
Researchers Found a Way to Make LLMs 8.5x Faster!
(without compromising accuracy)

Documentation that keeps pace with the codebase
Doc Holiday solves the documentation lag that ships with every release. Most teams treat docs as a post-ship task. In practice, it gets skipped. Changelogs go unwritten. Customer announcements are often held up for weeks. The support team ends up one release behind, permanently.
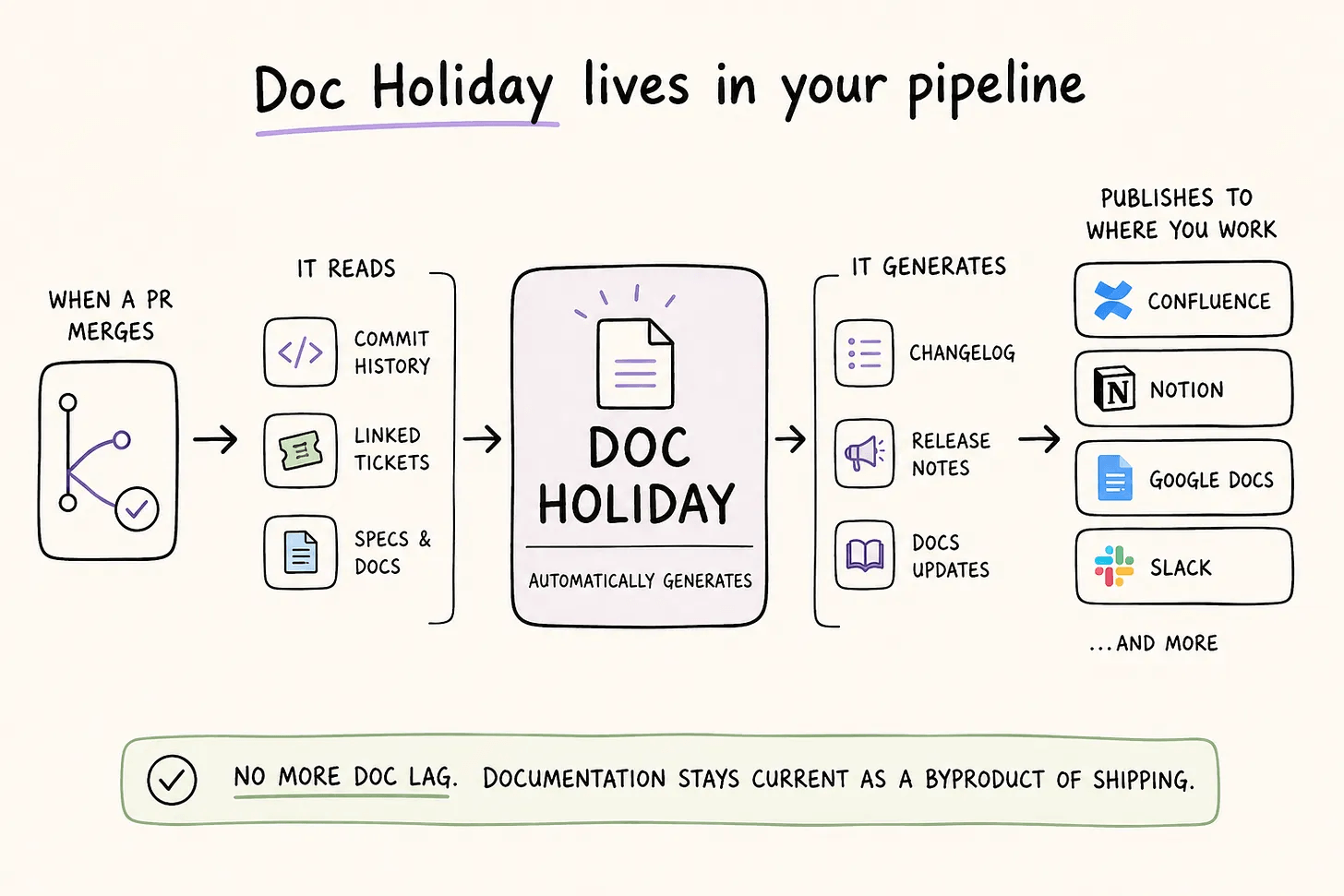
To eliminate the lag, Doc Holiday sits in the CI/CD pipeline. When a PR merges, it reads the commit history, linked tickets, and connected specs, then generates the changelog, release notes, and documentation updates. Outputs go to wherever the team already works: Confluence, Notion, Google Docs, Slack.
