
Schema Guided Agent Memory for Production Agents
Some key lessons on building production-grade memory for Agents.

The less your model thinks, the better it codes.
The entire reasoning model space has been moving in one direction, emphasizing more thinking tokens, longer chains, and bigger reasoning budgets.
Kimi just challenged that.
K2.7 Code scores higher than K2.6 on every coding benchmark while using 30% fewer thinking tokens, at the same price.
Most thinking models apply the same reasoning depth to every task. A simple bug fix triggers the same deliberation loop as a complex architecture decision. The model isn’t being thorough but rather overthinking.
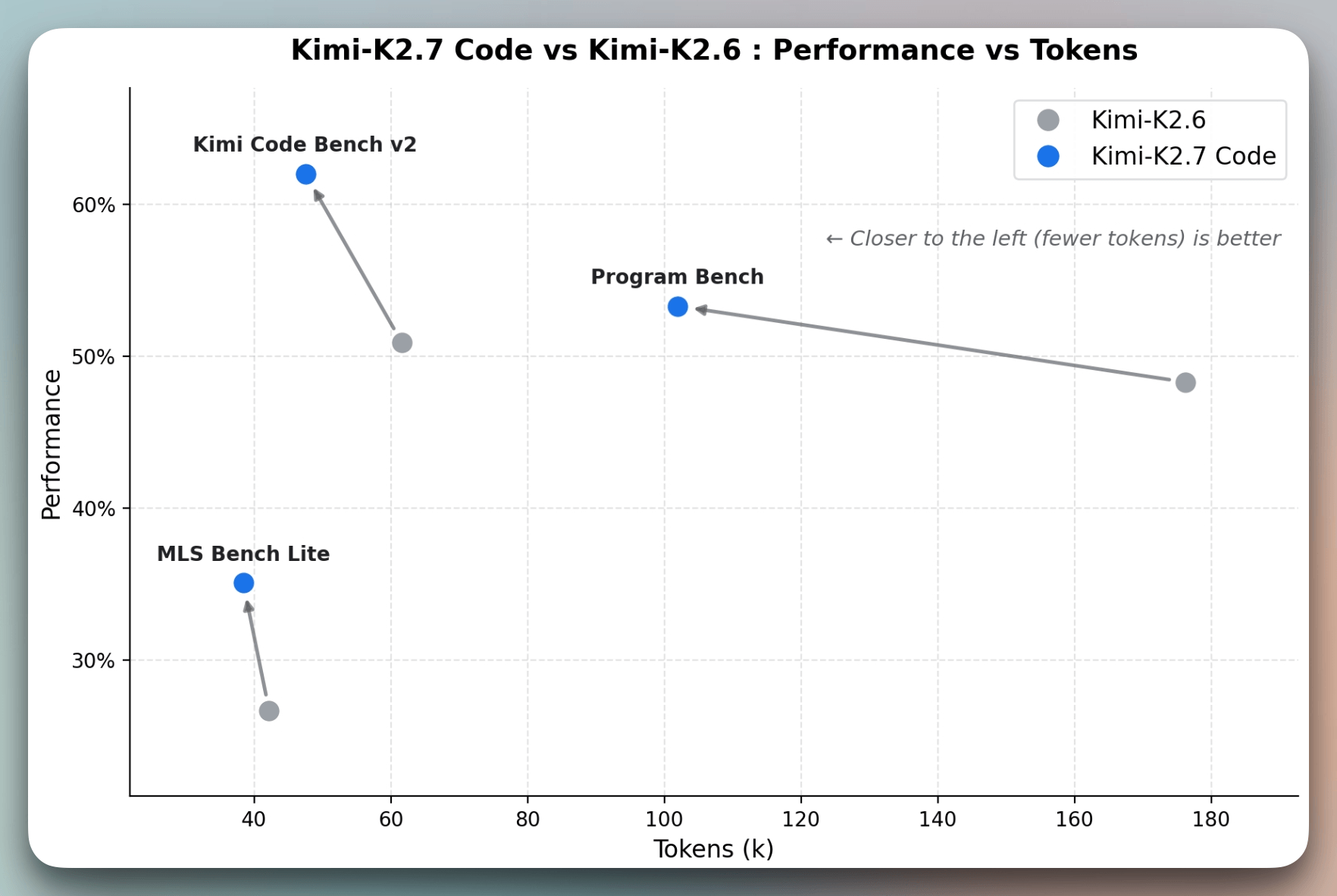
K2.7 targets this specifically. Here’s what changed vs K2.6:
+21.8% on Kimi Code Bench v2
+11.0% on Program Bench
+31.5% on MLS Bench Lite
All with 30% fewer thinking tokens.
