
Researchers Solved a Decade-old Problem in Object Detection
...explained visually.

Your AI Engineering Hub [open-source]
We open-sourced the AI Engineering Hub 1 year ago!
Today we’ve hit 30k stars on GitHub! 🌟
It has 90+ hands-on projects covering:
RAG
MCP
AI Agents
Finetuning
AI Memory
Eval and Observability
LLMOps/Optimisations
And more...
Here’s the GitHub repo → (don’t forget to star it ⭐️)
Researchers solved a decade-old problem in object detection
From the outside, object detection looks simple.
You give the model an image, and it gives you boxes around objects.
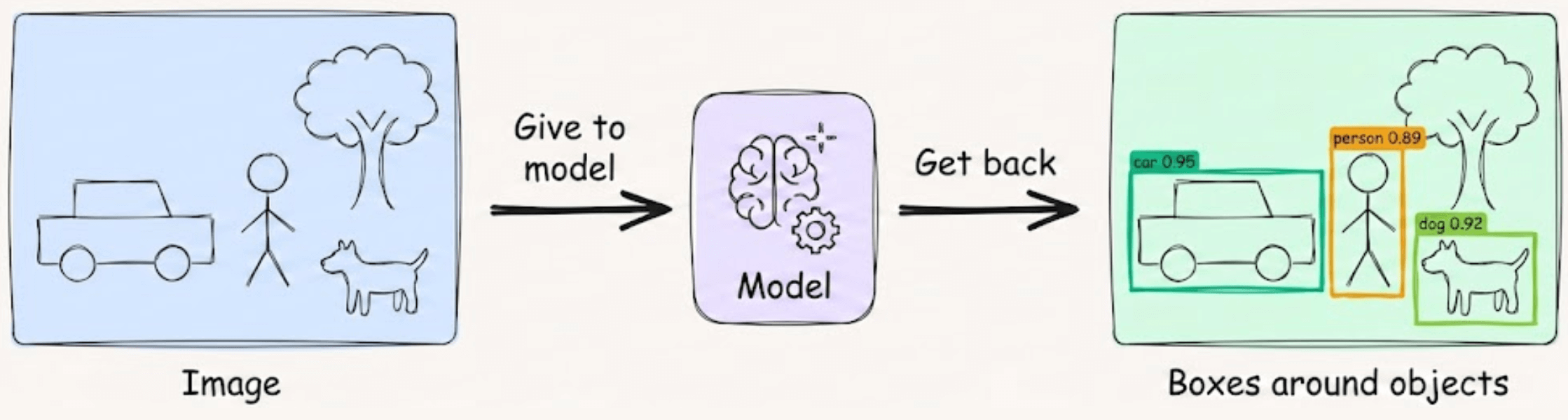
But the process in between is where things get interesting.
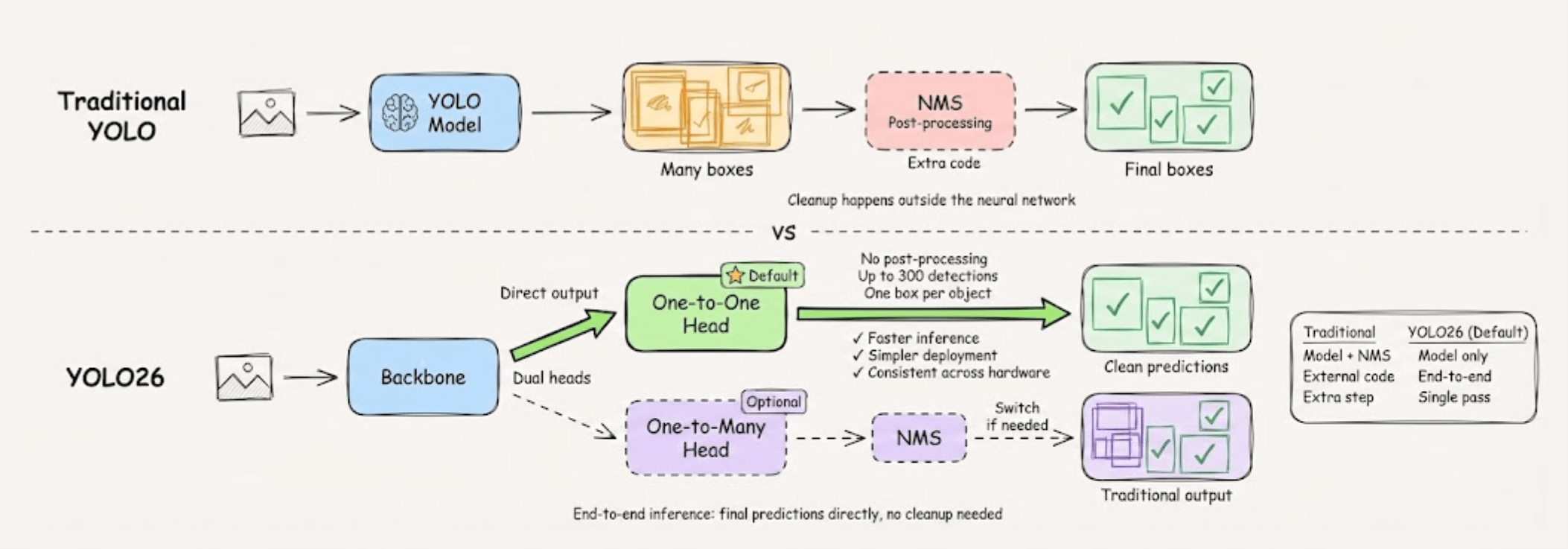
In traditional YOLO, the model generates multiple boxes for each object it finds.
