
RLHF: Aligning Language Models with Human Feedback
The full RL nanodegree, covered with implementation.

Part 9 of the Reinforcement Learning course is available now.
It covers RHLF, and this is the chapter where everything we have built across the series (value functions, policy gradients, actor-critic, PPO) converges into the actual pipeline used to align language models like ChatGPT, Claude, and Gemini.
You can read Part 9 of the course here →
It covers:
Limitations of instruction fine-tuning
Turning human comparisons into reward
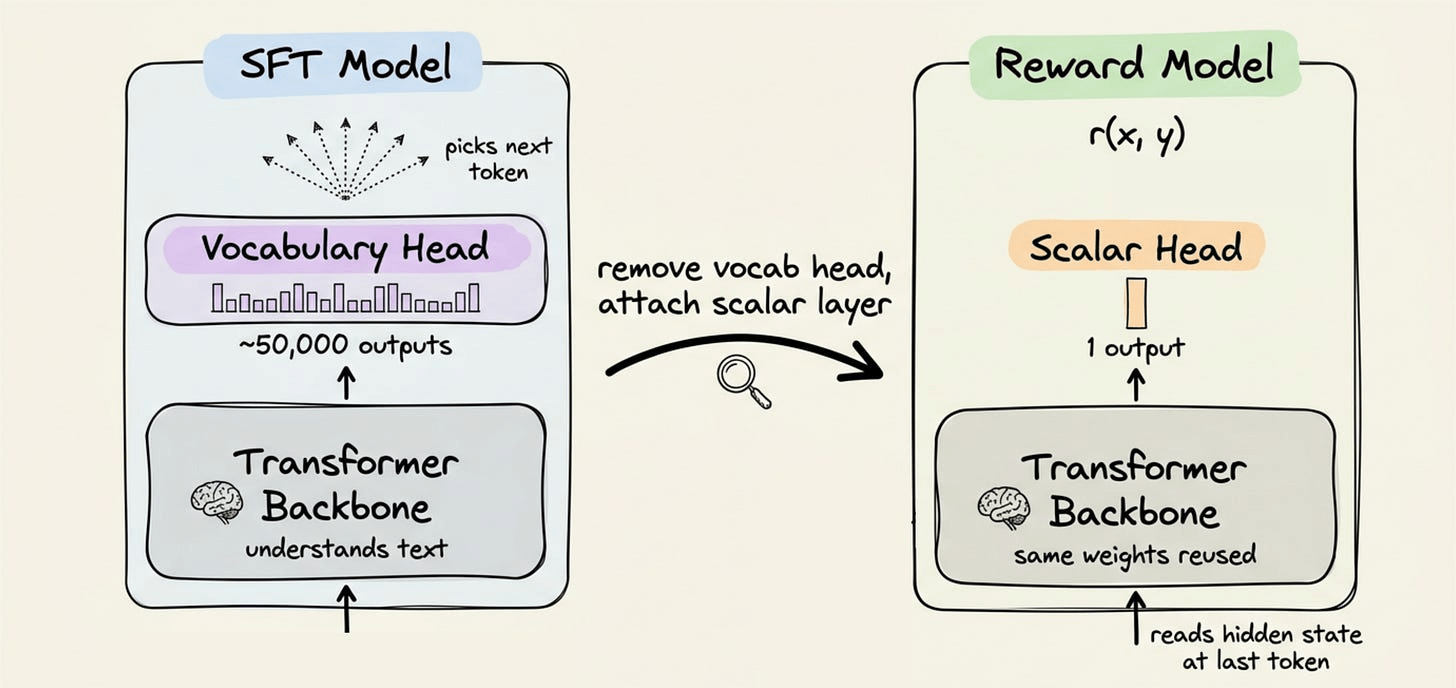
Training the reward model
The four-model RLHF setup
Keeping the model from drifting
Reward hacking and over-optimization
Hands-on reward model training
DPO as a simpler alternative
When verifiable rewards work better
Everything is covered from scratch, so no RL background is required.
