
Should you gather more data?
More data may not always help.

AI isn’t magic. It’s math.

Understand the concepts powering technology like ChatGPT in minutes a day with Brilliant. Thousands of quick, hands-on lessons in AI, programming, logic, data science, and more make it easy. Level up fast with:
Bite-sized, interactive lessons that make complex AI concepts accessible and engaging
Personalized learning paths and competitive features to keep you motivated and on track
Building skills to tackle real-world problems—not just memorizing information
Join over 10M people and try it free for 30 days. Plus, Daily Dose of Data Science readers can snag a special discount on an annual premium subscription with this link.
Thanks to Brilliant for partnering today!
Should you gather more data?
At times, no matter how much you try, the model performance barely improves:
Feature engineering is giving marginal improvement.
Trying different models does not produce satisfactory results either.
and more…
This is usually (not always) an indicator that we don’t have enough data to work with.

But since gathering new data can be a time-consuming and tedious process...
...here's a technique I have often used to determine whether more data will help:
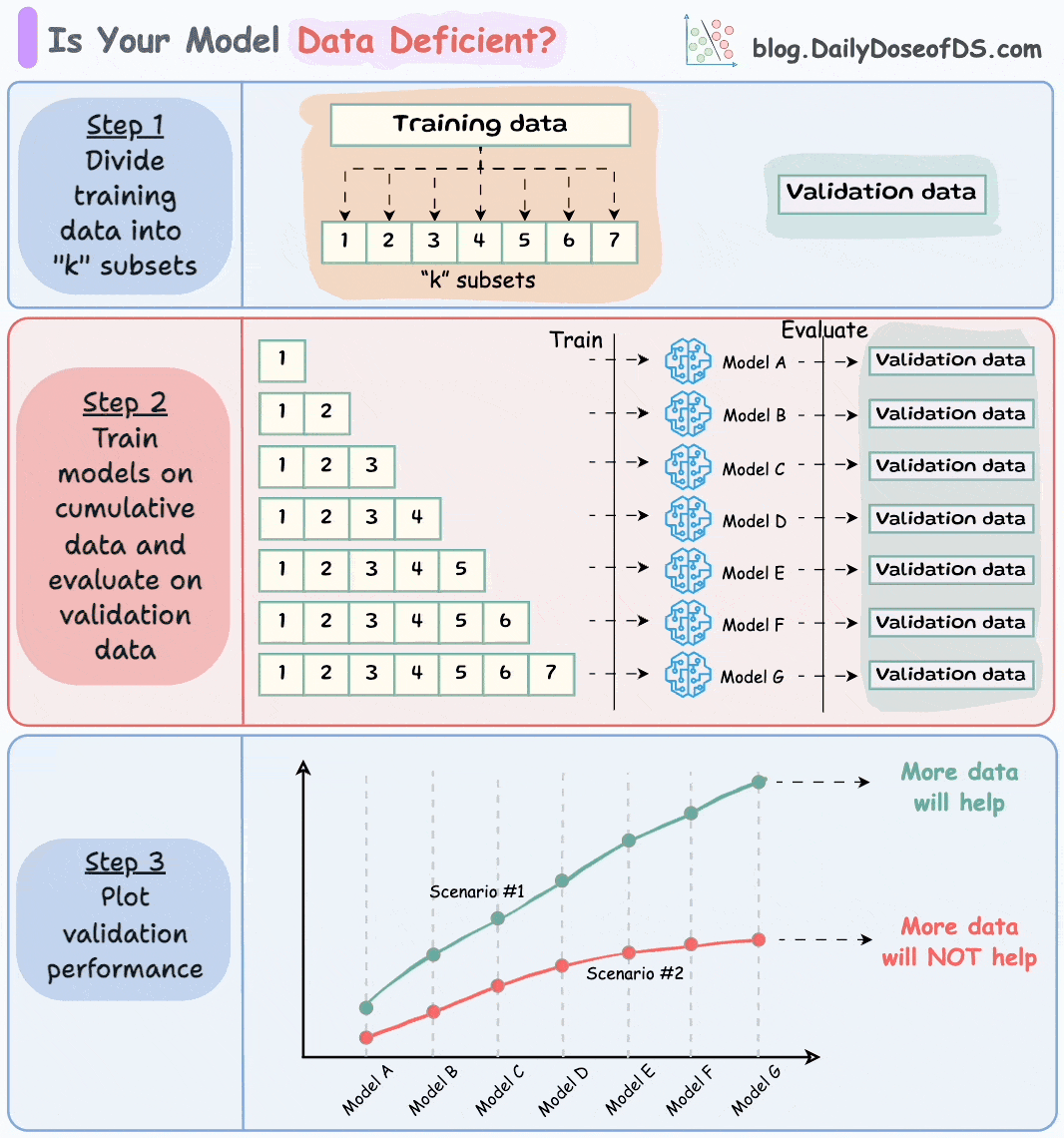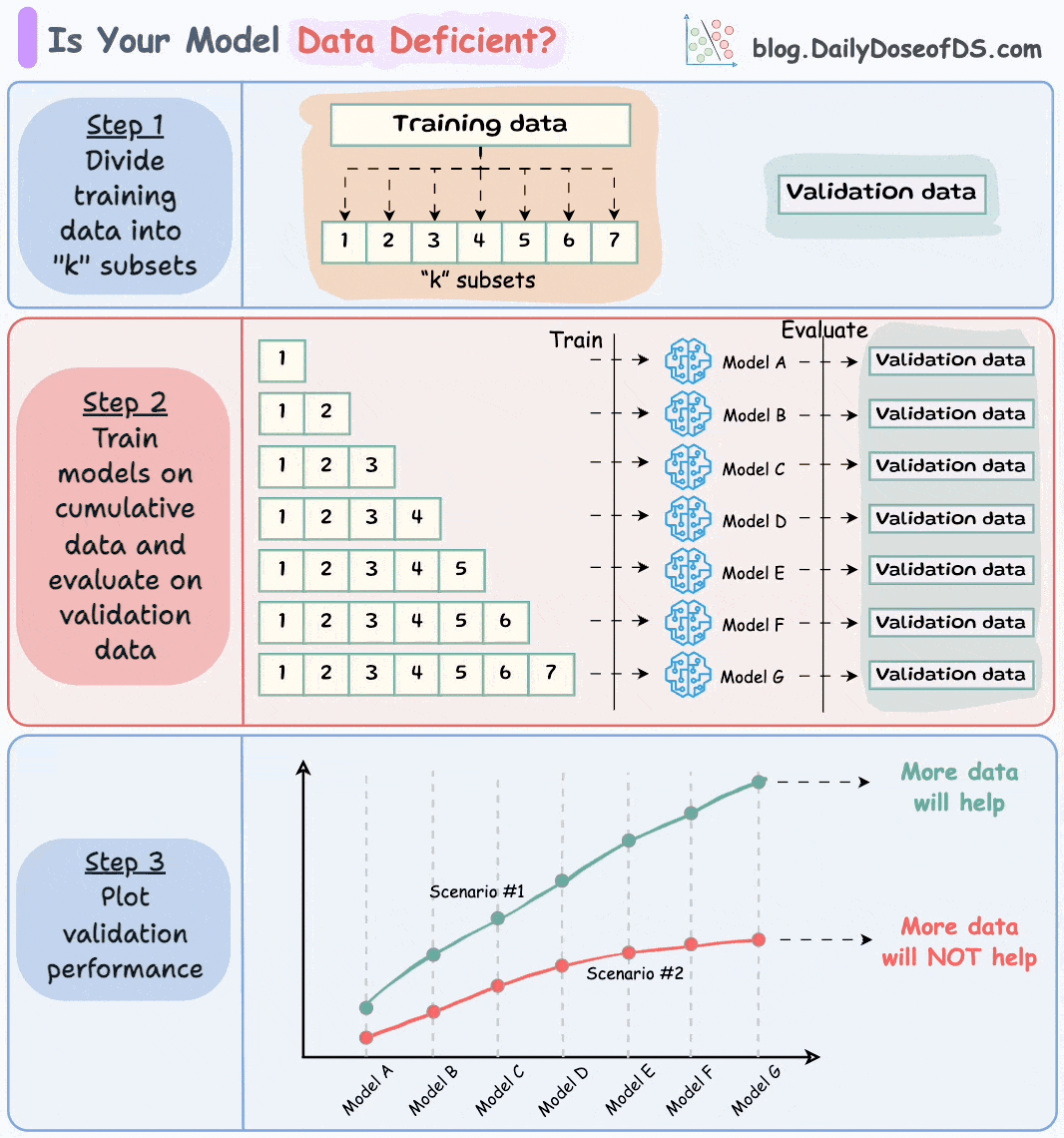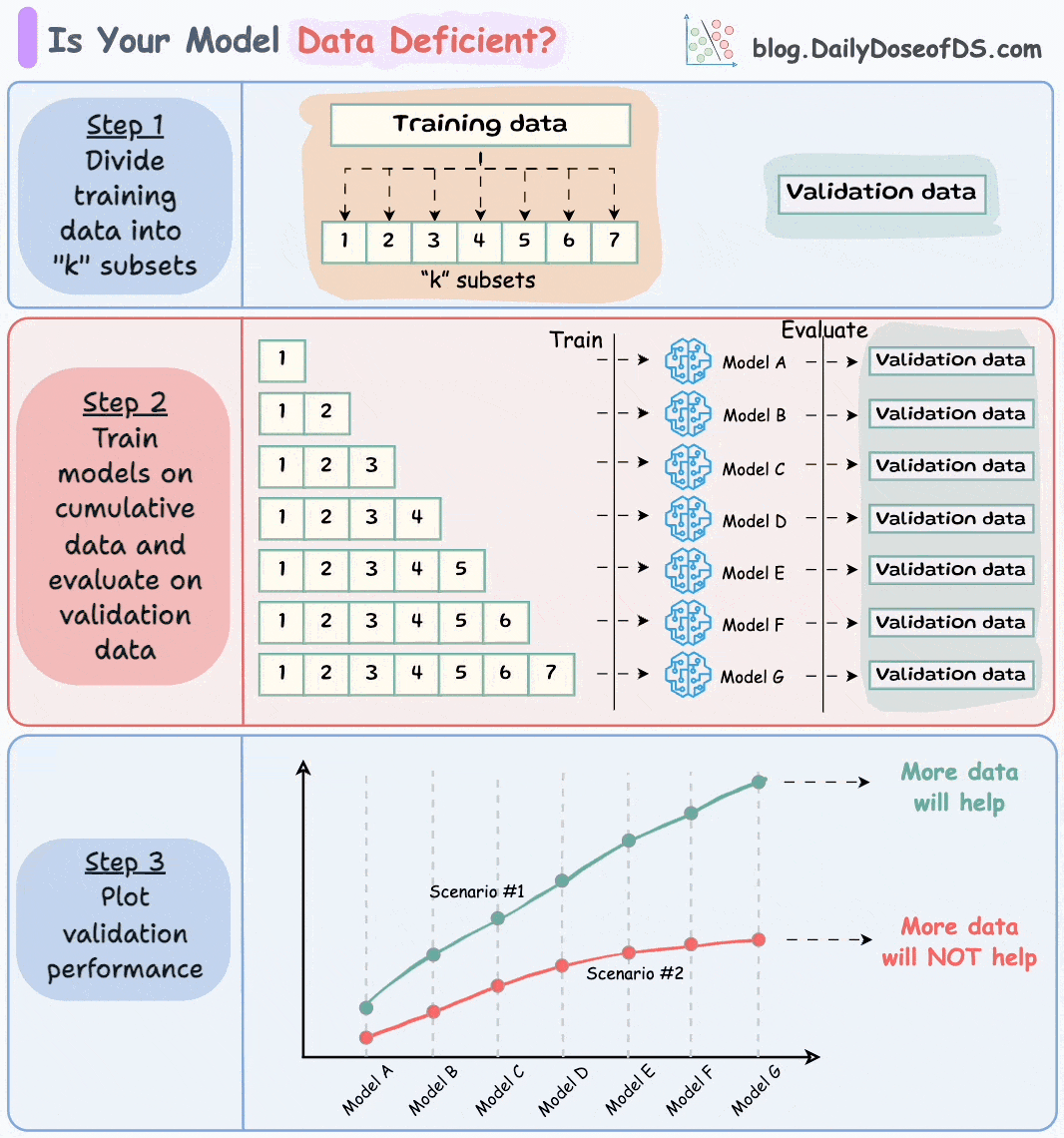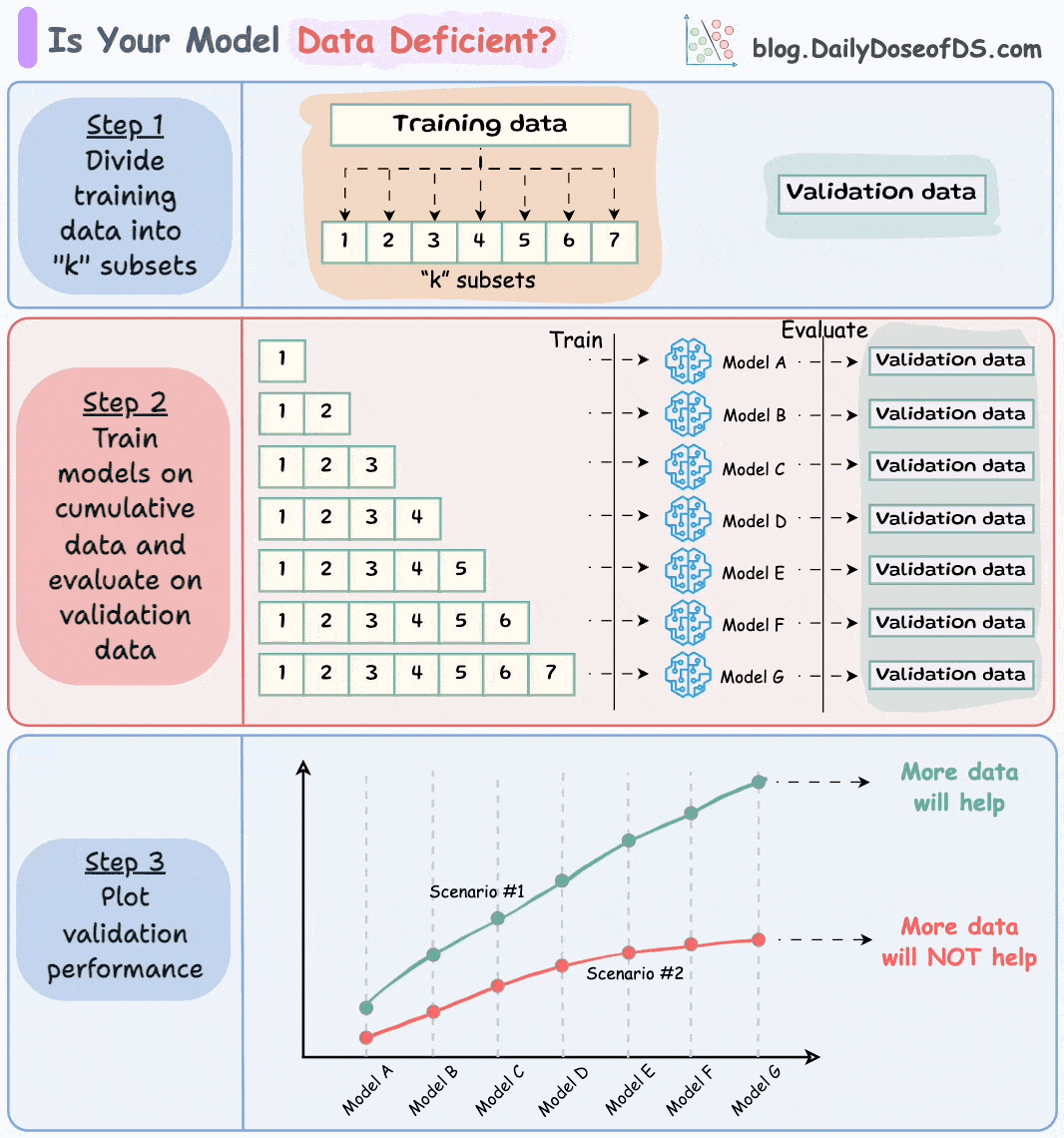
Let’s say this is your full training and validation set:

Divide the training dataset into “k” equal parts. The validation set remains as is.

“k” does not have to be super large.
Usually, a number between 7 to 12 is fine, depending on how much data you have.
Next, train models cumulatively on the above subsets and measure their performance on the validation set:

Train a model on the first subset and evaluate it on the validation set.
Train a model on the first two subsets and evaluate it on the validation set.
Train a model on the first three subsets and evaluate it on the validation set.