A car might get 10 boxes, a person might get 15. This seems wasteful, but having multiple predictions helps the model learn better patterns during training.
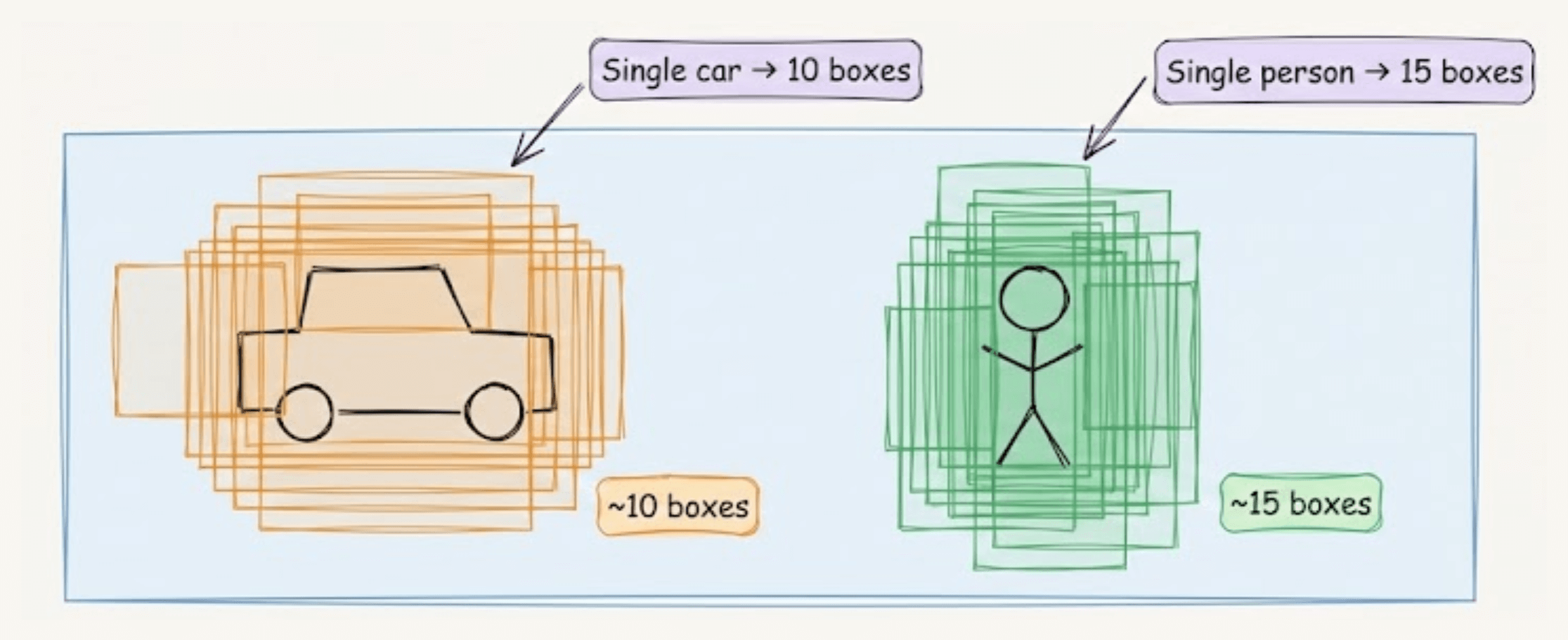
That said, inference time still needs one box per object.