You can read Part 9 of the course here →
Why care?
RLHF is one key reason why modern language models feel different from the GPT-2 era.
Pre-training gives a model knowledge. Supervised fine-tuning teaches it the format of a conversation.
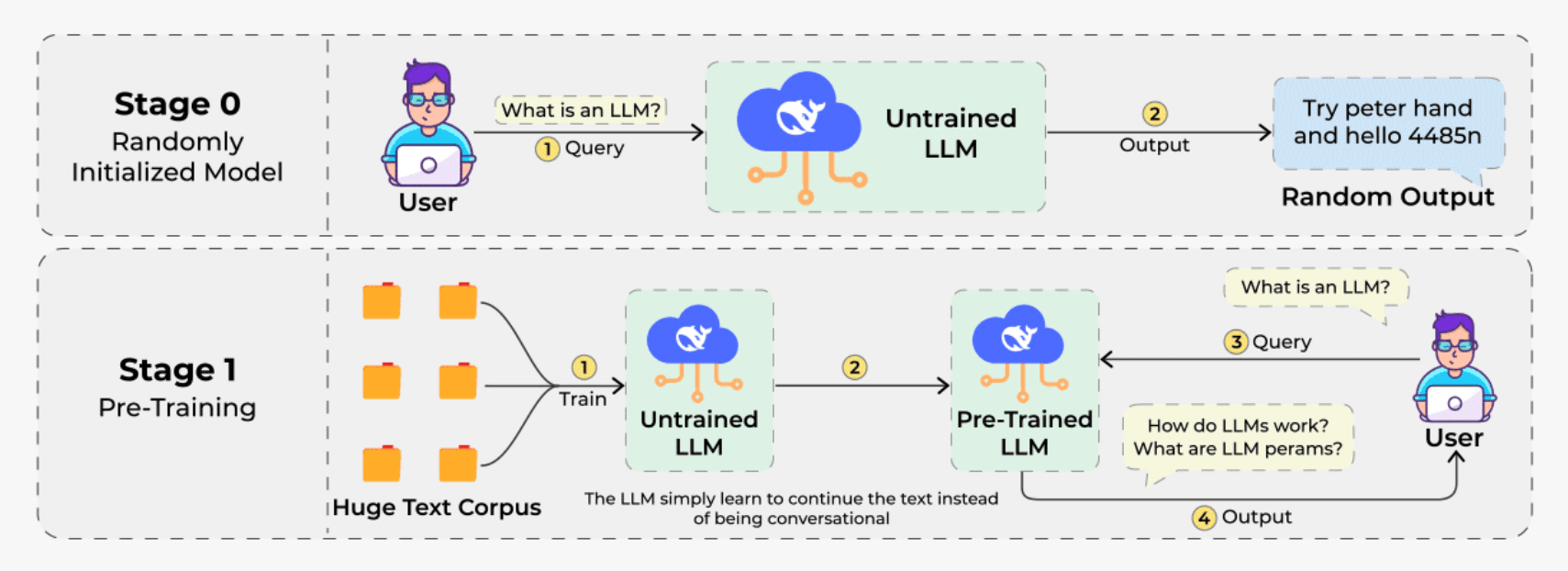
But the step that turns a text-completion engine into something that follows instructions, avoids harmful outputs, and responds in a way that feels genuinely useful is RLHF.
Every major model release over the past three years has included some version of this pipeline.
Understanding RLHF also makes the ongoing alignment conversation far more concrete and helps understand reward hacking, over-optimization, sycophancy, length bias.
This series has been building toward this chapter from the start.
Here’s what we have covered so far:
Just like the MLOps course, each chapter will clearly explain necessary concepts, provide examples, diagrams, and implementations.
👉 Over to you: What topics would you like us to cover in this RL series?
Good day!