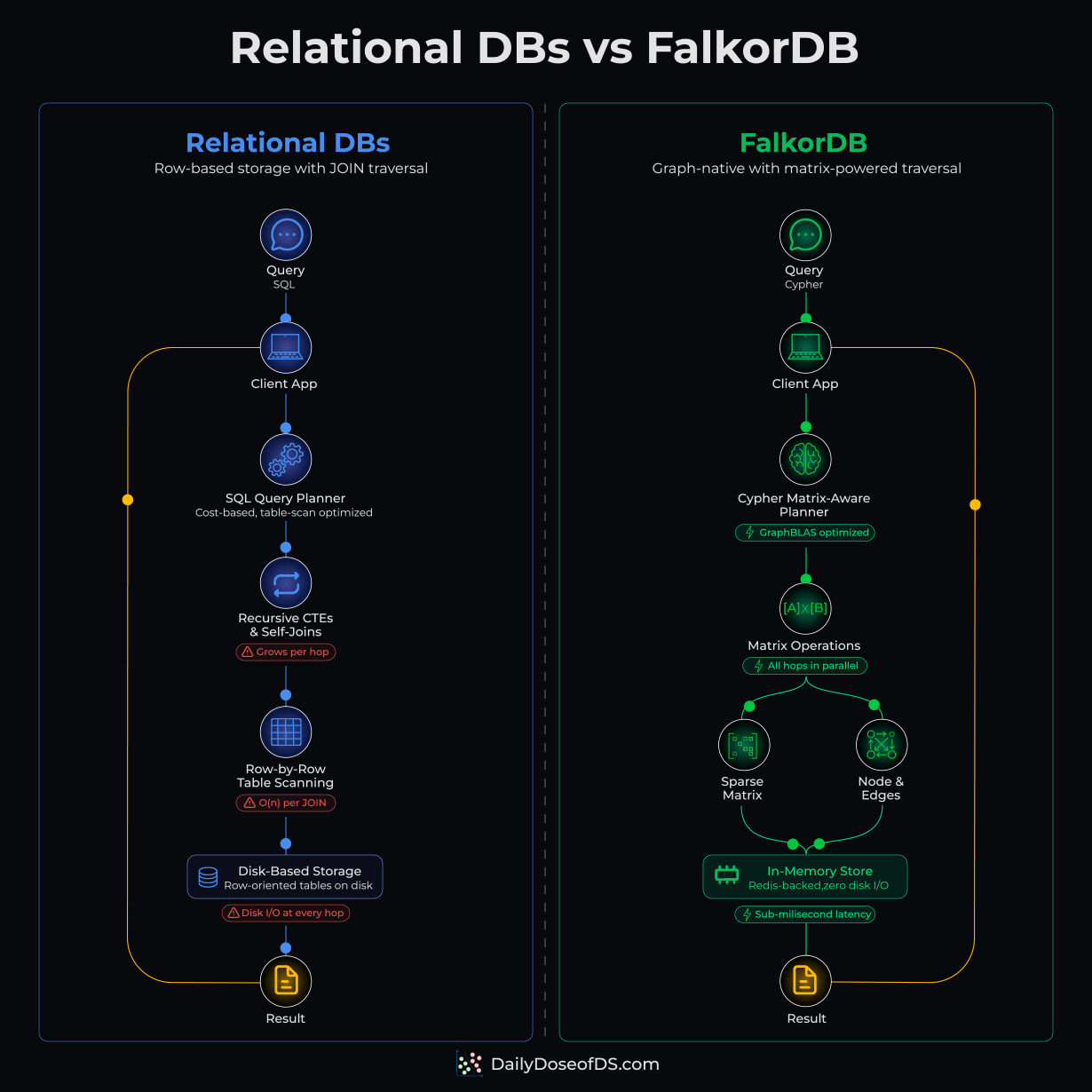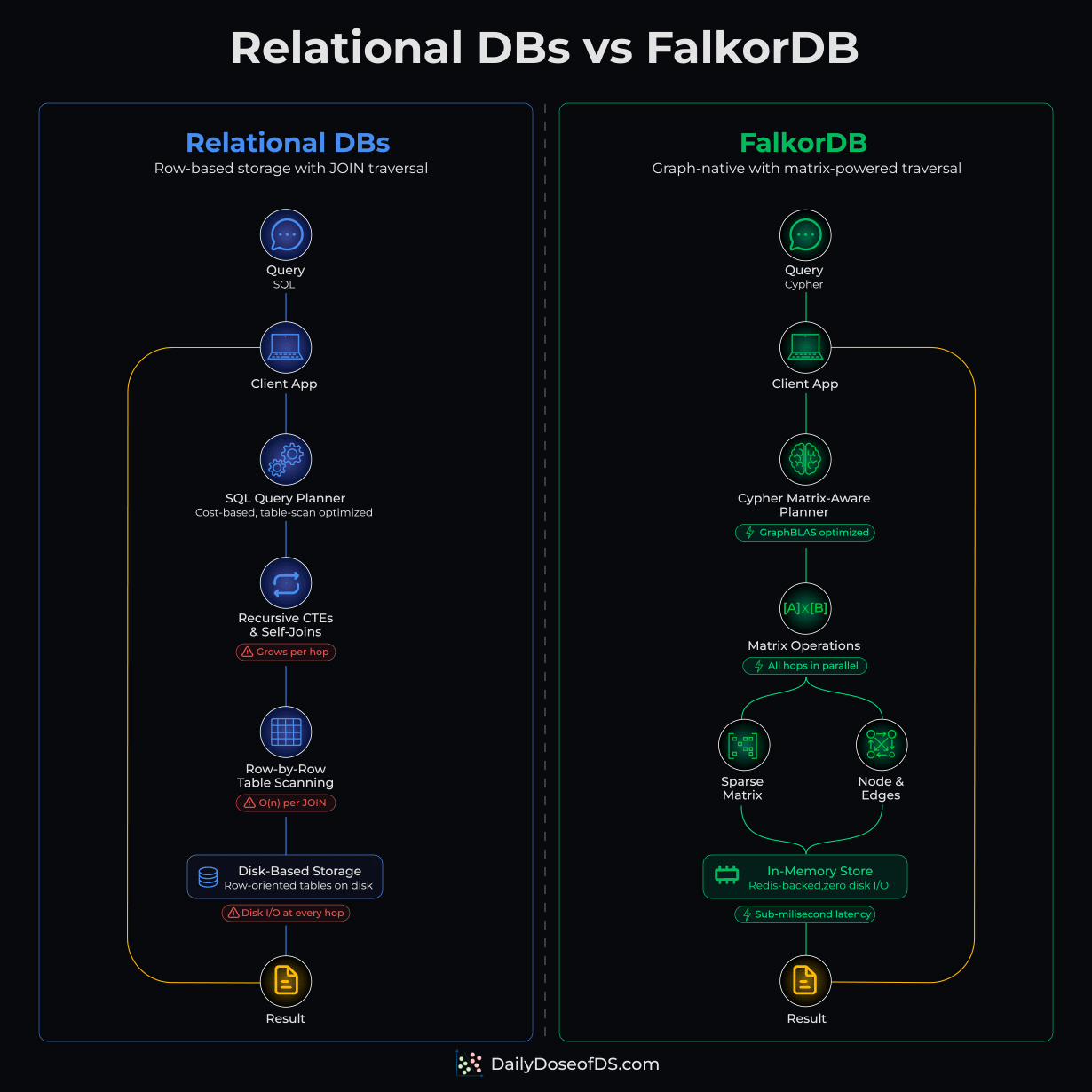
The graphic shared above nicely illustrates how FalkorDB is superior to traditional relational DBs.
You can find the FalkorDB GitHub repo here →
And we mentioned a few days back in this newsletter that if your data lives in Snowflake, FalkorDB has a Native App on Snowflake.
You can bind your tables through the UI, load them into a graph, and query with Cypher. Results come back as rows in your worksheet, ready for further analysis.
You can find it here on Snowflake →
Thanks for reading!