You can find the model on HuggingFace here →
Schema-guided Agent Memory
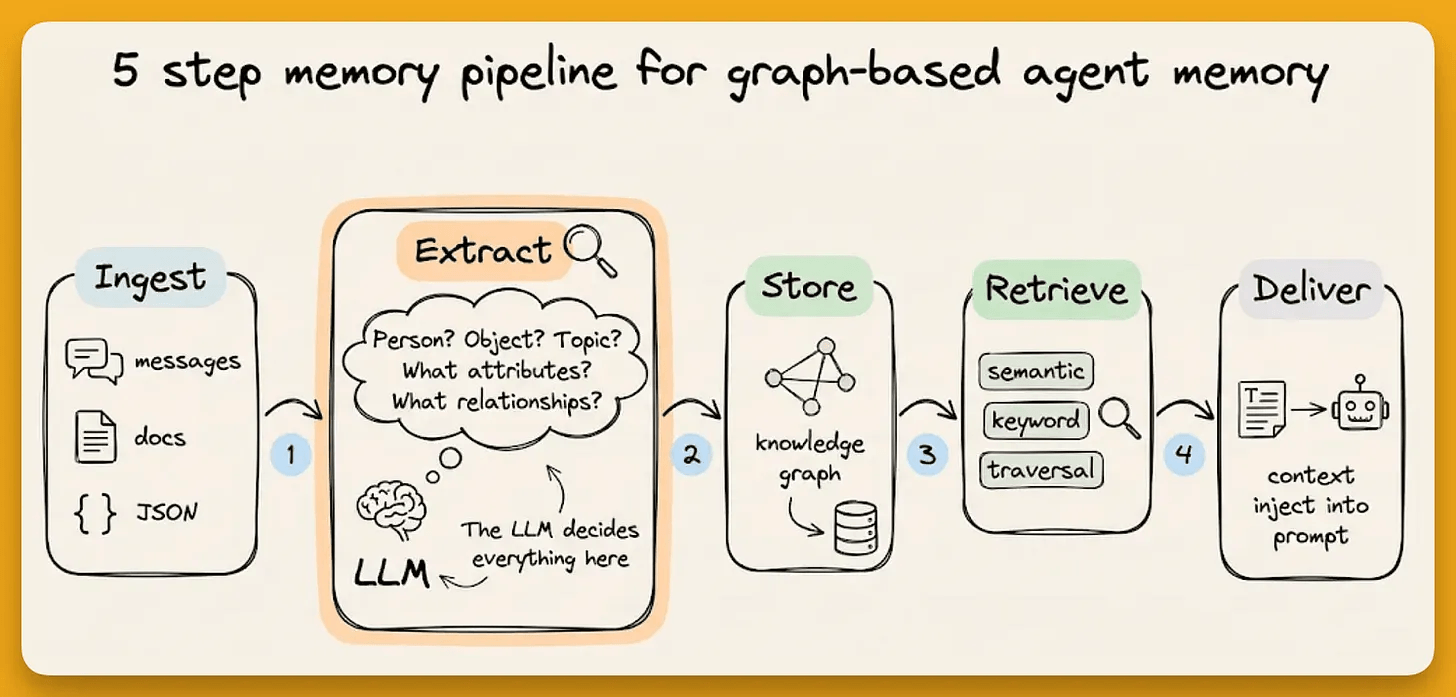
Most agent memory systems optimize for recall. The harder problem is what to forget, or more precisely, what to never store in the first place.