Documentation stays current as a byproduct of shipping, not as a separate effort.
Get started with Doc Holiday here →
Thanks to Doc Holiday for partnering today!
Researchers found a way to make LLMs 8.5x faster!
Speculative decoding is quite an effective way to address the single-token bottleneck in traditional LLM inference.
A small “draft” model first generates the next several tokens, then the large model verifies all of them at once in a single forward pass.
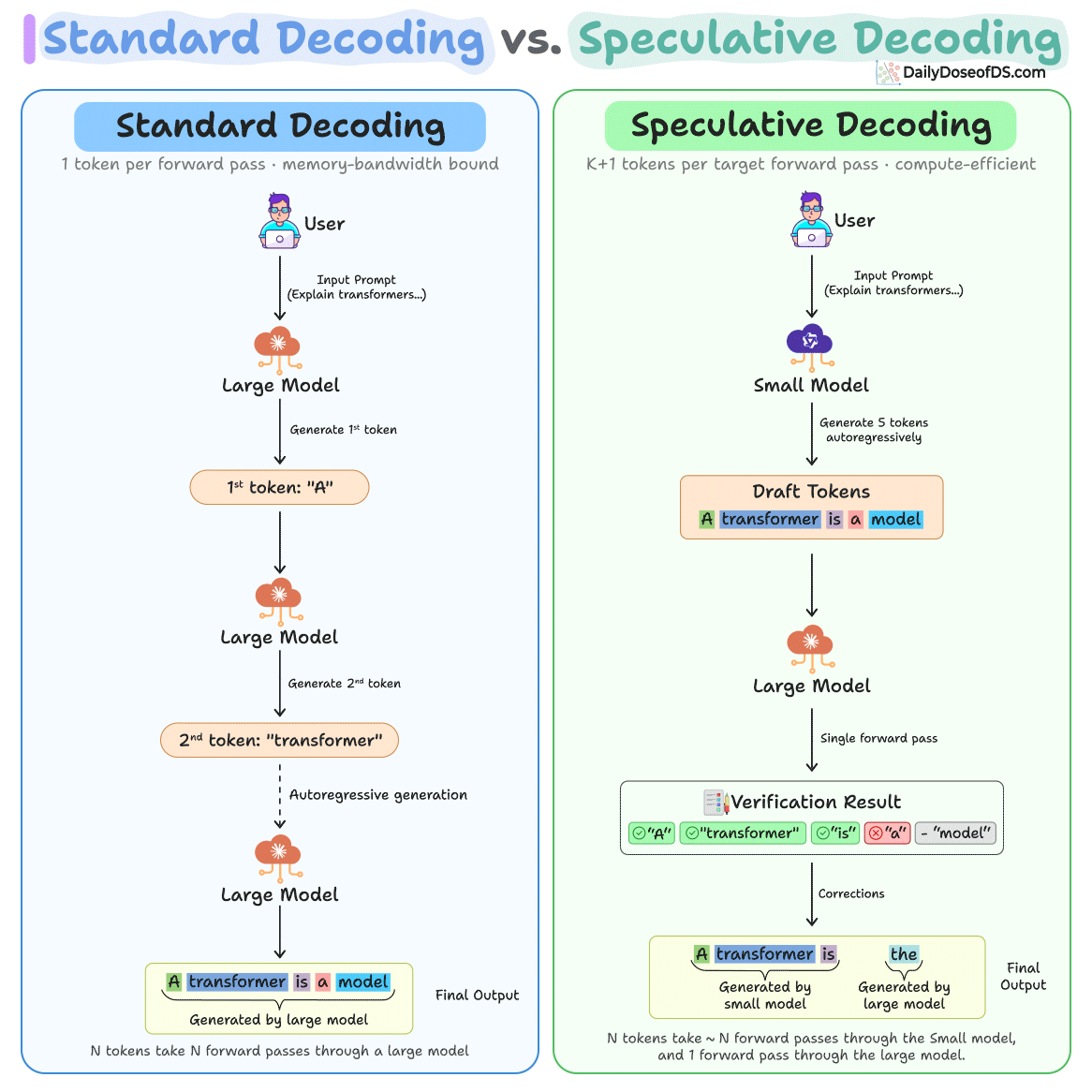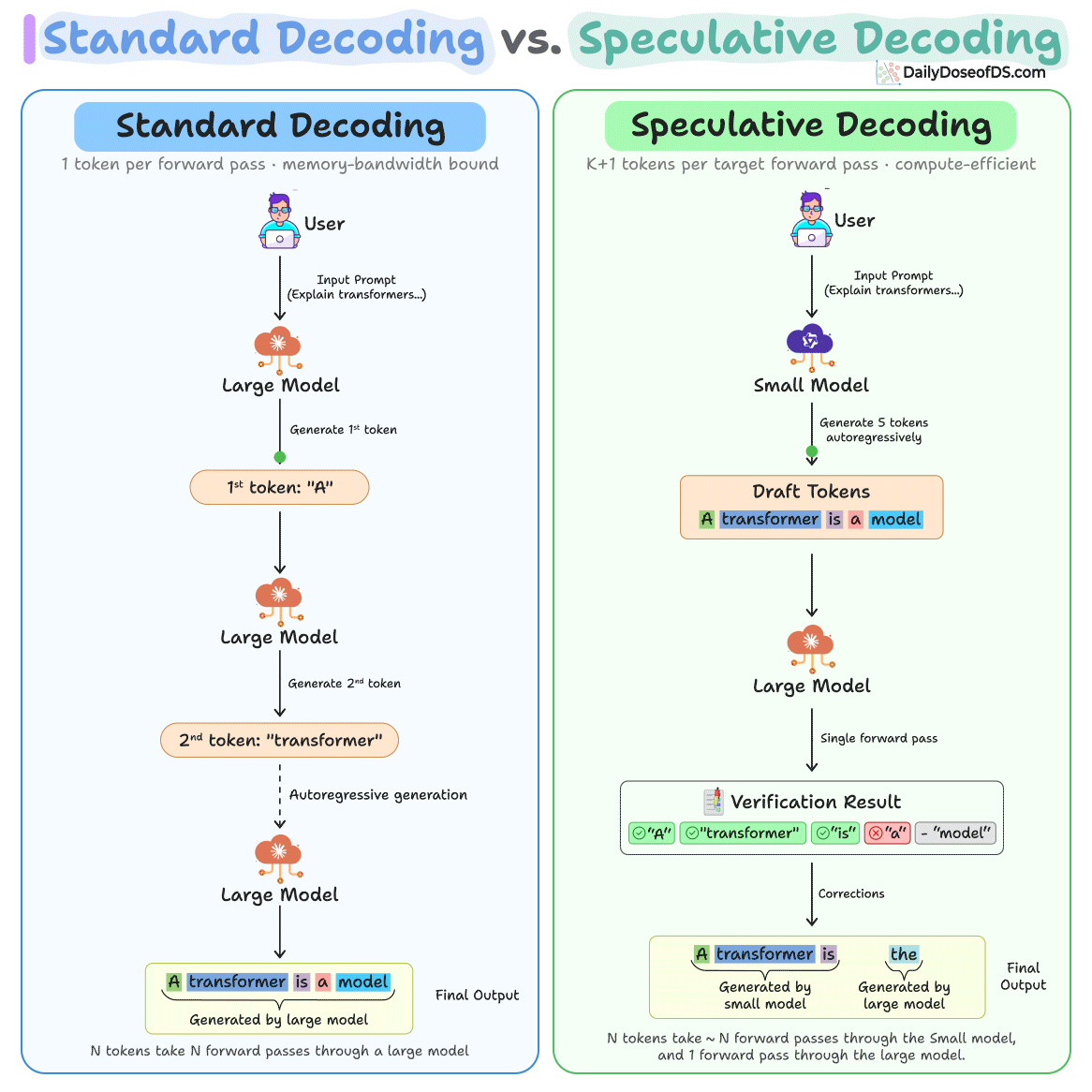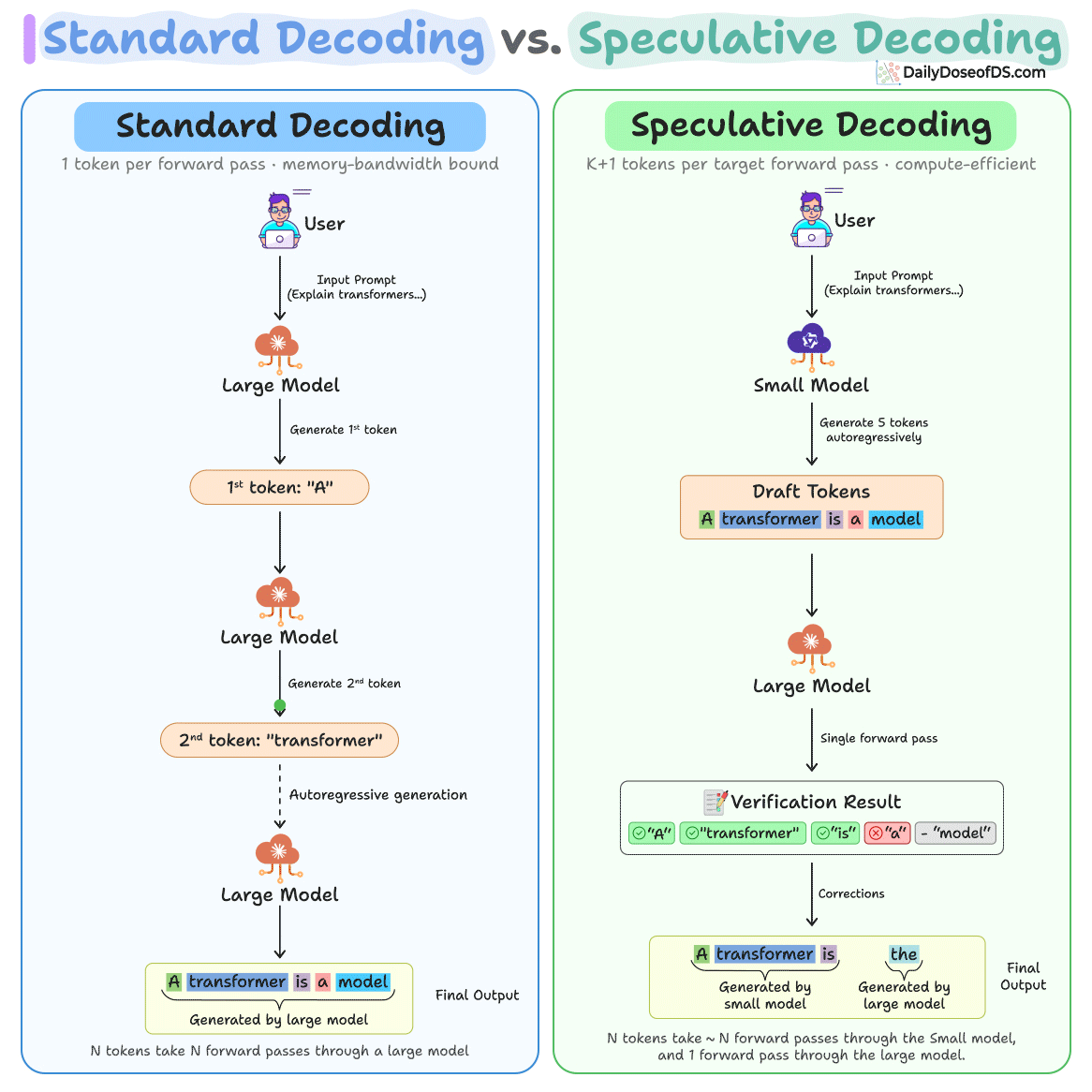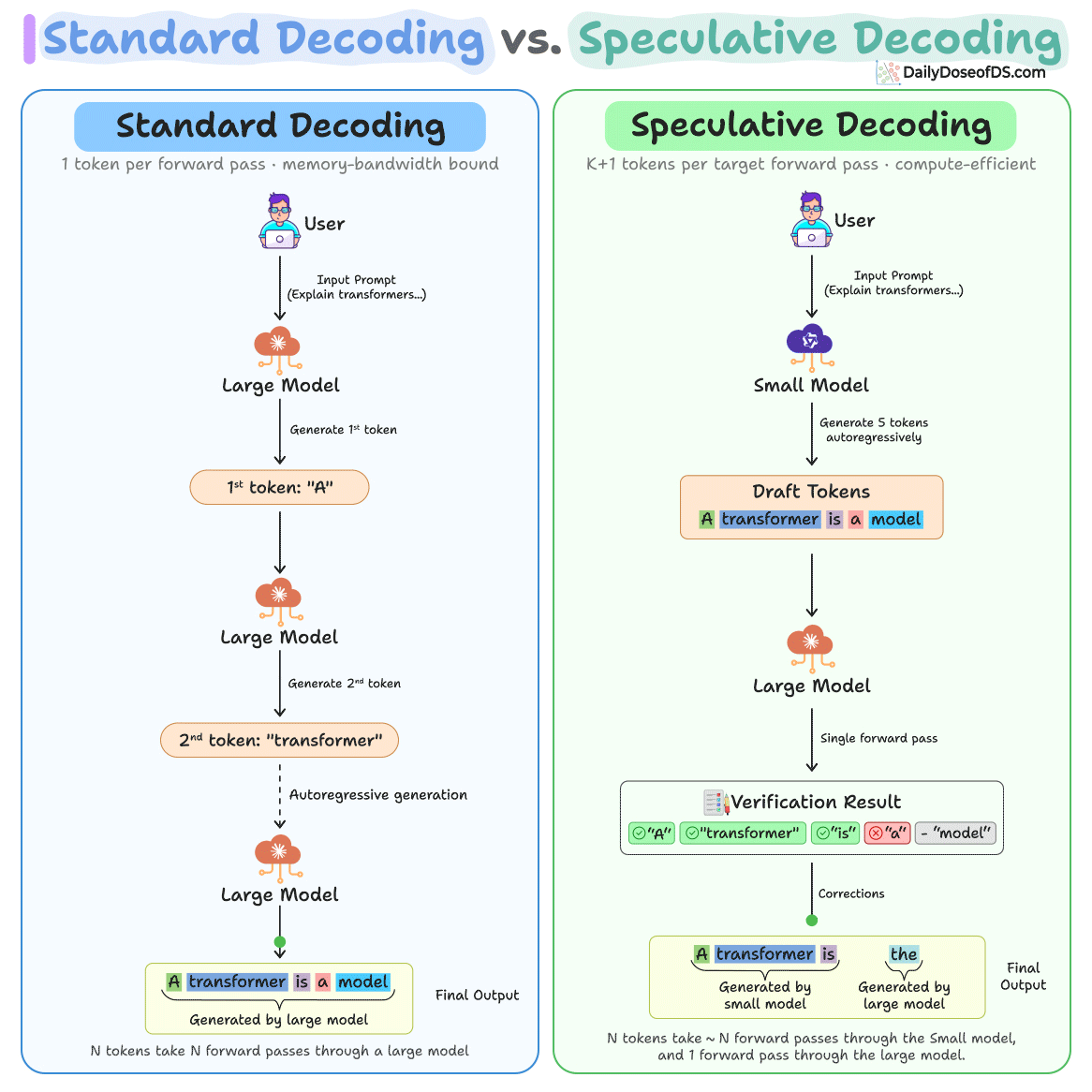
If a token at any position is wrong, you keep everything before it and restart from there. This never does worse than normal decoding.
But current drafters in Speculative decoding still guess one token at a time. That makes the drafting step itself a bottleneck, capping real-world speedups at 2-3x.
DFlash is a new technique that swaps the autoregressive drafter with a lightweight block diffusion model that guesses all tokens in one parallel shot.
Drafting cost stays flat no matter how many tokens you speculate.
On top of that, the drafter is conditioned on hidden features pulled from multiple layers of the target model and injected into every draft layer, so it makes significantly better guesses than a drafter working from scratch.
In the side-by-side demo below, vanilla decoding runs at 48.5 tokens/sec. DFlash hits 415 tokens/sec on the same model, with zero quality loss.