And so on…
Plotting the validation performance of these models (in order of increasing training data) will produce one of these two lines:
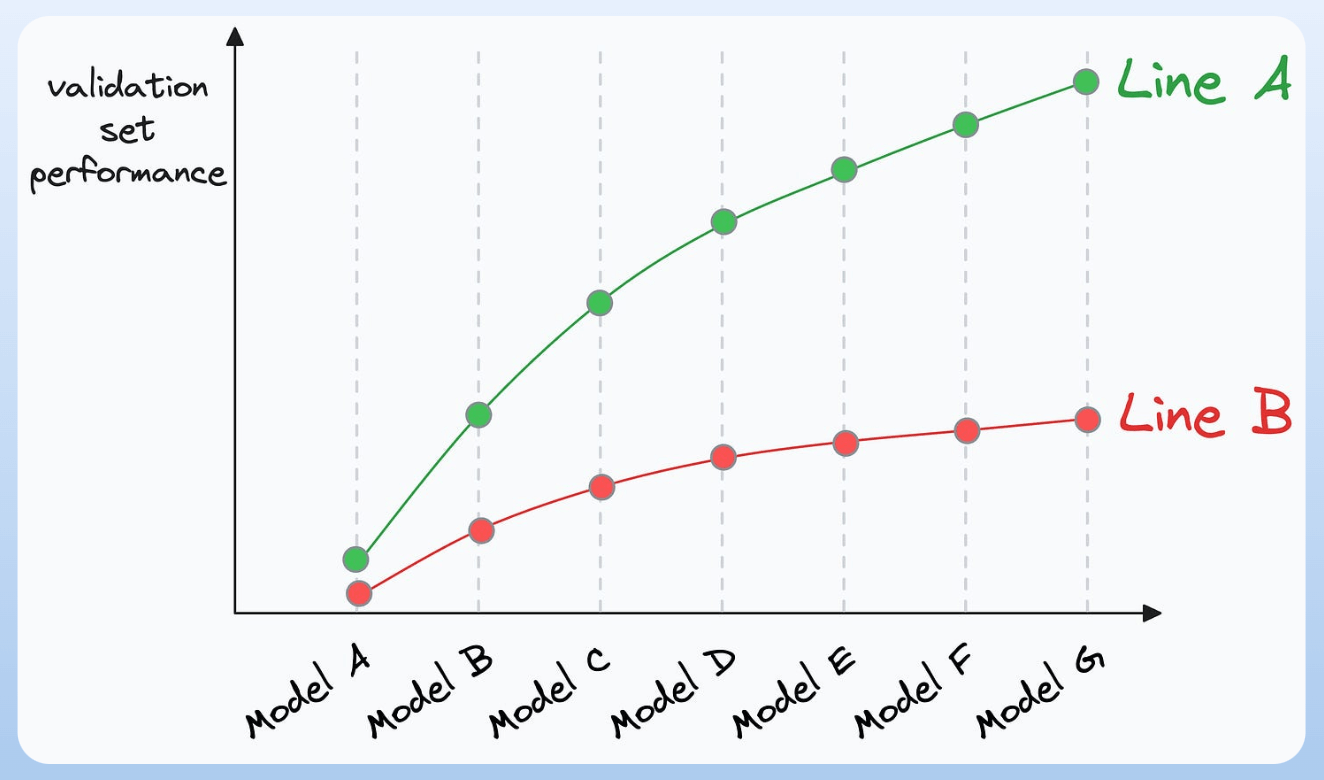
Line A conveys that adding more data will likely increase the model's performance.
Line B conveys that the model's performance has already saturated. Adding more data will most likely not result in any considerable gains.
This way, you can ascertain whether gathering data will help.
Isn’t that simple?
Other than the above technique, I discussed 11 more high-utility techniques to improve ML models in a recent article here: 11 Powerful Techniques To Supercharge Your ML Models.
👉 Over to you: What would you do if you get Line B? How would you proceed ahead?
P.S. For those wanting to develop “Industry ML” expertise:

At the end of the day, all businesses care about impact. That’s it!
Can you reduce costs?
Drive revenue?
Can you scale ML models?
Predict trends before they happen?
We have discussed several other topics (with implementations) in the past that align with such topics.
Here are some of them:
Learn sophisticated graph architectures and how to train them on graph data: A Crash Course on Graph Neural Networks – Part 1.
So many real-world NLP systems rely on pairwise context scoring. Learn scalable approaches here: Bi-encoders and Cross-encoders for Sentence Pair Similarity Scoring – Part 1.
Learn techniques to run large models on small devices: Quantization: Optimize ML Models to Run Them on Tiny Hardware.
Learn how to generate prediction intervals or sets with strong statistical guarantees for increasing trust: Conformal Predictions: Build Confidence in Your ML Model’s Predictions.
Learn how to identify causal relationships and answer business questions: A Crash Course on Causality – Part 1
Learn how to scale ML model training: A Practical Guide to Scaling ML Model Training.
Learn techniques to reliably roll out new models in production: 5 Must-Know Ways to Test ML Models in Production (Implementation Included)
Learn how to build privacy-first ML systems: Federated Learning: A Critical Step Towards Privacy-Preserving Machine Learning.
Learn how to compress ML models and reduce costs: Model Compression: A Critical Step Towards Efficient Machine Learning.
All these resources will help you cultivate key skills that businesses and companies care about the most.
SPONSOR US
Get your product in front of 115,000+ data scientists and machine learning professionals.
Our newsletter puts your products and services directly in front of an audience that matters — thousands of leaders, senior data scientists, machine learning engineers, data analysts, etc., who have influence over significant tech decisions and big purchases.
To ensure your product reaches this influential audience, reserve your space here or reply to this email to ensure your product reaches this influential audience.
Easy way to find out whether we need more data or not. Thanks for sharing