The default agent memory pipeline hands an LLM raw text and asks it to extract entities and relationships. The model decides the types, labels, and attributes all on its own.
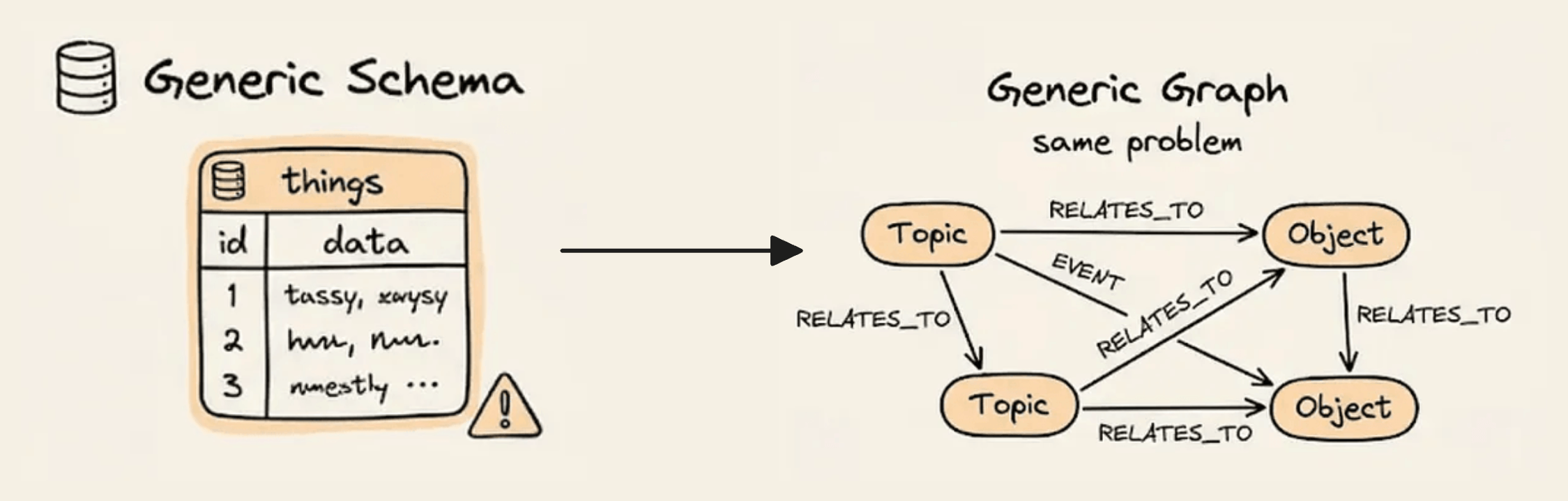
The result is a knowledge graph that behaves like an expensive vector store. Entity types collapse into generic labels. Relationships flatten into a single “RELATES_TO.”
The graph has the data, but no query can reach it with precision.
This is not a retrieval problem but rather a structure problem. And the fix is the same pattern that already works everywhere else in the AI stack, i.e., constrain the output space before generation, not after.