So after the model finishes predicting, a separate cleanup step called Non-Maximum Suppression (NMS) filters through all those boxes and keeps only the best ones.
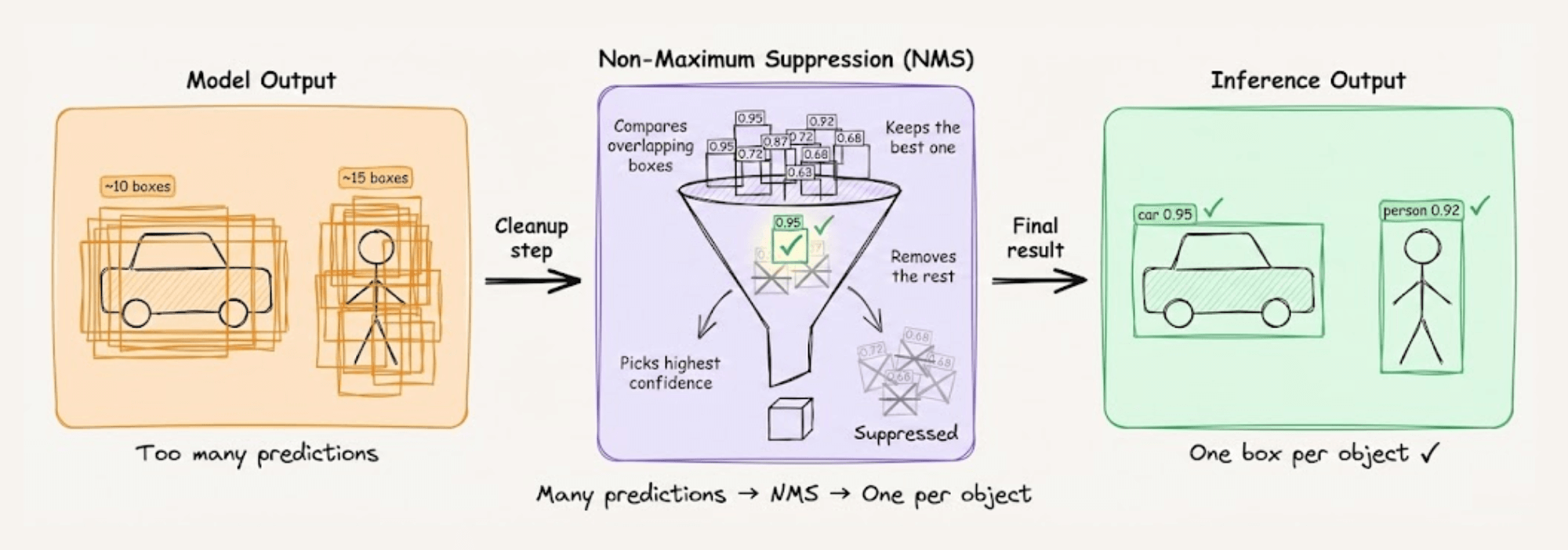
The problem here is that the cleanup step happens outside the neural network, so it’s extra code that runs after the model is done.
What if you could skip that cleanup step entirely?
That’s what end-to-end inference does.
Ultralytics YOLO26 uses this approach to produce final predictions directly in a single pass, with no separate post-processing required.
The visual below depicts how it differs from traditional YOLO:

It uses a dual-head architecture with two modes: a one-to-one head that outputs clean predictions by default, and a one-to-many head for traditional NMS-based processing if needed.
Here’s what the default mode means in practice:
Up to 300 detections per image with one box per object
No filtering or post-processing step required
Faster inference and simpler deployment pipelines
Consistent behavior across different hardware platforms
You can always switch to the one-to-many head with NMS if your application requires it.
Beyond faster inference, the end-to-end design changes how models deploy.
The model’s output is final and predictable. You don’t need to port cleanup logic across platforms or tune thresholds for different scenarios.
This makes integration simpler across edge and low-power devices.
This approach solves the training-versus-deployment tradeoff that has existed in object detection for years.
You can try YOLO26 now on the Ultralytics Platform here →
It’s open-source under AGPL for research, with enterprise licensing for commercial use.
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.