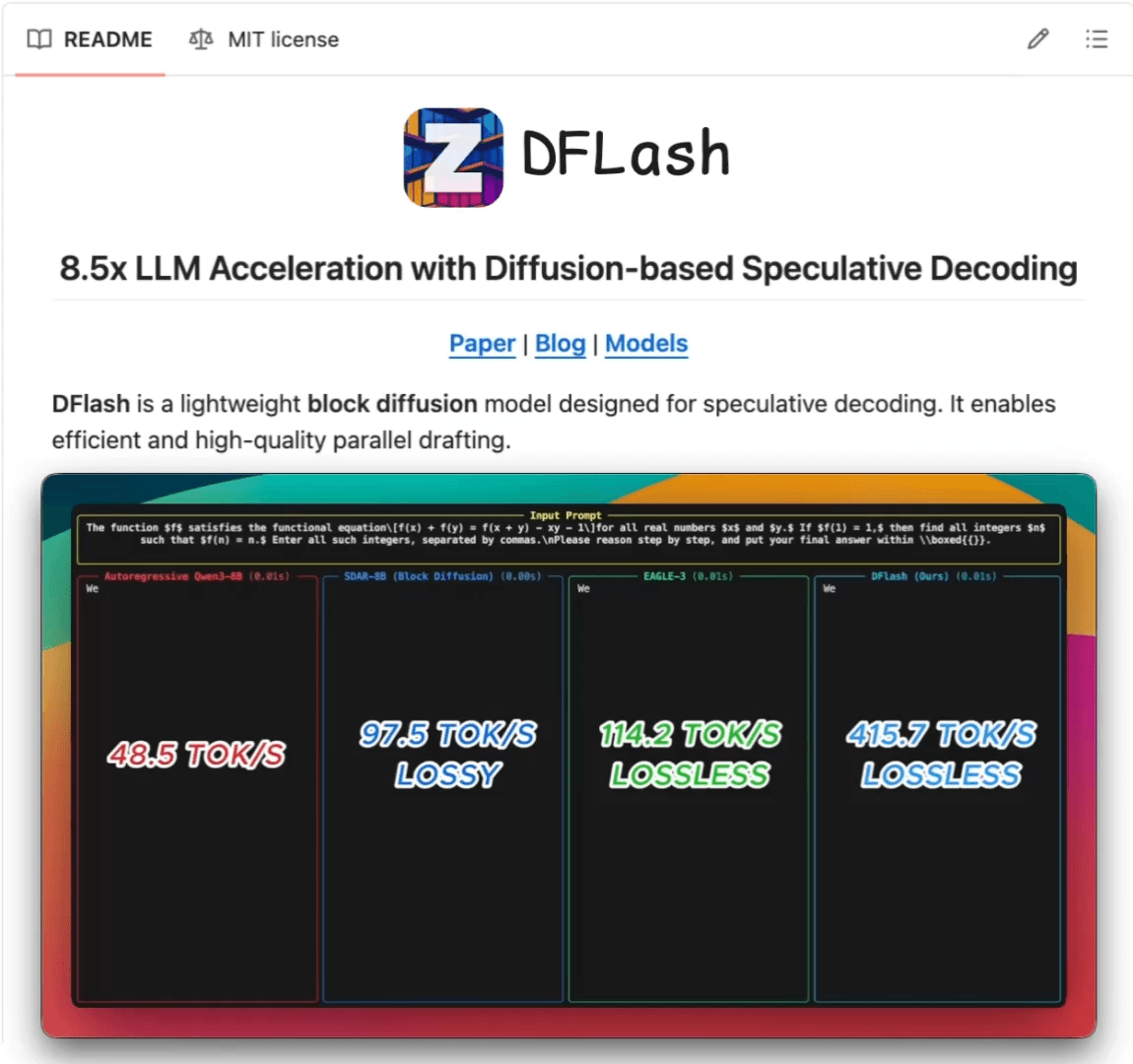
It’s already integrated with vLLM, SGLang, and Transformers, with draft models on HuggingFace for several models like Qwen3, Qwen3.5, Llama 3.1, Kimi-K2.5, gpt-oss, and many more.
To learn more about Speculative decoding, we covered it here →
You can find the GitHub repo here →
KV caching is another must-know technique to boost LLM inference. We covered it here →
👉 Over to you: What use case are you working on that can benefit from this new technique?
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.