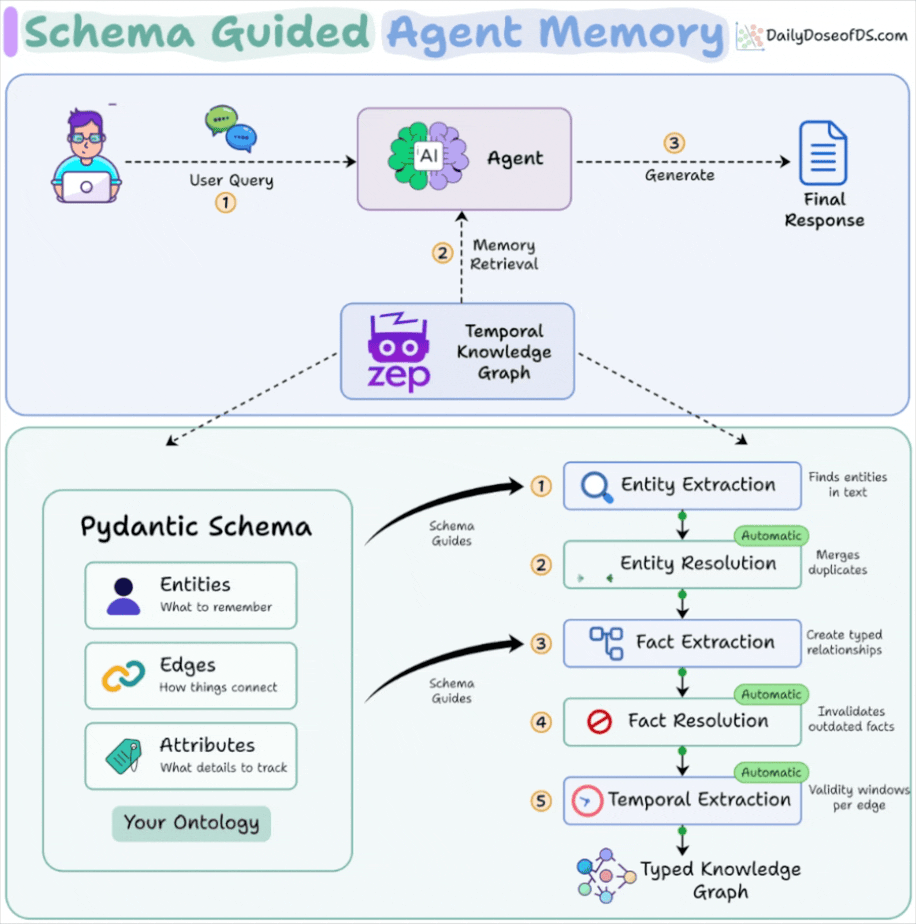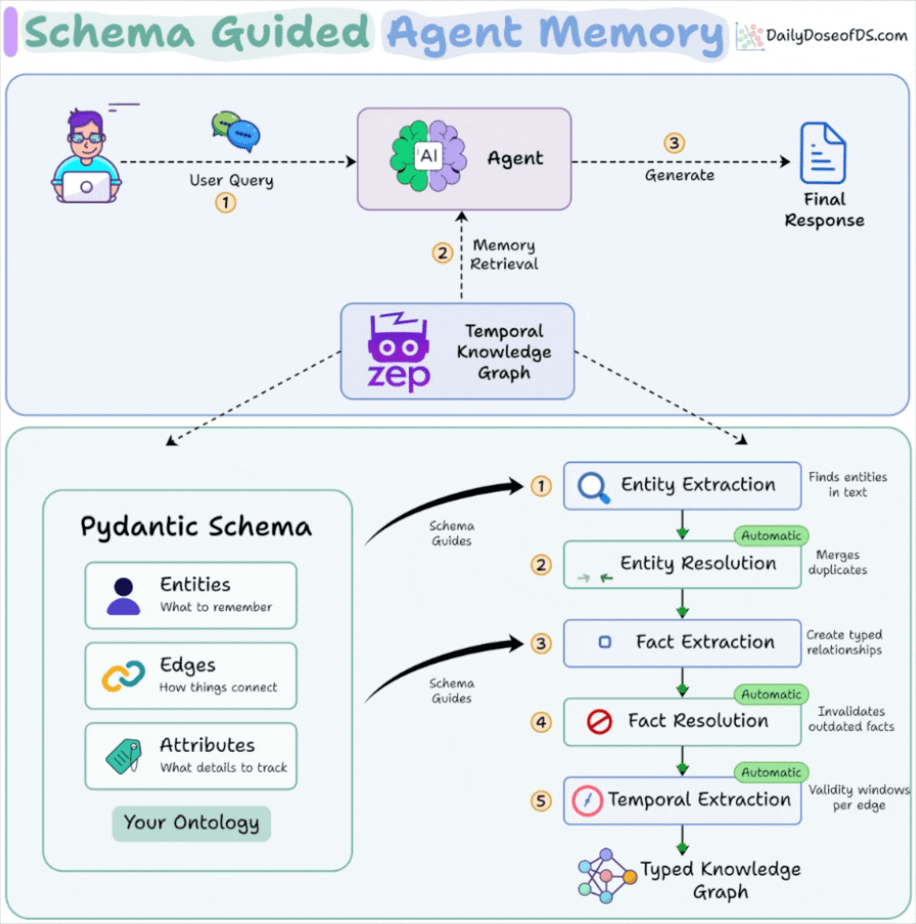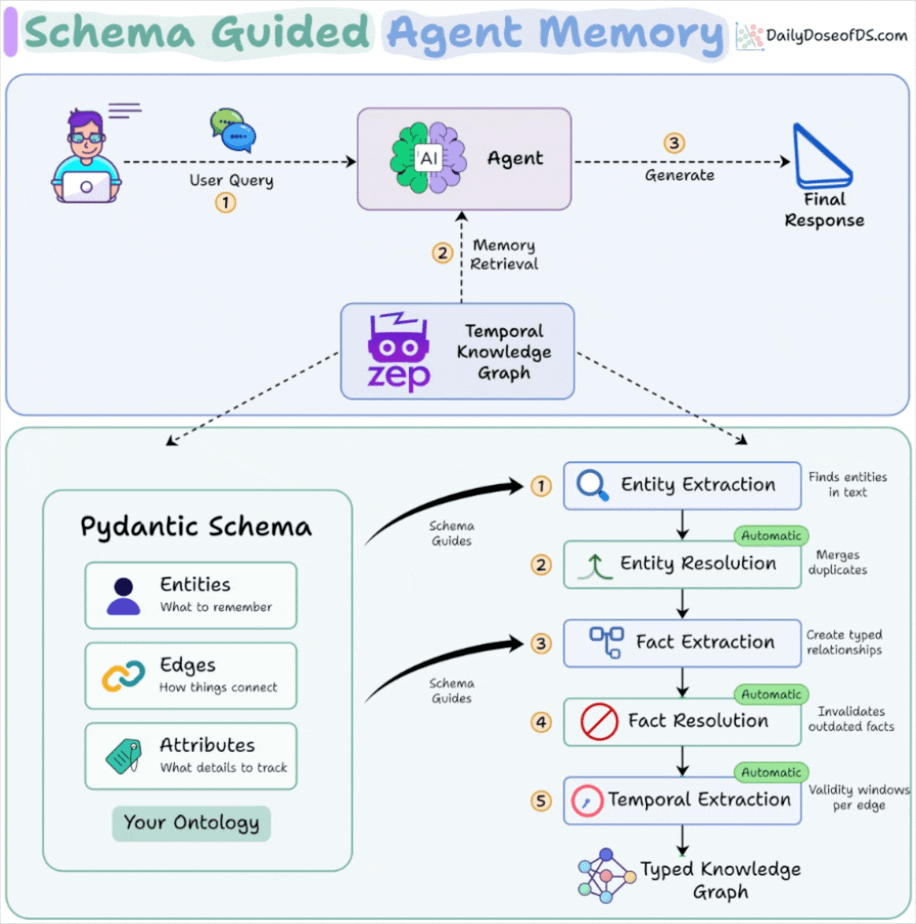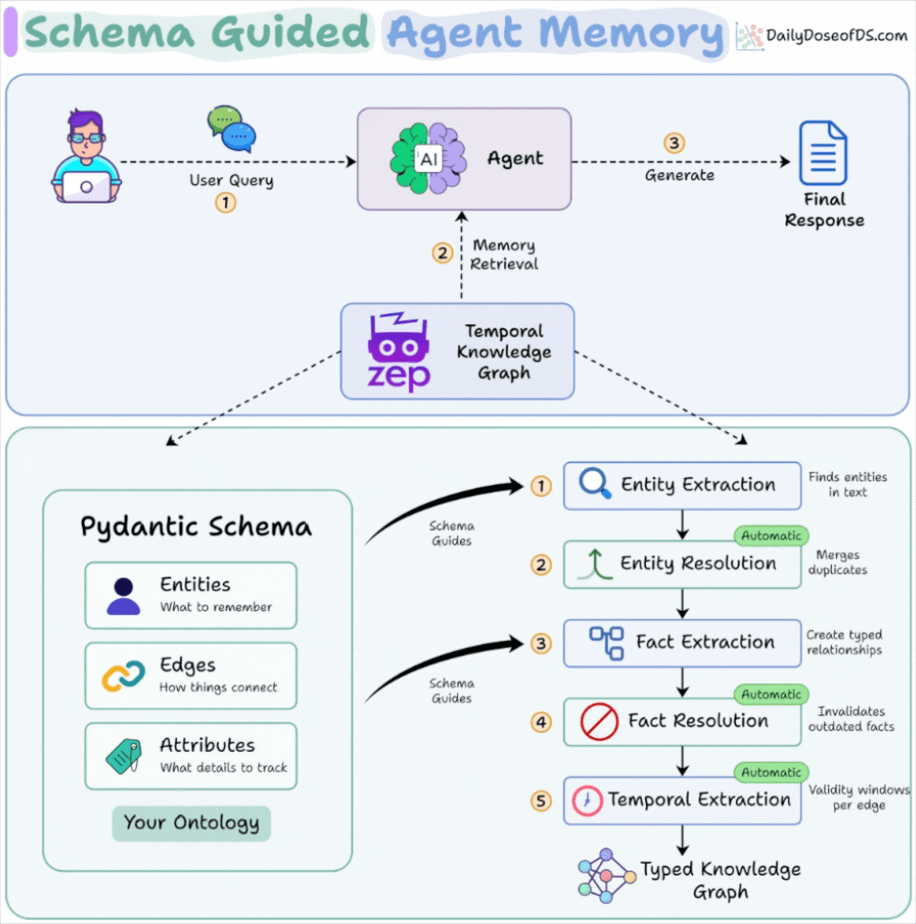
Entities define what the agent is allowed to remember. Pydantic models with typed fields and descriptive docstrings replace the LLM’s guesswork with domain vocabulary it was never trained on.
Edges define how things connect. Source/target constraints on relationship types mean the graph can only form valid connections. If your schema has no edge connecting Project to Competitor, that relationship cannot exist in memory.
Temporal resolution handles what was true versus what is true. Fact resolution invalidates outdated edges while preserving history, so the graph never silently serves a stale state.
The schema guides extraction at two points in the pipeline (entity extraction and fact extraction) while resolution and temporal processing run automatically downstream.
