
Scale ML Models to Billions of Parameters
...with 4 simple changes to your PyTorch code.

In today's newsletter:
A framework-agnostic Backend for your AI Agents.
From PyTorch to PyTorch Fabric.
Label Smoothing for ML models.
A framework-agnostic Backend for your AI Agents

xpander is a plug-and-play Backend for agents that manages memory, tools, multi-user states, events, guardrails, and more.
Once you deploy your Agent, it provides various triggering options like MCP, A2A, API, Web interfaces, etc.
Works with LlamaIndex, Langchain, CrewAI, Google ADK—you name it.
GitHub repo → (don’t forget to star it)
From PyTorch to PyTorch Fabric
PyTorch gives so much flexibility and control. But it leads to a ton of boilerplate code.
PyTorch Lightning lets you massively reduce the boilerplate code, and it allows us to use distributed training features like DDP, FSDP, DeepSpeed, mixed precision training, and more, by directly specifying parameters:

But it isn’t as flexible as PyTorch to write manual training loops, etc.
Lately, we have been using Lightning Fabric, which brings together:
The flexibility of PyTorch.
And distributed training features that PyTorch Lightning provides.
You only need to make 4 minor changes to your existing PyTorch code to easily scale it to the largest billion-parameter models/LLMs.
All this is summarized below:

First, create a Fabric object and launch it:

While creating the Fabric object above, you can specify:
the accelerator and the number of devices
the parallelism strategy to use
the floating point precision, etc.
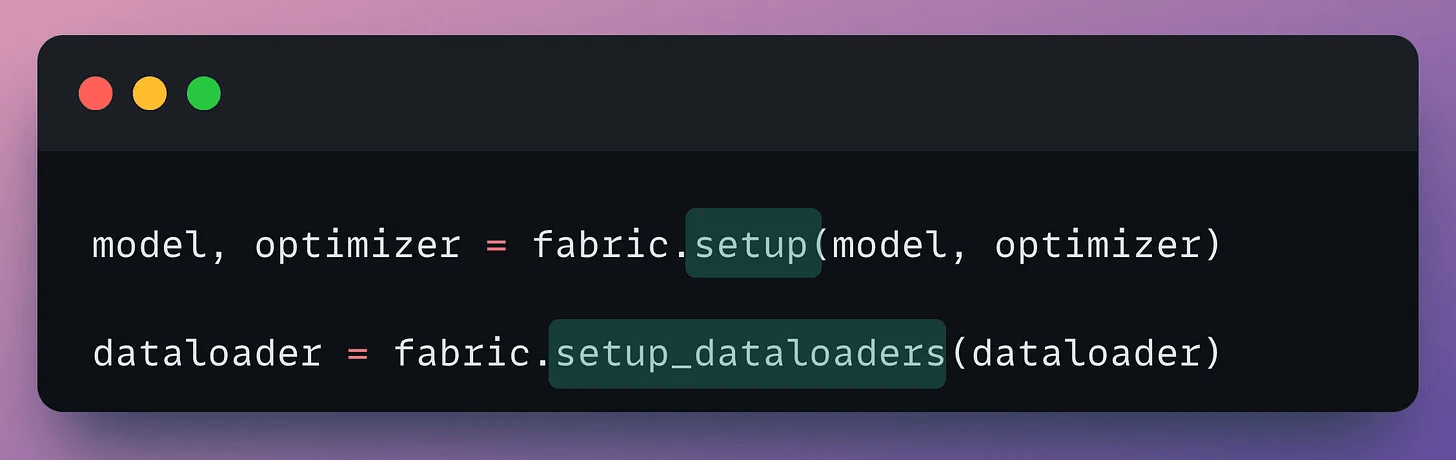
Next, configure the model, the optimizer, and the dataloader:
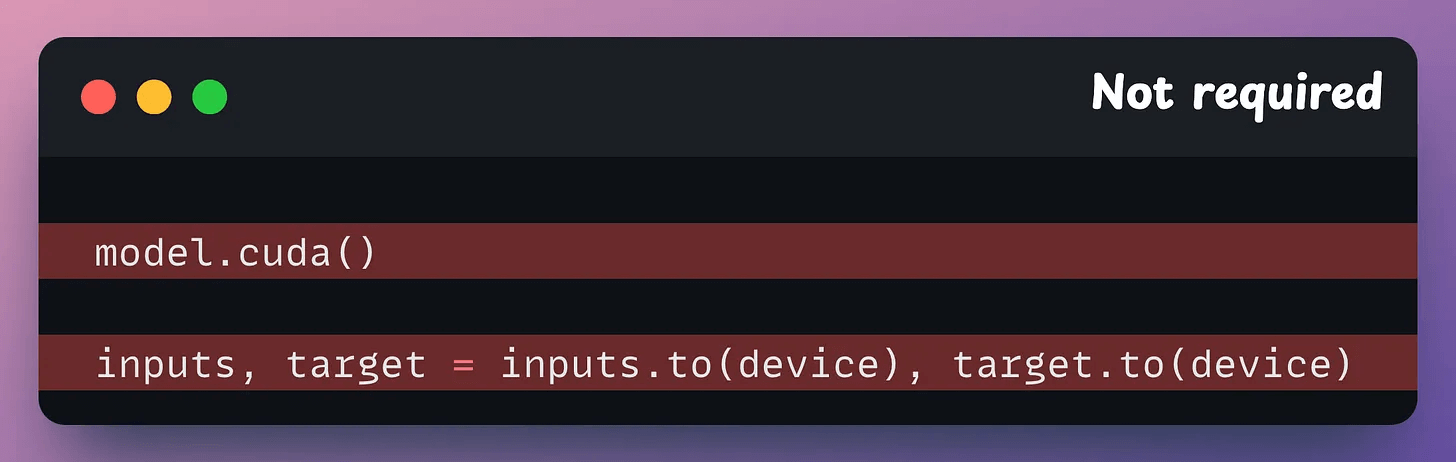
Next, you can remove all .to() and .cuda() calls since Fabric takes care of it automatically:
Finally, replace loss.backward() with fabric.backward(loss):

Done!
Now, you can train the model as you usually would.
These 4 simple steps allow you to:
Easily switch from running on CPU to GPU (Apple Silicon, CUDA, …), TPU, multi-GPU or even multi-node training
Use state-of-the-art distributed training strategies (DDP, FSDP, DeepSpeed) and mixed precision out of the box
Moreover, you can also build your own custom Trainer using Fabric for training checkpointing, logging, and more.
👉 Over to you: What are some issues with PyTorch?
Label Smoothing for ML models
In typical classification problems, the entire probability mass belongs to just one class, and the rest are zero:

This can sometimes impact its generalization capabilities since it can excessively motivate the model to learn the true class for every sample.
Regularising with Label smoothing addresses this issue by reducing the probability mass of the true class and distributing it to other classes:

In the experiment below, I trained two neural networks with the same weight initialization.
One without label smoothing.
Another with label smoothing.

The model with label smoothing (right) resulted in better test accuracy, i.e., better generalization.
When not to use label smoothing?
Label smoothing is recommended only if you only care about getting the final prediction correct.
But don't use it if you also care about the model’s confidence, since label smoothing directs the model to become “less overconfident” in its predictions, resulting in a drop in the confidence values for every prediction:

That said, L2 regularization is another common way to regularize models. Here’s a guide that explains its probabilistic origin: The Probabilistic Origin of Regularization.
And we covered 11 techniques to supercharge ML models here (with code)→
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.