You define what to look for. The system handles deduplication, contradiction detection, and time-windowing without additional configuration.
A useful constraint is to have just 10 entity types, 10 edge types, and 10 fields per type.
That forces you to model the 80% that matters rather than attempting completeness. Start with 3-4 of each and expand only when retrieval fails.
Zep Graphiti does all of this as a fully open-source temporal knowledge graph library.

It includes Pydantic-based ontology definition, schema-guided extraction, entity resolution, fact resolution, and temporal windowing.
If you are building agent memory with any kind of domain specificity, schemas are a must.
(don’t forget to star 🌟)
We also covered this topic in more depth (with code) in this article →
Thanks for reading!
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) that align with such topics.
Here are some of them:
Learn everything about MCPs in this crash course with 9 parts →
Learn how to build Agentic systems in a crash course with 14 parts.
Learn how to build real-world RAG apps and evaluate and scale them in this crash course.

Learn sophisticated graph architectures and how to train them on graph data.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here.
Learn how to run large models on small devices using Quantization techniques.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust using Conformal Predictions.
Learn how to identify causal relationships and answer business questions using causal inference in this crash course.
Learn how to scale and implement ML model training in this practical guide.
Learn techniques to reliably test new models in production.
Learn how to build privacy-first ML systems using Federated Learning.
Learn 6 techniques with implementation to compress ML models.
All these resources will help you cultivate key skills that businesses and companies care about the most.